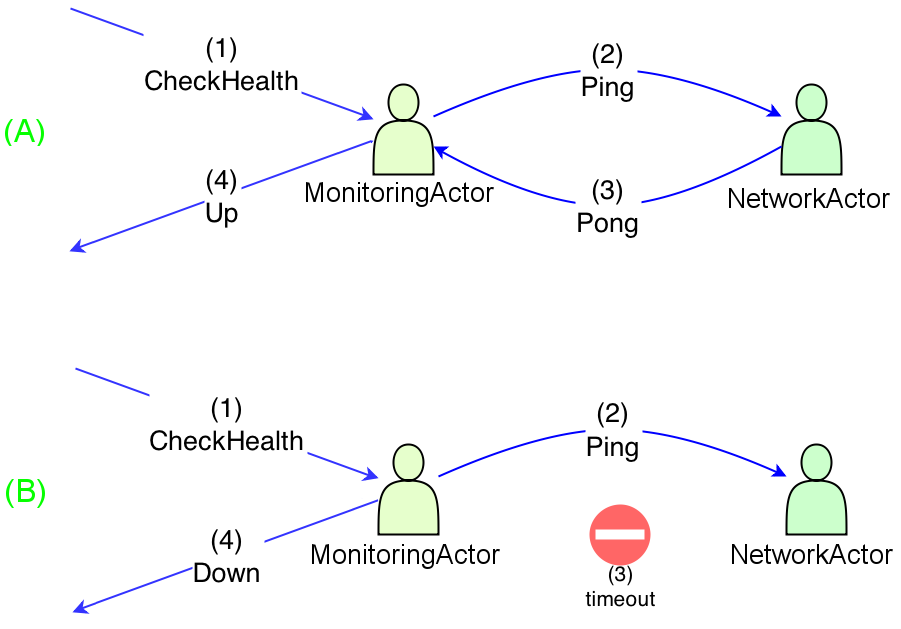
Представьте себе простую систему актеров Akka, состоящую из двух сторон: MonitoringActor и NetworkActor . Всякий раз, когда кто-то ( клиент ) отправляет CheckHealth первому, он запрашивает второе, отправляя Ping . NetworkActor обязан ответить Pong как можно скорее (сценарий [A]). Как только MonitoringActor получает такой ответ, он немедленно отвечает клиенту сообщением о состоянии Up . Однако MonitoringActor обязан отправить ответ Down если NetworkActor не смог ответить Pong течение одной секунды (сценарий [B]). Оба рабочих процесса изображены ниже:
По-видимому, есть как минимум три способа реализации этой простой задачи в Akka, и мы изучим их плюсы и минусы.
Обычный актер
В этом сценарии MonitoringActor прослушивает Pong напрямую без посредников:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
class MonitoringActor extends Actor with ActorLogging { private val networkActor = context.actorOf(Props[NetworkActor], "network") private var origin: Option[ActorRef] = None def receive = { case CheckHealth => networkActor ! Ping origin = Some(sender) case Pong => origin.foreach(_ ! Up) origin = None }} |
Реализация NetworkActor имеет значения, просто предположите, что он отвечает Pong для каждого Ping . Как вы можете видеть, MonitoringActor обрабатывает два сообщения: CheckHealth отправленное клиентом, и Pong предположительно, отправленный NetworkActor . К сожалению, нам пришлось хранить ссылку на клиента в поле источника, потому что в противном случае она была бы потеряна после обработки CheckHealth . Итак, мы добавили немного государства. Реализация довольно проста, но имеет довольно много проблем:
- Последующее
CheckHealthперезапишет предыдущееorigin -
CheckHealthне должно быть разрешено при ожиданииPong - Если
Pongникогда не прибудет, мы останемся в противоречивом состоянии - … Потому что у нас еще нет условия ожидания 1 секунды
Но прежде чем мы реализуем условие тайм-аута, давайте немного реорганизовать наш код, чтобы сделать состояние более явным и безопасным для типов:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
class MonitoringActor extends Actor with ActorLogging { private val networkActor = context.actorOf(Props[NetworkActor], "network") def receive = waitingForCheckHealth private def waitingForCheckHealth: Receive = { case CheckHealth => networkActor ! Ping context become waitingForPong(sender) } private def waitingForPong(origin: ActorRef): Receive = { case Pong => origin ! Up context become waitingForCheckHealth }} |
context.become() позволяет изменить поведение актера на лету . В нашем случае мы либо ждем CheckHealth или Pong — но никогда не оба. Но куда делось государство (ссылка на источник)? Ну, это ловко спрятано. waitingForPong() принимает origin качестве параметра и возвращает функцию PartialFunction . Эта функция закрывает этот параметр, поэтому глобальная переменная actor больше не нужна. Хорошо, теперь мы готовы реализовать 1-секундный тайм-аут при ожидании Pong :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
def receive = waitingForCheckHealth private def waitingForCheckHealth: Receive = { case CheckHealth => networkActor ! Ping implicit val ec = context.dispatcher val timeout = context.system.scheduler. scheduleOnce(1.second, self, Down) context become waitingForPong(sender, timeout)} private def waitingForPong(origin: ActorRef, timeout: Cancellable): Receive = LoggingReceive { case Pong => timeout.cancel() origin ! Up context become receive case Down => origin ! Down context become receive} |
После отправки Ping мы немедленно планируем отправку сообщения « Down себе примерно через одну секунду. Тогда мы идем в waitingForPong . Если Pong прибывает, мы отменяем запланированный Down и отправляем Up . Однако, если мы впервые получили Down это означает, что истекла одна секунда. Итак, мы пересылаем Down обратно к клиенту. Это только у меня или может быть такая простая задача не требует такого количества кода?
Кроме того, обратите внимание, что наш MonitoringActor не способен обрабатывать более одного клиента одновременно. После получения CheckHealth клиентам больше не разрешено, пока не будет отправлено сообщение « Up или « Down . Кажется довольно ограничивающим.
Составление фьючерсов
Другой подход к той же самой проблеме — использование модели спроса и будущего. Внезапно код становится намного короче и легче для чтения:
|
01
02
03
04
05
06
07
08
09
10
|
def receive = { case CheckHealth => implicit val timeout: Timeout = 1.second implicit val ec = context.dispatcher val origin = sender networkActor ? Ping andThen { case Success(_) => origin ! Up case Failure(_) => origin ! Down }} |
Это оно! Мы запрашиваем networkActor , отправляя Ping а затем, когда приходит ответ, мы отвечаем клиенту. В случае Success(_) ( _ заполнитель означает Pong но нам все равно) мы отправляем Up . Если это был Failure(_) (где _ наиболее вероятно содержит AskTimeout брошенный через одну секунду без ответа), мы пересылаем Down . В этом коде есть одна огромная ловушка. И в обратном вызове, и в успешном, и в случае неудачи мы не можем использовать sender напрямую, потому что этот фрагмент кода может быть выполнен гораздо позже другим потоком. Значение sender является кратковременным, и к тому времени, когда Pong прибудет, это может указывать на любого другого актера, который случайно отправил нам что-то. Таким образом, мы должны сохранить оригинального sender в локальной переменной источника и перехватить его вместо этого.
Если вас это раздражает, вы можете поиграть с pipeTo :
|
1
2
3
4
5
6
7
8
|
def receive = LoggingReceive { case CheckHealth => implicit val ec = context.dispatcher networkActor.ask(Ping)(1.second). map{_ => Up}. recover{case _ => Down}. pipeTo(sender)} |
То же, что и раньше, мы ask (синоним ? networkActor ) networkActor с тайм-аутом. Если получен правильный ответ, мы сопоставляем его с Up . Если вместо этого будущее заканчивается исключением, мы восстанавливаемся из него, сопоставляя его с сообщением « Down . Независимо от того, какая «ветка» была использована, результат передается sender .
Вы должны задать себе вопрос: почему приведенный выше код подходит, несмотря на использование sender то время как предыдущий был бы поврежден? Если вы внимательно посмотрите на объявления, вы заметите, что pipeTo() принимает ActorRef по значению, а не по имени. Это означает, что sender вычисляется сразу при выполнении выражения, а не позже, когда возвращаются ответы. Мы идем по тонкому льду здесь, поэтому, пожалуйста, будьте осторожны, делая такие предположения.
Выделенный актер
Актеры легкие, так почему бы не создать один только для проверки здоровья? Этот удаленный субъект будет отвечать за связь с NetworkActor и отправку ответа клиенту. Единственной обязанностью MonitoringActor будет создание экземпляра этого единовременного субъекта:
|
1
2
3
4
5
6
7
8
|
class MonitoringActor extends Actor with ActorLogging { def receive = { case CheckHealth => context.actorOf(Props(classOf[PingActor], networkActor, sender)) } } |
PingActor довольно прост и похож на самое первое решение:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
class PingActor(networkActor: ActorRef, origin: ActorRef) extends Actor with ActorLogging { networkActor ! Ping context.setReceiveTimeout(1.second) def receive = { case Pong => origin ! Up self ! PoisonPill case ReceiveTimeout => origin ! Down self ! PoisonPill }} |
Когда актер создан, мы отправляем Ping в NetworkActor но также планируем сообщение о тайм-ауте. Теперь мы ждем либо Pong либо тайм-аута Down . В обоих случаях мы в конечном итоге PingActor потому что PingActor больше не нужен. Конечно, MonitoringActor может создавать несколько независимых NetworkActor одновременно.
Это решение сочетает в себе простоту и чистоту первого, но надежно как второе. Конечно, это также требует большей части кода. Вам решать, какую технику вы используете в реальных случаях использования. Кстати, после написания этой статьи я натолкнулся на актеров Ask, Tell и Per-request, которые касаются одной и той же проблемы и вводят аналогичные подходы. Определенно посмотрите и на это!