Было много ажиотажа по поводу модного слова « масштабирование сети », и люди проходят через многие этапы реорганизации архитектуры своих приложений, чтобы заставить свои системы «масштабироваться».
Но что такое масштабирование, и как мы можем быть уверены, что можем масштабировать?
Различные аспекты масштабирования
Упомянутый выше обман главным образом связан с масштабированием нагрузки , то есть для того, чтобы система, которая работает на 1 пользователя, также работала хорошо для 10 пользователей, или 100 пользователей, или миллионов. В идеале ваша система должна быть как можно более «не имеющей состояния», чтобы оставшиеся несколько состояний могли быть перенесены и преобразованы на любом процессоре в вашей сети. Когда загрузка является вашей проблемой, задержка, вероятно, нет, поэтому все в порядке, если отдельные запросы занимают 50-100 мс. Это часто также называют масштабированием
Абсолютно другой аспект масштабирования связан с масштабированием производительности , т. Е. Чтобы убедиться, что алгоритм, который работает для 1 фрагмента информации, также будет хорошо работать для 10 частей, или 100 частей, или миллионов. Реализуется ли этот тип масштабирования лучше всего в Big O Notation . Задержка является убийцей при масштабировании производительности. Вы хотите сделать все возможное, чтобы сохранить все расчеты на одной машине. Это часто также называют расширением
Если бы было что-то вроде бесплатного ланча ( нет ), мы могли бы бесконечно комбинировать масштабирование. Во всяком случае, сегодня мы рассмотрим несколько очень простых способов улучшить ситуацию с точки зрения производительности.
Обозначение Big O
Java 7 ForkJoinPool а также параллельный Stream Java 8 помогают распараллеливать вещи, что прекрасно, когда вы развертываете свою программу Java на многоядерном процессоре. Преимущество такого параллелизма по сравнению с масштабированием между различными машинами в сети заключается в том, что вы можете почти полностью устранить эффекты задержки, поскольку все ядра могут получать доступ к одной и той же памяти.
Но не обманывайтесь эффектом параллелизма! Помните следующие две вещи:
- Параллелизм пожирает ваши ядра. Это отлично подходит для пакетной обработки, но кошмар для асинхронных серверов (таких как HTTP). Есть веские причины, по которым мы использовали однопоточную модель сервлета в последние десятилетия. Так что параллелизм помогает только при расширении.
- Параллелизм не влияет на нотацию Big O вашего алгоритма. Если ваш алгоритм
O(n log n), и вы позволяете этому алгоритму работать наcядрах, у вас все равно будет алгоритмO(n log n / c), так какcявляется незначительной константой сложности вашего алгоритма. Вы сэкономите время настенных часов, но не уменьшите сложность!
Конечно, лучший способ повысить производительность — это уменьшить сложность алгоритма. Убийца — это достижение O(1) или квази- O(1) , например, поиск HashMap . Но это не всегда возможно, не говоря уже о легкости.
Если вы не можете уменьшить свою сложность, вы все равно можете получить большую производительность, если вы настроите свой алгоритм там, где это действительно важно, если сможете найти правильные места. Предположим следующее визуальное представление алгоритма:
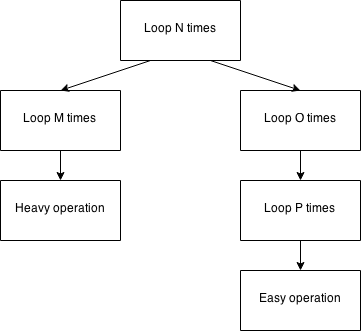
Общая сложность алгоритма составляет O(N 3 ) или O(N x O x P) если мы хотим иметь дело с отдельными порядками величины. Однако при профилировании этого кода вы можете найти забавный сценарий:
- В вашем блоке разработки левая ветвь (
N -> M -> Heavy operation) — единственная ветвь, которую вы можете видеть в своем профилировщике, поскольку значенияOиPв данных примера разработки малы. - На производстве, однако, правильная ветвь (
N -> O -> P -> Easy operationили также NOPE ) действительно вызывает проблемы. Ваша рабочая группа могла бы выяснить это с помощью AppDynamics , DynaTrace или какого-либо подобного программного обеспечения.
Без производственных данных вы можете быстро сделать выводы и оптимизировать «тяжелую работу». Вы отправляете в производство, и ваше исправление не имеет никакого эффекта.
Не существует золотых правил для оптимизации, кроме фактов, которые:
- Хорошо спроектированное приложение гораздо проще оптимизировать
- Преждевременная оптимизация не решит никаких проблем с производительностью, но сделает ваше приложение менее разработанным, что, в свою очередь, затруднит оптимизацию.
Достаточно теории. Давайте предположим, что вы нашли правильную ветвь, чтобы быть проблемой. Вполне может быть, что очень простое действие взрывается при производстве, потому что оно вызывается много раз (если N , O и P большие). Пожалуйста, прочтите эту статью в контексте проблемы на конечном узле неизбежного алгоритма O(N 3 ) . Эти оптимизации не помогут вам масштабироваться. Они помогут вам сэкономить день вашего клиента, отложив сложное улучшение общего алгоритма на потом!
Вот 10 самых простых оптимизаций производительности в Java:
1. Используйте StringBuilder
Это должно быть по умолчанию почти во всем коде Java. Старайтесь избегать оператора + . Конечно, вы можете утверждать, что это просто синтаксический сахар для StringBuilder любом случае, как в:
|
1
|
String x = "a" + args.length + "b"; |
… который компилируется в
|
01
02
03
04
05
06
07
08
09
10
11
|
0 new java.lang.StringBuilder [16] 3 dup 4 ldc <String "a"> [18] 6 invokespecial java.lang.StringBuilder(java.lang.String) [20] 9 aload_0 [args]10 arraylength11 invokevirtual java.lang.StringBuilder.append(int) : java.lang.StringBuilder [23]14 ldc <String "b"> [27]16 invokevirtual java.lang.StringBuilder.append(java.lang.String) : java.lang.StringBuilder [29]19 invokevirtual java.lang.StringBuilder.toString() : java.lang.String [32]22 astore_1 [x] |
Но что произойдет, если позже вам понадобится изменить строку с дополнительными частями?
|
1
2
3
4
|
String x = "a" + args.length + "b";if (args.length == 1) x = x + args[0]; |
Теперь у вас будет второй StringBuilder , который просто излишне потребляет память из вашей кучи, оказывая давление на ваш GC. Напишите это вместо:
|
1
2
3
4
5
6
|
StringBuilder x = new StringBuilder("a");x.append(args.length);x.append("b");if (args.length == 1); x.append(args[0]); |
навынос
В приведенном выше примере это, вероятно, совершенно не имеет значения, если вы используете явные экземпляры StringBuilder или если вы полагаетесь на компилятор Java, создающий для вас неявные экземпляры. Но помните, мы в филиале NOPE . Каждый цикл ЦП, который мы тратим на такую глупость, как GC или выделение емкости по умолчанию для StringBuilder, мы теряем N x O x P раз.
Как правило, всегда используйте StringBuilder вместо оператора + . И если вы можете, сохраните ссылку StringBuilder на несколько методов, если ваша String более сложна для построения. Это то, что делает jOOQ , когда вы генерируете сложный оператор SQL. Существует только один StringBuilder который «пересекает» весь ваш SQL AST (абстрактное синтаксическое дерево)
И для громкого крика, если у вас все еще есть ссылки на StringBuffer , замените их на StringBuilder . Вам действительно никогда не нужно синхронизироваться на создаваемой строке.
2. Избегайте регулярных выражений
Регулярные выражения относительно дешевы и удобны. Но если вы находитесь в филиале NOPE , они о худшем, что вы можете сделать. Если вам абсолютно необходимо использовать регулярные выражения в разделах кода, требующих Pattern объема вычислений, по крайней мере Pattern ссылку на Pattern вместо того, чтобы постоянно компилировать ее:
|
1
2
|
static final Pattern HEAVY_REGEX = Pattern.compile("(((X)*Y)*Z)*"); |
Но если ваше регулярное выражение действительно глупо, как
|
1
|
String[] parts = ipAddress.split("\\."); |
… Тогда вам действительно лучше прибегнуть к обычным char[] или манипулированию на основе индекса Например, этот совершенно нечитаемый цикл делает то же самое:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
int length = ipAddress.length();int offset = 0;int part = 0;for (int i = 0; i < length; i++) { if (i == length - 1 || ipAddress.charAt(i + 1) == '.') { parts[part] = ipAddress.substring(offset, i + 1); part++; offset = i + 2; }} |
… который также показывает, почему вы не должны делать преждевременную оптимизацию. По сравнению с версией split() это не поддерживается.
Задача: умные из ваших читателей могут найти еще более быстрые алгоритмы.
навынос
Регулярные выражения полезны, но они имеют свою цену. Если вы глубоко в ветке NOPE , вы должны избегать регулярных выражений любой ценой. Остерегайтесь различных методов JDK String, которые используют регулярные выражения, такие как String.replaceAll() или String.split() .
Вместо этого используйте популярную библиотеку, например Apache Commons Lang , для манипулирования строками.
3. Не используйте итератор ()
Теперь этот совет на самом деле не для общих случаев использования, а применим только в глубине ветви NOPE . Тем не менее, вы должны подумать об этом. Написание циклов foreach в стиле Java-5 удобно. Вы можете просто полностью забыть о внутреннем цикле и написать:
|
1
2
3
|
for (String value : strings) { // Do something useful here} |
Однако каждый раз, когда вы запускаете этот цикл, если strings является Iterable , вы создаете новый экземпляр Iterator . Если вы используете ArrayList , это будет выделение объекта с 3- ints в вашей куче:
|
1
2
3
4
5
|
private class Itr implements Iterator<E> { int cursor; int lastRet = -1; int expectedModCount = modCount; // ... |
Вместо этого вы можете записать следующий эквивалентный цикл и «тратить» только одно значение int в стеке, что очень дешево:
|
1
2
3
4
5
|
int size = strings.size();for (int i = 0; i < size; i++) { String value : strings.get(i); // Do something useful here} |
… или, если ваш список на самом деле не меняется, вы можете даже использовать его массивную версию:
|
1
2
3
|
for (String value : stringArray) { // Do something useful here} |
навынос
Итераторы, Iterable и цикл foreach чрезвычайно полезны с точки зрения удобочитаемости и читаемости, а также с точки зрения разработки API. Однако они создают небольшой новый экземпляр в куче для каждой отдельной итерации. Если вы выполняете эту итерацию много раз, вы должны избегать создания этого бесполезного экземпляра и вместо этого записывать итерации на основе индекса.
обсуждение
Некоторые интересные разногласия по поводу части вышеперечисленного (в частности, замена использования Iterator на access-by-index) обсуждались здесь на Reddit .
4. Не вызывайте этот метод
Некоторые методы просто дороги. В нашем примере ветки NOPE такого метода у нас нет, но у вас вполне может быть такой. Давайте предположим, что вашему драйверу JDBC нужно пройти невероятные проблемы, чтобы вычислить значение ResultSet.wasNull() . Ваш доморощенный SQL-каркасный код может выглядеть следующим образом:
|
01
02
03
04
05
06
07
08
09
10
|
if (type == Integer.class) { result = (T) wasNull(rs, Integer.valueOf(rs.getInt(index)));}// And then...static final <T> T wasNull(ResultSet rs, T value) throws SQLException { return rs.wasNull() ? null : value;} |
Эта логика теперь будет вызывать ResultSet.wasNull() каждый раз, когда вы получаете int из набора результатов. Но контракт getInt() гласит:
Возвращает: значение столбца; если значение равно SQL NULL, возвращаемое значение равно 0
Таким образом, простым, но, возможно, радикальным улучшением вышесказанного будет:
|
1
2
3
4
5
6
7
8
|
static final <T extends Number> T wasNull( ResultSet rs, T value) throws SQLException { return (value == null || (value.intValue() == 0 && rs.wasNull())) ? null : value;} |
Итак, это не просто:
навынос
Не называйте дорогие методы в алгоритме «конечными узлами», а вместо этого кэшируйте вызов или избегайте его, если это позволяет контракт метода.
5. Используйте примитивы и стек
Приведенный выше пример взят из jOOQ , в котором используется много обобщений, и поэтому он вынужден использовать типы-оболочки для byte , short , int и long — по крайней мере, прежде чем обобщения будут специализированы в Java 10 и проекте Valhalla . Но у вас может не быть этого ограничения в вашем коде, поэтому вы должны принять все меры для замены:
|
1
2
|
// Goes to the heapInteger i = 817598; |
… этим:
|
1
2
|
// Stays on the stackint i = 817598; |
Ситуация ухудшается, когда вы используете массивы:
|
1
2
|
// Three heap objects!Integer[] i = { 1337, 424242 }; |
… этим:
|
1
2
|
// One heap object.int[] i = { 1337, 424242 }; |
навынос
Когда вы глубоко в своей ветке NOPE , вы должны быть крайне осторожны с использованием типов оболочки. Скорее всего, вы создадите большое давление на свой сборщик мусора, который должен постоянно вставлять, чтобы навести порядок.
Особенно полезная оптимизация может заключаться в использовании некоторого примитивного типа и создании его больших одномерных массивов и нескольких переменных-разделителей, чтобы указать, где именно ваш кодированный объект находится в массиве.
Отличная библиотека для примитивных коллекций, которые немного сложнее, чем обычные int[] это trove4j , которая поставляется с LGPL.
исключение
Из этого правила есть исключение: boolean и byte имеют достаточно мало значений для полного кэширования JDK. Ты можешь написать:
|
1
2
3
4
5
|
Boolean a1 = true; // ... syntax sugar for:Boolean a2 = Boolean.valueOf(true);Byte b1 = (byte) 123; // ... syntax sugar for:Byte b2 = Byte.valueOf((byte) 123); |
То же самое верно для низких значений других целочисленных примитивных типов, включая char , short , int , long .
Но только если вы автоматически их TheType.valueOf() или вызываете TheType.valueOf() , а не когда вы вызываете конструктор!
Никогда не вызывайте конструктор для типов оболочки, если вы действительно не хотите новый экземпляр
От кучи
Конечно, вы также можете поэкспериментировать с библиотеками вне кучи, хотя это скорее стратегическое решение, а не локальная оптимизация.
Интересная статья на эту тему Питера Лоури и Бена Коттона: OpenJDK и HashMap… Безопасное обучение старой собаки Новые (вне кучи!) Трюки
6. Избегайте рекурсии
Современные функциональные языки программирования, такие как Scala, поощряют использование рекурсии, поскольку они предлагают средства оптимизации алгоритмов хвостовой рекурсии обратно в итеративные . Если ваш язык поддерживает такие оптимизации, у вас все может быть в порядке. Но даже в этом случае малейшее изменение алгоритма может привести к появлению ветви, которая не позволит вашей рекурсии быть хвостовой рекурсией. Надеюсь, компилятор обнаружит это! В противном случае вы могли бы тратить много кадров стека на что-то, что могло быть реализовано с использованием только нескольких локальных переменных.
навынос
Об этом особо нечего сказать, кроме: Всегда предпочитайте итерацию, а не рекурсию, когда вы глубоко в ветке NOPE
7. Используйте entrySet ()
Если вы хотите выполнить итерацию по Map и вам нужны и ключи, и значения, у вас должна быть очень веская причина написать следующее:
|
1
2
3
|
for (K key : map.keySet()) { V value : map.get(key);} |
… а не следующее:
|
1
2
3
4
|
for (Entry<K, V> entry : map.entrySet()) { K key = entry.getKey(); V value = entry.getValue();} |
Когда вы находитесь в ветке NOPE , вам все равно следует опасаться карт, потому что множество операций доступа к карте O(1) по-прежнему являются множеством операций. И доступ тоже не бесплатный. Но, по крайней мере, если вы не можете обойтись без карт, используйте entrySet() для их итерации! В Map.Entry случае экземпляр Map.Entry есть, вам нужен только доступ к нему.
навынос
Всегда используйте entrySet() когда вам нужны и ключи, и значения во время итерации карты.
8. Используйте EnumSet или EnumMap
В некоторых случаях количество возможных ключей на карте известно заранее, например, при использовании карты конфигурации. Если это число относительно мало, вам следует рассмотреть возможность использования EnumSet или EnumSet вместо обычного HashSet или HashMap . Это легко объяснить, посмотрев на EnumMap.put() :
|
1
2
3
4
5
6
7
8
|
private transient Object[] vals;public V put(K key, V value) { // ... int index = key.ordinal(); vals[index] = maskNull(value); // ...} |
Суть этой реализации заключается в том, что у нас есть массив индексированных значений, а не хеш-таблица. При вставке нового значения все, что нам нужно сделать для поиска записи карты, это запросить у enum его постоянный порядковый номер, который генерируется компилятором Java для каждого типа enum. Если это глобальная карта конфигурации (т.е. только один экземпляр), то увеличенная скорость доступа поможет EnumMap значительно превзойти HashMap , который может использовать немного меньше динамической памяти, но который должен будет запускать hashCode() и equals() для каждого ключа ,
навынос
Enum и EnumMap — очень близкие друзья. Всякий раз, когда вы используете enum-подобные структуры в качестве ключей, подумайте над тем, чтобы сделать эти структуры перечислениями и использовать их в качестве ключей в EnumMap .
9. Оптимизируйте методы hashCode () и equals ()
Если вы не можете использовать EnumMap , хотя бы оптимизируйте методы hashCode() и equals() . Хороший метод hashCode() важен, потому что он предотвратит дальнейшие вызовы гораздо более дорогих equals() как он будет генерировать более отличные хэш-блоки для набора экземпляров.
В каждой иерархии классов у вас могут быть популярные и простые объекты. Давайте посмотрим на реализации org.jooq.Table в org.jooq.Table .
Самая простая и быстрая реализация hashCode() — это:
|
01
02
03
04
05
06
07
08
09
10
|
// AbstractTable, a common Table base implementation:@Overridepublic int hashCode() { // [#1938] This is a much more efficient hashCode() // implementation compared to that of standard // QueryParts return name.hashCode();} |
… Где name — это просто имя таблицы. Мы даже не рассматриваем схему или любое другое свойство таблицы, поскольку имена таблиц обычно достаточно различны в базе данных. Кроме того, name является строкой, поэтому оно уже имеет кэшированное значение hashCode() внутри.
Комментарий важен, потому что AbstractTable расширяет AbstractQueryPart , который является общей базовой реализацией для любого элемента AST (Abstract Syntax Tree) . Общий элемент AST не имеет никаких свойств, поэтому он не может делать какие-либо предположения оптимизированной hashCode() . Таким образом, переопределенный метод выглядит так:
|
01
02
03
04
05
06
07
08
09
10
|
// AbstractQueryPart, a common AST element// base implementation:@Overridepublic int hashCode() { // This is a working default implementation. // It should be overridden by concrete subclasses, // to improve performance return create().renderInlined(this).hashCode();} |
Другими словами, весь рабочий процесс рендеринга SQL должен запускаться для вычисления хэш-кода общего элемента AST.
Вещи становятся более интересными с equals()
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
// AbstractTable, a common Table base implementation:@Overridepublic boolean equals(Object that) { if (this == that) { return true; } // [#2144] Non-equality can be decided early, // without executing the rather expensive // implementation of AbstractQueryPart.equals() if (that instanceof AbstractTable) { if (StringUtils.equals(name, (((AbstractTable<?>) that).name))) { return super.equals(that); } return false; } return false;} |
Первое: всегда (не только в ветке NOPE ) прерывать каждый метод equals() раньше, если:
-
this == argument -
this "incompatible type" argument
Обратите внимание, что последнее условие включает argument == null , если вы используете instanceof для проверки совместимости типов. Мы уже писали об этом в 10 тонких рекомендациях по кодированию Java .
Теперь, после раннего прекращения сравнения в очевидных случаях, вы можете также захотеть прервать сравнение на ранней стадии, когда сможете принимать частичные решения. Например, контракт Table.equals Table.equals() заключается в том, что для того, чтобы две таблицы считались равными, они должны иметь одинаковое имя, независимо от конкретного типа реализации. Например, эти два элемента не могут быть одинаковыми:
-
com.example.generated.Tables.MY_TABLE -
DSL.tableByName("MY_OTHER_TABLE")
Если argument не может быть равен this , и если мы можем проверить это легко, давайте сделаем это и прервем, если проверка не удалась. Если проверка прошла успешно, мы все равно можем перейти к более дорогой реализации из super . Учитывая, что большинство объектов в юниверсе не равны, мы собираемся сэкономить много времени процессора, сокращая этот метод.
некоторые объекты более равны, чем другие
В случае jOOQ большинство экземпляров действительно являются таблицами, сгенерированными генератором исходного кода jOOQ , реализация equals() которого еще более оптимизирована. Десятки других типов таблиц (производные таблицы, табличные функции, таблицы массивов, объединенные таблицы, сводные таблицы, выражения общих таблиц и т. Д.) Могут сохранять свою «простую» реализацию.
10. Думайте в наборах, а не в отдельных элементах
Наконец, что не менее важно, есть вещь, которая не связана с Java, но применима к любому языку. Кроме того, мы покидаем ветку NOPE, поскольку этот совет может просто помочь вам перейти от O(N 3 ) к O(n log n) или что-то в этом роде.
К сожалению, многие программисты думают в терминах простых локальных алгоритмов. Они решают проблему шаг за шагом, ветви за веткой, петли за петлей, метод за методом. Это императивный и / или функциональный стиль программирования. Хотя все более легко моделировать «большую картину» при переходе от чисто императивного к объектно-ориентированному (все еще обязательному) функциональному программированию, во всех этих стилях отсутствует то, что есть только в SQL, R и аналогичных языках:
Декларативное программирование.
В SQL ( и нам это нравится, так как это блог jOOQ ) вы можете объявить результат, который вы хотите получить из своей базы данных, без каких-либо алгоритмических последствий. Затем база данных может принять во внимание все доступные метаданные ( например, ограничения, ключи, индексы и т. Д. ), Чтобы выяснить наилучший возможный алгоритм.
Теоретически, это была основная идея SQL и реляционного исчисления с самого начала. На практике поставщики SQL внедряют высокоэффективные CBO (Оптимизаторы на основе затрат) только с последнего десятилетия, поэтому оставайтесь с нами в 2010-х годах, когда SQL наконец-то раскроет весь свой потенциал (это было время!)
Но вам не нужно делать SQL, чтобы думать в наборах. Наборы / коллекции / сумки / списки доступны на всех языках и в библиотеках. Основным преимуществом использования множеств является тот факт, что ваши алгоритмы станут намного более краткими. Намного легче написать:
|
1
|
SomeSet INTERSECT SomeOtherSet |
скорее, чем:
|
01
02
03
04
05
06
07
08
09
10
|
// Pre-Java 8Set result = new HashSet();for (Object candidate : someSet) if (someOtherSet.contains(candidate)) result.add(candidate);// Even Java 8 doesn't really helpsomeSet.stream() .filter(someOtherSet::contains) .collect(Collectors.toSet()); |
Некоторые могут утверждать, что функциональное программирование и Java 8 помогут вам писать более простые и лаконичные алгоритмы. Это не обязательно правда. Вы можете перевести свой императивный цикл Java-7 в функциональную коллекцию потока Java-8, но вы все еще пишете тот же алгоритм. Написание выражения в стиле SQL отличается. Этот…
|
1
|
SomeSet INTERSECT SomeOtherSet |
… Может быть реализовано 1000 способами с помощью механизма реализации. Как мы узнали сегодня, возможно, имеет EnumSet автоматически преобразовать два набора в EnumSet перед запуском операции INTERSECT . Возможно, мы можем распараллелить этот INTERSECT не делая низкоуровневых вызовов Stream.parallel()
Вывод
В этой статье мы поговорили об оптимизации, выполненной в ветви NOPE , т. Е. Глубоко в алгоритме высокой сложности. В нашем случае, будучи разработчиками jOOQ , мы заинтересованы в оптимизации нашей генерации SQL:
- Каждый запрос генерируется только на одном
StringBuilder - Наш шаблонизатор фактически анализирует символы вместо использования регулярных выражений
- Мы используем массивы везде, где можем, особенно при переборе слушателей
- Мы избегаем методов JDBC, которые нам не нужно вызывать
- и т.д…
jOOQ находится в «нижней части пищевой цепи», потому что это (второй) последний API, который вызывается приложениями наших клиентов до того, как вызов покинет JVM для входа в СУБД. Нахождение в нижней части пищевой цепочки означает, что каждая строка кода, которая выполняется в jOOQ, может называться N x O x P раз, поэтому мы должны с нетерпением оптимизировать.
Ваша бизнес-логика не глубоко в ветви NOPE . Но ваша собственная, доморощенная логика инфраструктуры может быть (пользовательские платформы SQL, пользовательские библиотеки и т. Д.). Они должны быть рассмотрены в соответствии с правилами, которые мы видели сегодня. Например, используя Java Mission Control или любой другой профилировщик.
| Ссылка: | Топ-10 простых оптимизаций производительности в Java от нашего партнера по JCG Лукаса Эдера из блога JAVA, SQL и JOOQ . |