Приветствую! 🙂
Через несколько месяцев я решил вернуться в стиле :). Я заметил, что одно из моих предыдущих сообщений о новом API Date / Time стало очень популярным, поэтому на этот раз я собираюсь посвятить этот пост еще одной новой функции Java 8: лямбда-выражениям .
Функциональное программирование
Лямбда-выражения — это способ, которым язык программирования Java наконец реализует нюансы функционального программирования .
Определение функционального программирования полно противоречий. Вот что википедия говорит нам об этом:
«В информатике функциональное программирование — это парадигма программирования, стиль построения структуры и элементов компьютерных программ, который рассматривает вычисления как оценку математических функций и избегает состояния и изменчивых данных»
Подводя итог, лямбда-выражения позволяют передавать поведение, функции, в качестве аргументов в вызове метода. Это парадигма, немного отличающаяся от той, к которой привыкли Java-программисты, поскольку все это время у нас были только написанные методы, которые принимают объекты в качестве параметров, а не другие методы!
На этой вечеринке платформа Java немного опоздала. Другие языки, такие как Scala, C #, Python и даже Javascript, занимаются этим уже довольно давно. Некоторые люди думают, что, хотя лямбда-выражения позволяют «делать больше с меньшими затратами», это ухудшает читабельность кода. Это утверждение часто использовалось теми, кто не согласился с добавлением лямбд в язык программирования Java. Сам Мартин Фаулер однажды сказал:
«Любой дурак может написать код, понятный компьютеру. Хорошие программисты пишут код, понятный людям ».
Помимо противоречий, есть хотя бы одна веская причина в пользу лямбда-выражений : параллелизм. По мере распространения многоядерных процессоров написание кода, который может легко использовать преимущества параллельной обработки, является обязательным. До Java 8 не было простого способа написания кода, который мог бы легко перебирать большие коллекции объектов параллельно. Как мы увидим дальше, использование Streams позволит нам сделать именно это.
Лямбда против анонимных внутренних классов
Для тех, кто не может сдержать ваше волнение, вот первый вкус. Так называемое «классическое» использование лямбд будет происходить в местах, где вы обычно выбираете анонимные занятия. Если вы задумаетесь об этом, это именно те места, где мы хотели бы передать «поведение», а не состояние (объекты).
В качестве примера я буду использовать Swing API, который большинство из вас, вероятно, уже знают. Фактически, подобные ситуации практически идентичны в любом API GUI, где мы должны обрабатывать пользовательские события: JavaFX, Apache Wicket, GWT и так далее.
Используя Swing , если вы хотите, чтобы какое-то действие происходило, когда пользователь нажимает кнопку, вы должны сделать что-то вроде этого:
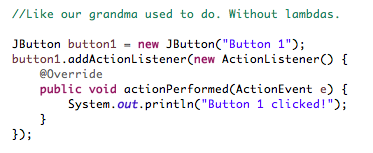
То, что показано на рисунке выше, является одним из наиболее часто используемых способов обработки событий в Java. Однако обратите внимание, что нашим истинным намерением было просто передать поведение в метод addActionListener () , действие кнопки. В итоге мы передали объект (состояние) в качестве аргумента, анонимный ActionListener .
И как можно сделать то же самое, используя лямбды ? Как это:

Как я уже говорил, мы можем «делать больше с меньшими затратами». Мы передали в качестве аргумента методу addActionListener просто действие, которое мы действительно хотели выполнить, во-первых, только поведение. Вся эта суета, необходимая для создания анонимного класса, просто ушла. Детали синтаксиса будут рассмотрены позже, но лямбда-выражение в приведенном выше коде сводится к:
|
1
|
(event) -> System.out.println("Button 2 clicked!") |
Знаю, знаю. Некоторые из вас могут подумать:
«Подожди секундочку! Я был программистом свинга с тех пор, как вышел первый эпизод Dungeon & Dragons , и я никогда не видел обработки событий с одной строкой кода! »
Холод, молодой джедай. Также возможно писать лямбды с ‘n’ строками кода. Но опять же, чем больше код, тем меньше мы получаем разборчивость:
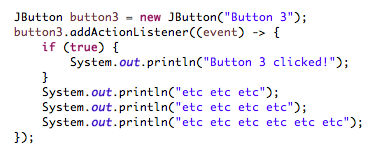
Лично я все еще являюсь частью тех, кто считает, что даже с несколькими утверждениями код выглядит лучше с лямбдами, чем с анонимными классами. Если мы игнорируем отступы, весь синтаксис требует добавления фигурных скобок в качестве разделителей блоков, и каждый оператор получает свой собственный «;»:
|
1
|
(event) -> {System.out.println("First"); System.out.println("Second");} |
Но пока не теряй надежду. Существует еще более чистый способ обработки событий с использованием лямбда-выражений, когда у вас есть несколько операторов. Просто взгляните на фрагмент кода ниже:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
public class MyFrame extends Frame { public MyFrame() { //create the button JButton button5 = new JButton("Button 5"); //"buttonClick()" is a private method of this very class button5.addActionListener(e -> buttonClick(e)); //etc etc etc } private void buttonClick(ActionEvent event) { //multiple statements here }} |
Увидеть? Просто как тот.
@FunctionalInterface
Для написания лямбда-выражения сначала необходим так называемый «функциональный интерфейс» . «Функциональный интерфейс» — это интерфейс Java, который имеет ровно один абстрактный метод . Не забудьте эту часть, «один абстрактный метод». Это потому, что теперь в Java 8 возможно иметь конкретные реализации методов внутри интерфейсов: методы по умолчанию, а также статические методы .
Что касается спецификации, все эти стандартные методы и статические методы, которые вы можете использовать в своем интерфейсе, не учитываются в квоте функционального интерфейса . Если у вас есть 9 стандартных или статических методов и только один абстрактный метод, это все еще концептуально функциональный интерфейс . Чтобы было немного понятнее, есть информативная аннотация @FunctionalInterface , единственная цель которой в жизни — пометить интерфейс как «функциональный». Имейте в виду , что, как это происходит с @Override , его использование просто для демонстрации намерений во время компиляции. Хотя это не является обязательным, я настоятельно рекомендую вам использовать его.
PS: Интерфейс ActionListener, используемый ранее, имеет только один абстрактный метод, который делает его полноценным функциональным интерфейсом.
Давайте создадим простой пример, чтобы усилить синтаксис лямбда-выражений . Представьте, что мы хотим создать API, класс, который будет работать как калькулятор двух операндов типа Double. То есть класс Java с методами суммирования, вычитания, деления и т. Д., Два объекта типа Double:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
public class Calculator { public static Double sum(Double a, Double b) { return a + b; } public static Double subtract(Double a, Double b) { return a - b; } public static Double multiply(Double a, Double b) { return a * b; } //etc etc etc...} |
Чтобы использовать этот калькулятор «прямо из НАСА», клиенты API просто вызовут любой из статических методов:
|
1
|
Double result = Calculator.sum(200, 100); //300 |
Этот подход, однако, имеет некоторые проблемы. Программирование всех возможных операций между двумя объектами типа Double было бы практически невозможно. Вскоре нашим клиентам понадобятся менее распространенные операции, такие как квадратный корень или что-то еще. И вы, владелец этого API, будете порабощены навсегда.
Разве не было бы замечательно, если бы наш калькулятор был достаточно гибким, чтобы клиенты могли сами сообщать, какой тип математической операции они хотели бы использовать? Чтобы достичь этой цели, давайте сначала создадим функциональный интерфейс под названием DoubleOperator :
|
1
2
3
4
5
6
|
@FunctionalInterfacepublic interface DoubleOperator { public Double apply(Double a, Double b);} |
Наш интерфейс определяет контракт, по которому выполняются операции над двумя объектами типа Double, который также возвращает Double. Точная операция будет оставлена на усмотрение клиентов.
Теперь классу Calculator нужен только один метод, который принимает два операнда Double в качестве параметров и лямбда-выражение , которое позволит нашим клиентам сообщать, какую операцию они хотят:
|
1
2
3
4
5
6
7
|
public class Calculator { public static Double calculate(Double op1, Double op2, DoubleOperator operator) { return operator.apply(op1, op2); //delegate to the operator }} |
Наконец, вот как наши клиенты будут вызывать методы нашего нового API:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
//sum Double result1 = Calculator.calculate(30d, 70d, (a, b) -> a + b);System.out.println(result1); //100.0 //subtractDouble result2 = Calculator.calculate(200d, 50d, (a, b) -> a - b);System.out.println(result2); // 150.0 //multiplyDouble result3 = Calculator.calculate(5d, 5d, (a, b) -> a * b);System.out.println(result3); // 25.0 //find the smallest operand using a ternary operatorDouble result4 = Calculator.calculate(666d, 777d, (a, b) -> a > b ? b : a);System.out.println(result4); //666.0 |
Небо сейчас предел. Клиенты могут вызывать метод Calculate () с любой идеей, которая приходит на ум. Все, что им нужно сделать, это придумать правильное лямбда-выражение .
Лямбда имеет разделы, разделенные символом ‘->’. Левый раздел предназначен только для объявления параметров. Правый раздел обозначает саму реализацию метода:

Обратите внимание, что в левой части есть только объявление параметров, которые соответствуют подписи DoubleOperator.apply (Double a, Double b) . Тип параметра может быть определен компилятором, и большую часть времени не нужно информировать. Аналогично, имена переменных параметров могут быть любыми, но не обязательно «a» и «b», как подпись нашего функционального интерфейса :
|
1
2
3
4
5
6
|
//sum with explicit typesDouble result1 = Calculator.calculate(30d, 70d, (Double x, Double y) -> x + y); //another wayOperadorDouble operator = (Double op1, Double op2) -> op1 + op2;Double result2 = Calculator.calculate(30d, 70d, operador); |
Когда сигнатура метода вашего функционального интерфейса не имеет каких-либо параметров, все, что вам нужно сделать, это поместить пустой «()» . Это можно увидеть с помощью интерфейса Runnable :
|
1
2
|
/* The r variable can be passed to any method that takes a Runnable */Runnable r = () -> System.out.println("Lambda without parameter"); |
Просто из любопытства я покажу альтернативный синтаксис, который также может быть использован для объявления лямбда-выражений , известного как Method Reference . Я не буду вдаваться в подробности, иначе мне понадобится целая книга для этого поста. Это обеспечивает еще более чистый способ, когда все ваше выражение хочет сделать вызов метода:
|
1
2
3
4
5
6
7
|
JButton button4 = new JButton("Button 4"); //thisbutton4.addActionListener(ActionEvent::getSource); //is equivalent to thisbutton4.addActionListener((event) -> event.getSource()); |
Не изобретай колесо
Прежде чем двигаться дальше, давайте сделаем небольшую паузу, чтобы вспомнить этот старый жаргон, который мы все знаем. Это означает, что в Java 8 API уже есть тонны функциональных интерфейсов, которые могут нам понадобиться в нашей повседневной работе. В том числе тот, который может прекрасно устранить наш интерфейс DoubleOperator .
Все эти интерфейсы находятся внутри пакета java.util.function , и основными из них являются:
| название | параметры | Возвращение | пример |
|---|---|---|---|
| BinaryOperator <Т> | (T, T) | T | Произведите любую операцию между двумя объектами одного типа. |
| Потребитель <T> | T | недействительным | Распечатать значение. |
| Функция <T, R> | T | р | Возьмите объект типа Double и верните его как String. |
| Предиката <Т> | T | логический | Выполнение любого вида теста для объекта, переданного в качестве параметра: oneString.endsWith («суффикс») |
| Поставщик <T> | — | T | Выполнение операции, которая не принимает никаких параметров, но имеет возвращаемое значение. |
Это не так. Все остальные — только варианты упомянутых выше. Достаточно скоро, когда мы увидим использование Streams, у нас будет возможность увидеть большинство из них в действии, и будет намного легче уместить всю картину. Однако мы можем провести рефакторинг нашего класса Calculator и заменить наш старый интерфейс DoubleOperator на интерфейс, уже предоставленный в JDK, BinaryOperator :
|
1
2
3
4
5
6
7
|
public class Calculator { public static <T> T calculate(T op1, T op2, BinaryOperator<T> operator) { return operator.apply(op1, op2); }} |
Для наших клиентов мало что изменится, за исключением того факта, что интерфейс BinaryOperator имеет параметризованные типы, обобщенные типы, и теперь наш калькулятор стал еще более гибким, поскольку мы можем выполнять математические операции между двумя объектами любого типа, а не просто Doubles :
|
1
2
|
//sum integersInteger result1 = Calculator.calculate(5, 5, (x, y) -> x + y); |
Коллекции и потоки
Как разработчики, мы, вероятно, тратим большую часть нашего времени на использование сторонних API, а не на создание собственных. И это то, чего мы достигли в этой статье, и увидели, как мы можем использовать лямбда-выражения в наших собственных API.
Однако пришло время проанализировать некоторые изменения, внесенные в основные API Java, которые позволяют нам использовать лямбда-выражения при манипулировании коллекциями. Для иллюстрации наших примеров мы будем использовать простой класс Person , который имеет имя , возраст и пол («M» для мужчины и «F» для женщины):
|
1
2
3
4
5
6
7
8
|
public class Person { private String name; private Integer age; private String sex; //M or F //gets and sets} |
Все примеры впереди требуют коллекций объектов, поэтому представьте, что у нас есть коллекция объектов типа Person :
|
1
|
List<Person> persons = thisMethodReturnsPersons(); |
Мы начнем с нового метода stream (), который был добавлен в интерфейс Collection . Поскольку все коллекции «расширяют» коллекцию , все коллекции Java унаследовали этот метод:
|
1
2
|
List<Person> persons = thisMethodReturnsPersons();Stream<Person> stream = persons.stream(); //a stream of person objects |
Несмотря на это, кажется, что интерфейс Stream — это не просто еще один обычный тип коллекции. Поток — это скорее абстракция «потока данных», которая позволяет нам преобразовывать или манипулировать его данными. В отличие от коллекций, которые мы уже знаем, Stream не разрешает прямой доступ к его элементам (нам нужно преобразовать Stream обратно в Collection ).
Для сравнения давайте посмотрим, как будет выглядеть наш код, если мы посчитаем, сколько женских объектов у нас в нашей коллекции людей. Во-первых, без потоков :
|
1
2
3
4
5
6
7
|
long count = 0;List<Person> persons = thisMethodReturnsPersons();for (Person p : persons) { if (p.getSex().equals("F")) { count++; }} |
Используя цикл for, мы создаем счетчик, который увеличивается каждый раз, когда встречается женщина. Подобные коды мы делали сотни раз.
Теперь то же самое, используя поток :
|
1
2
|
List<Person> persons = thisMethodReturnsPersons();long count = persons.stream().filter(person -> person.getSex().equals("F")).count(); |
Намного чище, не правда ли? Все начинается с вызова метода stream () , все остальные вызовы связаны друг с другом, так как большинство методов в интерфейсе Stream были разработаны с учетом паттерна Builder . Для тех, кто не привык к таким цепочкам методов, может быть проще визуализировать так:
|
1
2
3
4
|
List<Person> persons = thisMethodReturnsPersons();Stream<Person> stream = persons.stream();stream = stream.filter(person -> person.getSex().equals("F"));long count = stream.count(); |
Давайте сосредоточим наше внимание на двух методах потока, которые мы использовали, filter () и count () .
Фильтр () принимает условие, по которому мы хотим фильтровать нашу коллекцию. И это условие представлено лямбда-выражением, которое принимает один параметр и возвращает логическое значение :
|
1
|
person -> person.getSex().equals("F") |
Не случайно, функциональный интерфейс, используемый для представления этого выражения, параметр метода filter () , является интерфейсом Predicate . У нее есть только один абстрактный метод, булев тест (T t) :
|
1
2
3
4
5
6
7
|
@FunctionalInterfacepublic interface Predicate<T> { boolean test(T t); //non abstract methods here} |
Параметризованный тип T представляет тип элемента нашего потока , то есть объектов Person. Таким образом, получается, что наше лямбда-выражение реализует метод test () следующим образом:
|
1
2
3
4
5
6
7
|
boolean test(Person person) { if (person.getSex().equals("F")) { return true; } else { return false; }} |
После фильтрации остается только вызвать метод count () . В этом нет ничего особенного, он просто подсчитывает, сколько объектов мы оставили в нашем потоке после фильтрации (у нас могло бы быть гораздо больше вещей, кроме простой фильтрации). Метод count () считается «терминальной операцией», и после его вызова поток считается «потребленным» и больше не может использоваться.
Давайте посмотрим на некоторые другие методы интерфейса Stream .
собирать ()
Метод collect () часто используется для выполнения изменяемого сокращения потока (для получения подробной информации перейдите по ссылке). Обычно это означает преобразование потока обратно в обычную коллекцию. Обратите внимание, что, как и метод count (), метод collect () также является «терминальной операцией» !
Предположим небольшую вариацию нашего последнего примера, где мы хотели отфильтровать только женские объекты из нашей коллекции людей. Однако на этот раз мы не собираемся просто фильтровать самку ( filter () ), а затем считать их ( count () ). Мы собираемся физически разделить все женские объекты в совершенно другой коллекции, которая будет содержать только женщин:
|
01
02
03
04
05
06
07
08
09
10
11
|
List<Person> persons = thisMethodReturnsPersons(); //creating a List with females onlyList<Person> listFemales = persons.stream() .filter(p -> p.getSex().equals("F")) .collect(Collectors.toList()); //creating a Set with females onlySet<Person> setFemales = persons.stream() .filter(p -> p.getSex().equals("F")) .collect(Collectors.toSet()); |
Фильтрующая часть остается прежней, единственное отличие — это вызов метода collect () в конце. Как видим, этот вызов принимает аргумент и объект типа Collector .
Для создания объекта типа Collector требуется небольшая работа, поэтому, к счастью, есть класс, который позволяет нам создавать их более удобным образом, встречая класс Collectors (множественное число). Как показано в Collectors.toList () и Collectors.toSet () . Несколько интересных примеров:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
//We can choose the specific type of collection we want//by using Collectors.toCollection(). //another way for building a StreamStream<String> myStream = Stream.of("a", "b", "c", "d"); //transforming into a LinkedList (using method reference)LinkedList<String> linkedList = myStream.collect(Collectors.toCollection(LinkedList::new)); //transforming into a TreeSetStream<String> s1 = Stream.of("a", "b", "c", "d");TreeSet<String> t1 = s1.collect(Collectors.toCollection( () -> new TreeSet<String>() )); //using method reference, the same would be accomplished like thisStream<String> s2 = Stream.of("a", "b", "c", "d");TreeSet<String> t2 = s2.collect(Collectors.toCollection( TreeSet::new )); |
Обратите внимание, как метод Collectors.toCollection () принимает лямбда-выражение типа Supplier .
Функциональный интерфейс Supplier предоставляет единственный абстрактный метод T get () , который не принимает никаких параметров и возвращает один объект. Вот почему наше выражение было просто вызовом конструктора коллекции, который мы хотели использовать:
|
1
|
() -> new TreeSet<String>() |
карта()
Метод map () довольно прост. Его можно использовать, когда вы хотите преобразовать каждый элемент одной коллекции в объект другого типа, то есть сопоставить каждый элемент коллекции с элементом другого типа.
Продвинув наш пример на шаг вперед, давайте попробуем следующий сценарий: учитывая коллекцию объектов Person, давайте получим совершенно другую коллекцию, которая содержит имена только наших женских объектов в виде строк, все заглавными буквами. Подводя итог, помимо использования filter () и collect () для разделения всех наших женских объектов в их собственной коллекции, мы также собираемся использовать метод map () для преобразования каждого женского объекта Person в его представление String (имя в верхнем регистре) ):
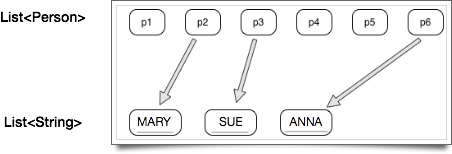
И вот код:
|
1
2
3
4
5
6
|
List<Person> persons = thisMethodReturnsPersons(); List<String> names = persons.stream() .filter(p -> p.getSex().equals("F")) .map(p -> p.getName().toUpperCase()) .collect(Collectors.toList()); |
Функциональным интерфейсом, использованным в качестве параметра для метода map (), был Function , чей единственный абстрактный метод R apply (T t) принимает объект в качестве параметра и возвращает объект другого типа. Именно в этом и заключается map () : взять Person и превратить в String .
forEach () & forEachOrdered ()
Возможно, самые простые из всех, forEach () и forEachOrdered () предоставляют средства для посещения каждого элемента в потоке , например, для печати каждого элемента в консоли при их обнаружении. Основное различие между ними состоит в том, что первое не гарантирует «порядок встречи», а второе — гарантирует.
Если поток обладает или не имеет «порядка встречи», зависит от коллекции, которая его создала, а также от выполняемых в нем промежуточных операций. Потоки, происходящие из списка, имеют определенный порядок, как и ожидалось.
На этот раз функциональным интерфейсом является Consumer , чей абстрактный метод void accept (T t) принимает один параметр и ничего не возвращает:
|
1
2
3
4
5
6
7
|
List<Person> persons = thisMethodReturnsPersons(); //print without any "encounter order" guaranteepersons.stream().forEach(p -> System.out.println(p.getName())); //print in the correct order if possiblepersons.stream().forEachOrdered(p -> System.out.println(p.getName())); |
Помните, что forEach () и forEachOrdered () также являются терминальными операциями ! (вам не нужно знать это наизусть, просто посмотрите это в javadocs, когда это необходимо)
мин Макс()
Найти минимальный и максимальный элемент коллекции также стало намного проще с помощью лямбда-выражений . Используя обычные алгоритмы, это простая и действительно раздражающая процедура.
Давайте возьмем нашу коллекцию объектов Person и найдем в ней самого молодого и самого старого человека:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
List<Person> persons = thisMethodReturnsPersons(); //youngest using min()Optional<Person> youngest = persons.stream() .min((p1, p2) -> p1.getAge().compareTo(p2.getAge())); //oldest using max()Optional<Person> oldest = persons.stream() .max((p1, p2) -> p1.getAge().compareTo(p2.getAge())); //printing their ages in the consoleSystem.out.println(youngest.get().getAge());System.out.println(oldest.get().getAge()); |
Методы min () и max () также принимают функциональный интерфейс в качестве параметра, только этот не нов: Comparator . ( ps : если вы читаете эту статью и не знаете, что такое «компаратор», я предлагаю сделать шаг назад и попытаться изучить основы java перед тем, как повеселиться с лямбдами)
В приведенном выше коде есть еще кое-что, чего мы еще не видели, класс Optional . Это также новая функция в Java 8, и я не буду вдаваться в подробности об этом. Если вам интересно, просто перейдите по этой ссылке.
Тот же результат может быть достигнут с помощью нового статического метода Comparator.comparing () , который принимает функцию и выступает в качестве утилиты для создания компараторов :
|
1
2
3
4
5
|
//min()Optional<Person> youngest = persons.stream().min(Comparator.comparing(p -> p.getAge())); //max()Optional<Person> oldest = persons.stream().max(Comparator.comparing(p -> p.getAge())); |
Еще немного о коллекциях () и коллекционерах
Использование метода collect () позволяет нам делать некоторые действительно интересные манипуляции вместе с помощью некоторых встроенных коллекторов .
Например, можно рассчитать средний возраст всех наших объектов Person:
|
1
2
3
4
5
|
List<Person> persons = thisMethodReturnsPersons(); Double average = persons.stream().collect(Collectors.averagingDouble(p -> p.getAge())); System.out.println("A average is: " + average); |
В классе Collectors есть 3 метода, которые могут помочь нам в этом направлении, каждый из которых зависит от типа данных:
- Collectors.averagingInt () (целые числа)
- Collectors.averagingLong () (longs)
- Collectors.averagingDouble () (doubles)
Все эти методы возвращают допустимый Collector, который может быть передан в качестве аргумента для collect () .
Другая интересная возможность — это возможность разделить коллекцию, поток , на две коллекции значений. Мы уже делали нечто подобное, когда создавали новую коллекцию исключительно для наших женских объектов Person, однако в нашей оригинальной коллекции все еще содержались как женские, так и мужские объекты. Что, если мы хотим разделить оригинальную коллекцию на две новые: одну только с мужчинами, а другую с женщинами?
Чтобы это произошло, мы будем использовать Collectors.partitioningBy () :
|
01
02
03
04
05
06
07
08
09
10
11
|
List<Person> persons = thisMethodReturnsPersons(); //a Map Boolean -> List<Person>Map<Boolean, List<Person>> result = persons.stream() .collect(Collectors.partitioningBy(p -> p.getSex().equals("M"))); //males stored with the 'true' keyList<Person> males = result.get(Boolean.TRUE); //females stored with the 'false' keyList<Person> females = result.get(Boolean.FALSE); |
Показанный выше метод Collectors.partitioningBy () работает путем создания карты с двумя элементами, один из которых хранится с ключом «истина», а другой с ключом «ложь» . Поскольку он использует функциональный интерфейс типа Predicate , возвращение которого является логическим значением , элементы, выражение которых оценивается как «true», попадают в коллекцию «true» , а те, кто оценивает как «false», переходят в коллекцию «false» .
Чтобы покончить с этим, давайте представим еще один сценарий, в котором мы можем сгруппировать все наши объекты Person по возрасту. Похоже, что мы сделали с Collectors.partitioningBy (), за исключением того, что на этот раз это не простое условие истина / ложь , это будет условие, определяемое нами, возраст.
Кусок пирога, мы просто используем Collectors.groupingBy () :
|
1
2
3
|
//Map "Age" -> "List<Person>"Map<Integer, List<Person>> result = persons.stream() .collect(Collectors.groupingBy(p -> p.getAge())); |
Как бы вы сделали это без лямбд ? Дает мне головную боль только думать об этом.
Производительность и параллелизм
В начале этой статьи я упомянул, что одним из преимуществ использования лямбда-выражений является возможность параллельного манипулирования коллекциями, и это то, что я собираюсь показать далее. Удивительно, но показать особо нечего. Все, что нам нужно сделать, чтобы превратить весь наш предыдущий код в «параллельную обработку», это изменить один вызов метода:
|
1
2
3
4
5
6
7
|
List<Person> persons = thisMethodReturnsPersons(); //sequential Stream<Person> s1 = persons.stream(); //parallelStream<Person> s2 = persons.parallelStream(); |
Вот и все. Просто измените вызов stream () для функции ParallelsStream (), и параллельная обработка будет иметь место. Все остальные вызовы метода остаются неизменными.
Чтобы продемонстрировать разницу в использовании параллельной обработки, я сделал тест, используя наш последний пример кода, где мы сгруппировали все объекты Person по возрасту. Принимая во внимание тестовые данные 20 миллионов объектов, вот что мы получили:
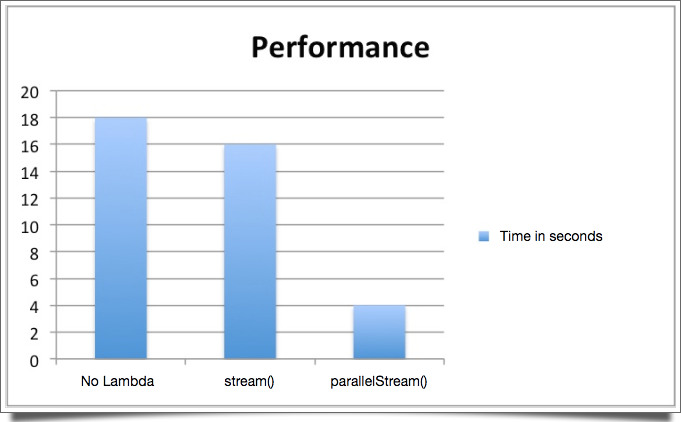
Если мы сравним путь «старой школы» без лямбд с последовательной лямбда- обработкой stream () , мы можем сказать, что это ничья. С другой стороны, функцияrallelStream () оказалась в три раза быстрее. Всего 4 секунды. Это разница в 300%.
ВНИМАНИЕ: Это никоим образом не означает, что вы должны выполнять всю свою обработку параллельно!
Помимо очевидного факта, что мои тесты слишком упрощены для того, чтобы их можно было рассматривать вслепую, важно учесть, прежде чем выбрать параллельную обработку, что присущи параллелизму: коллекция разбивается на несколько коллекций, а затем снова объединяется, чтобы сформировать конечный результат ,
Тем не менее, если нет относительно большого количества элементов, стоимость параллельной обработки, вероятно, не окупится. Тщательно проанализируйте, прежде чем использовать ParallelsStream () без разбора.
Ну, я думаю, это все. Конечно, охватить все невозможно, это займет целую книгу, но я думаю, что здесь было показано много важных аспектов. Оставьте комментарий, если вам есть что сказать.
Удачного кодирования!
| Ссылка: | Учебное пособие по лямбда-выражениям Java 8 от нашего партнера по JCG Родриго Учоа из Code to live. Живи к коду. блог. |