 Когда я начал свою карьеру около 10 лет назад, Struts MVC был нормой на рынке. Однако с годами я наблюдал, как Spring MVC постепенно набирает популярность. Это меня не удивляет, учитывая полную интеграцию Spring MVC с контейнером Spring и гибкость и расширяемость, которые он предлагает.
Когда я начал свою карьеру около 10 лет назад, Struts MVC был нормой на рынке. Однако с годами я наблюдал, как Spring MVC постепенно набирает популярность. Это меня не удивляет, учитывая полную интеграцию Spring MVC с контейнером Spring и гибкость и расширяемость, которые он предлагает.
Из моего путешествия с Spring до сих пор я обычно видел людей, делающих некоторые типичные ошибки при настройке Spring Framework. Это случалось чаще по сравнению с тем временем, когда люди все еще использовали среду Struts. Я предполагаю, что это компромисс между гибкостью и удобством использования. Кроме того, документация Spring полна примеров, но не содержит объяснений. Чтобы помочь восполнить этот пробел, в этой статье мы попытаемся разработать и объяснить 3 распространенных проблемы, с которыми я часто сталкиваюсь.
Объявление бинов в файле определения контекста сервлета
Итак, каждый из нас знает, что Spring использует ContextLoaderListener для загрузки контекста приложения Spring. Тем не менее, при объявлении
DispatcherServlet , нам нужно создать файл определения контекста сервлета с именем «$ {servlet.name} -context.xml». Вы никогда не задумывались, почему?
Иерархия контекста приложения
Не все разработчики знают, что контекст приложения Spring имеет иерархию. Давайте посмотрим на этот метод:
org.springframework.context.ApplicationContext.getParent ()
Это говорит нам о том, что Spring Application Context имеет родителя. Итак, для чего этот родитель?
Если вы загрузите исходный код и выполните быстрый поиск ссылок, вы обнаружите, что Spring Application Context рассматривает parent как его расширение. Если вы не против прочитать код, позвольте мне показать вам один пример использования в методе BeanFactoryUtils.beansOfTypeIncключAncestors () :
|
01
02
03
04
05
06
07
08
09
10
|
if (lbf instanceof HierarchicalBeanFactory) { HierarchicalBeanFactory hbf = (HierarchicalBeanFactory) lbf; if (hbf.getParentBeanFactory() instanceof ListableBeanFactory) { Map parentResult = beansOfTypeIncludingAncestors((ListableBeanFactory) hbf.getParentBeanFactory(), type); ... }}return result;} |
Если вы выполните весь метод, вы обнаружите, что Spring Application Context Context сканирует, чтобы найти bean-компоненты во внутреннем контексте, прежде чем искать родительский контекст. С этой стратегией, эффективно, Spring Application Context будет сначала выполнять поиск в обратном направлении для поиска bean-компонентов.
ContextLoaderListener
Это хорошо известный класс, который должен знать каждый разработчик. Это помогает загрузить контекст приложения Spring из предопределенного файла определения контекста. Поскольку он реализует ServletContextListener , контекст приложения Spring будет загружен сразу после загрузки веб-приложения. Это дает неоспоримые преимущества при загрузке контейнера Spring, который содержит компоненты с аннотацией @PostContruct или пакетными заданиями.
Напротив, любое определение компонента в файле определения контекста сервлета не будет создано до тех пор, пока сервлет не будет инициализирован. Когда сервлет инициализируется? Это неопределенно. В худшем случае вам может потребоваться подождать, пока пользователи не выполнят первый переход по URL-адресу отображения сервлета, чтобы загрузить контекст Spring.
С вышеупомянутой информацией, где вы должны объявить все свои драгоценные бобы? Я чувствую, что лучшее место для этого — файл определения контекста, загруженный ContextLoaderListener, и больше нигде. Хитрость здесь заключается в хранении ApplicationContext в качестве атрибута сервлета под ключом org.springframework.web.context.WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE
Позднее DispatcherServlet загрузит этот контекст из ServletContext и назначит его в качестве контекста родительского приложения.
|
1
2
3
4
5
|
protected WebApplicationContext initWebApplicationContext() { WebApplicationContext rootContext = WebApplicationContextUtils.getWebApplicationContext(getServletContext()); ...} |
Из-за этого поведения настоятельно рекомендуется создать пустой файл определения контекста приложения сервлета и определить компоненты в родительском контексте. Это поможет избежать дублирования создания компонента при загрузке веб-приложения и гарантирует, что пакетные задания выполняются немедленно.
Теоретически, определение компонента в файле определения контекста приложения сервлета делает компонент уникальным и видимым только для этого сервлета. Однако за 8 лет использования Spring я практически не нашел применения этой функции, кроме определения конечной точки веб-службы.
Объявите Log4jConfigListener после ContextLoaderListener
Это небольшая ошибка, но она поймает вас, когда вы не обращаете на нее внимания. Log4jConfigListener — мое предпочтительное решение по сравнению с -Dlog4j.configuration, так как мы можем контролировать загрузку log4j без изменения процесса начальной загрузки сервера.
Очевидно, это должен быть первый слушатель, который будет объявлен в вашем web.xml. В противном случае все ваши усилия по объявлению правильной конфигурации журналирования будут потрачены впустую.
Дублированные Бобы из-за неправильного управления исследованием бобов
В начале весны разработчики тратили больше времени на набор XML-файлов, чем на Java-классы. Для каждого нового компонента нам нужно самим объявить и связать зависимости, что является чистым, аккуратным, но очень болезненным. Не удивительно, что более поздние версии Spring Framework эволюционировали в сторону большего удобства использования. В настоящее время разработчикам может потребоваться только объявить диспетчер транзакций, источник данных, источник свойств, конечную точку веб-службы, а остальное оставить для сканирования компонентов и автоматического подключения.
Мне нравятся эти новые функции, но эта великая сила должна прийти с большой ответственностью; в противном случае все будет очень быстро. Сканирование компонентов и объявление компонентов в файлах XML полностью независимы. Следовательно, вполне возможно иметь идентичные bean-компоненты одного и того же класса в контейнере bean-компонента, если bean-компоненты аннотированы для сканирования компонентов и также объявлены вручную. К счастью, такая ошибка должна случиться только с новичками.
Ситуация усложняется, когда нам нужно интегрировать некоторые встроенные компоненты в конечный продукт. Тогда нам действительно нужна стратегия, чтобы избежать дублирования декларации bean-компонента.
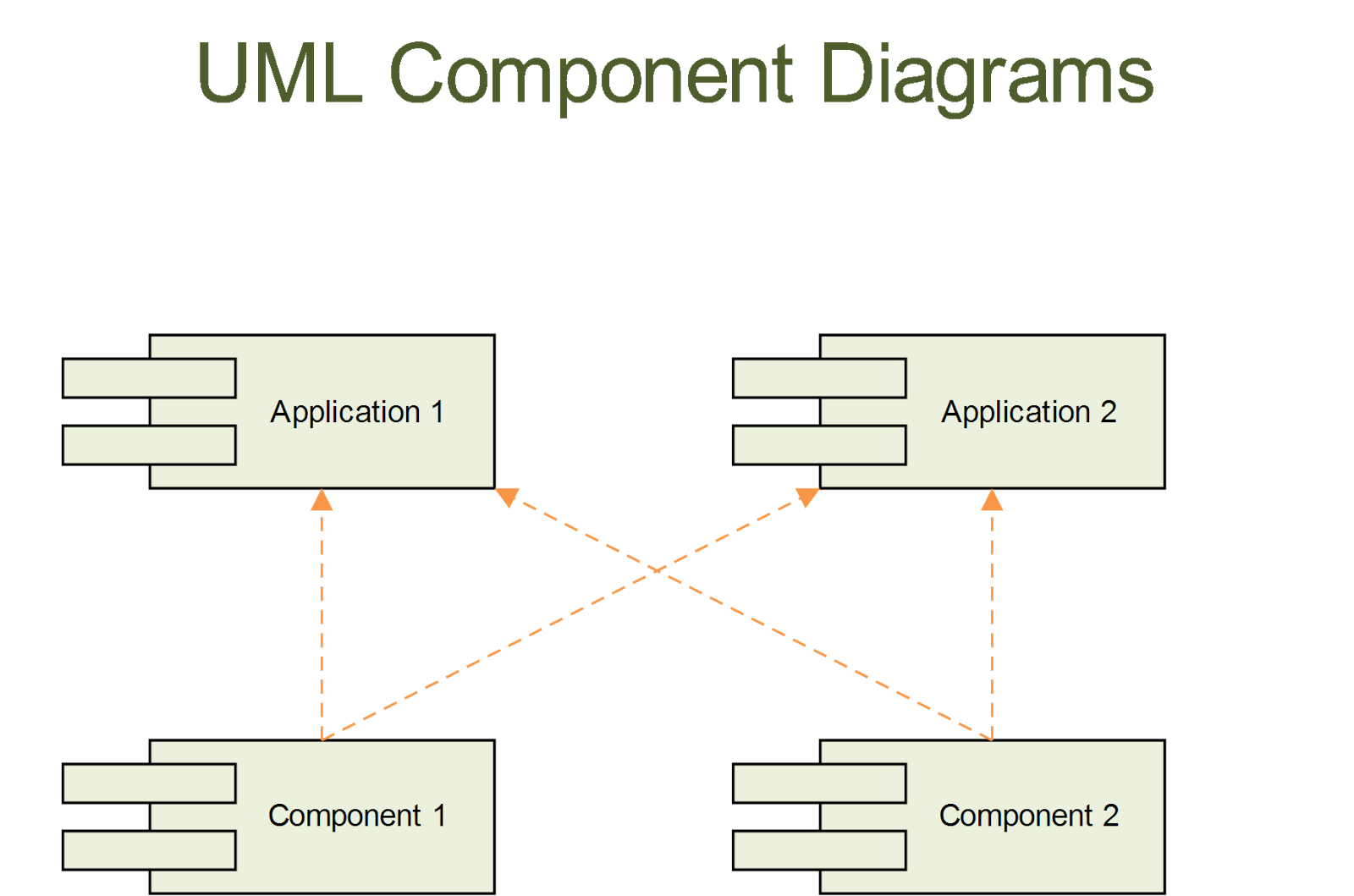
Приведенная выше диаграмма показывает реалистичный пример проблем, с которыми мы сталкиваемся в повседневной жизни. В большинстве случаев система состоит из нескольких компонентов, и часто один компонент обслуживает несколько продуктов. Каждое приложение и компонент имеют свои собственные компоненты. В этом случае, что должно быть лучшим способом объявить, чтобы избежать дублированного объявления бина?
Вот моя предложенная стратегия:
- Убедитесь, что каждый компонент должен начинаться с выделенного имени пакета. Это делает нашу жизнь проще, когда нам нужно выполнить компонентное сканирование.
- Не предписывайте команде, которая разрабатывает компонент, подходить к объявлению bean-компонента в самом компоненте (аннотация вместо объявления xml). Разработчик обязан упаковать компоненты в конечный продукт, чтобы избежать дублирования декларации bean-компонента.
- Если внутри компонента есть файл определения контекста, передайте ему пакет, а не в корень classpath. Еще лучше дать ему конкретное имя. Например, src / main / resources / spring-core / spring-core-context.xml намного лучше, чем src / main / resource / application-context.xml. Представьте, что мы можем сделать, если упакуем несколько компонентов, содержащих один и тот же файл application-context.xml, в один и тот же пакет!
- Не предоставляйте аннотации для сканирования компонентов ( @Component , @Service или @Repository ), если вы уже объявили компонент в одном файле контекста.
- Разделите bean-компонент среды, такой как источник данных , свойство-источник, на отдельный файл и используйте его повторно.
- Не выполняйте компонентное сканирование на общем пакете. Например, вместо сканирования пакета org.springframework легче управлять, если мы сканируем несколько подпакетов , таких как org.springframework.core , org.springframework.context , org.springframework.ui ,…
Вывод
Я надеюсь, что вы нашли вышеупомянутые советы полезными для ежедневного использования. Если есть какие-либо сомнения или какие-либо другие идеи, пожалуйста, помогите, отправив отзыв.
| Ссылка: | Распространенные ошибки при использовании Spring MVC от нашего партнера по JCG Нгуен Ань Туана в блоге Developer Corner . |