Пытаясь вывести Java на первое место в конкурсе regexdna для The Computer Language Benchmarks Game, я исследовал производительность библиотек регулярных выражений для Java. Самым последним веб-сайтом, который я смог найти, был tusker.org с 2010 года. Поэтому я решил переделать тесты с использованием Java Microbenchmarking Harness и опубликовать результаты (предупреждение спойлера: я получил Java на # 1 с помощью некоторых неортодоксальных решений).
TL; DR : регулярные выражения хороши для специальных запросов, но если у вас есть что-то чувствительное к производительности, вы должны вручную написать свое решение (это не значит, что вы должны начинать с абсолютного нуля — например, в библиотеке Google Guava некоторые полезные утилиты, которые могут помочь в написании читабельного, но также и производительного кода).
А теперь для некоторых графиков, суммирующих производительность — тест проводился на 64-битной машине Ubuntu 15.10 с OpenJDK 1.8.0_66:
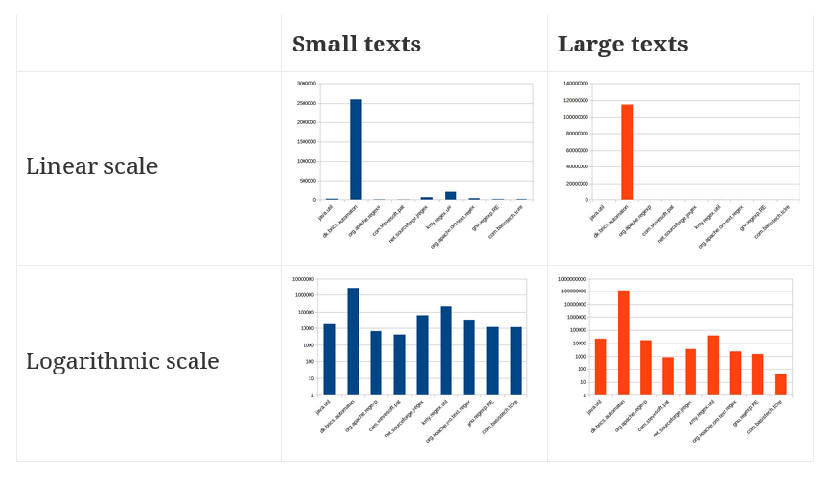
наблюдения
- не существует «стандарта» для регулярных выражений, поэтому разные библиотеки могут вести себя по-разному, если им дано определенное регулярное выражение и определенная строка для сопоставления, т.е. один может сказать, что это соответствует, но другой может сказать, что это не так. Например, хотя я использовал очень ограниченный набор тестовых случаев (5 регулярных выражений, проверенных по 6 строкам), только двум библиотекам удалось сопоставить или не сопоставить их все правильно (одна из них — java.util.Pattern).
- вероятно, потребуется несколько попыток, чтобы получить правильное регулярное выражение (такие инструменты, как regexpal или Regex Coach , очень полезны для экспериментов)
- Производительность регулярного выражения трудно предсказать (и иногда она может иметь экспоненциальную сложность в зависимости от длины ввода ) — из-за этого вам нужно дважды подумать, если вы принимаете регулярное выражение от произвольных пользователей в Интернете (например, поисковая система, которая позволит поиск по регулярным выражениям, например)
- похоже, что ни одна из библиотек больше не находится в активной разработке (на самом деле, многие из исходного списка на tusker.org сейчас недоступны), и многие из них работают медленнее, чем встроенный juPattern , так что если вы используете регулярные выражения, которые должны вероятно, будет первым выбором.
- При этом производительность как оборудования, так и JVM была значительной, поэтому, если вы используете одну из этих библиотек, она обычно работает на порядок быстрее, чем пять лет назад. Поэтому нет необходимости быстро заменять рабочий код (если ваш профилировщик не скажет, что это проблема :-))
- следите за вызовами String.split в циклах. Хотя он имеет некоторую оптимизацию для конкретных случаев (например, регулярные выражения с одним символом), вы должны почти всегда:
- посмотрите, можете ли вы использовать что-то вроде Splitter от Google Guava
- если вам нужно регулярное выражение, хотя бы предварительно скомпилируйте его вне цикла
- Два сюрприза были dk.brics.automaton, которые превзошли все остальные на несколько порядков:
- последний релиз был в 2011 году и, кажется, больше академический проект
- он не поддерживает тот же синтаксис, что и java.util.Pattern (но не выдает предупреждение, если вы пытаетесь использовать juPattern — он просто не будет соответствовать строкам, которые, по вашему мнению, должны)
- не имеет API так же удобно, как juPattern (например, отсутствуют замены)
- Другим сюрпризом был kmy.regex.util.Regex , который — хотя и не обновлялся с 2000 года — превзошел java.util.Pattern и прошел все тесты (которых, по общему признанию , было немного ).
Полный список используемых библиотек:
| Название и версия библиотеки (год выпуска) | Доступно в Maven Central | Лицензия | Среднее количество операций в секунду | Среднее число операций в секунду (большой текст) | Сдача тестов |
|---|---|---|---|---|---|
| j.util.Pattern 1.8 (2015) | нет (поставляется с JRE) | Лицензия JRE | 19 689 | 22 144 | 5 из 5 |
| dk.brics.automaton.Automaton 1.11-8 (2011) | да | BSD | 2 600 225 | 115 374 276 | 2 из 5 |
| org.apache.regexp 1.4 (2005) | да | Апач (?) | 6 738 | 16 895 | 4 из 5 |
| com.stevesoft.pat.Regex 1.5.3 (2009) | да | LGPL v3 | 4 191 | +859 | 4 из 5 |
| net.sourceforge.jregex 1.2_01 (2002) | да | BSD | 57 811 | 3 573 | 4 из 5 |
| kmy.regex.util.Regex 0.1.2 (2000) | нет | Художественная лицензия | 217 803 | 38 184 | 5 из 5 |
| org.apache.oro.text.regex.Perl5Matcher 2.0.8 (2003) | да | Apache 2.0 | 31 906 | 2383 | 4 из 5 |
| gnu.regexp.RE 1.1.4 (2005?) | да | GPL (?) | 11 848 | 1 509 | 4 из 5 |
| com.basistech.tclre.RePattern 0.13.6 (2015) | да | Apache 2.0 | 11 598 | 43 | 3 из 5 |
| com.karneim.util.collection.regex.Pattern 1.1.1 (2005?) | да | ? | — | — | 2 из 5 |
| org.apache.xerces.impl.xpath.regex.RegularExpression 2.11.0 (2014) | да | Apache 2.0 | — | — | 4 из 5 |
| com.ibm.regex.RegularExpression 1.0.2 (больше не доступно) | нет | ? | — | — | — |
| RegularExpression.RE 1.1 (больше не доступно) | нет | ? | — | — | — |
| gnu.rex.Rex? (больше недоступно) | нет | ? | — | — | — |
| monq.jfa.Regexp 1.1.1 (больше не доступно) | нет | ? | — | — | — |
| com.ibm.icu.text.UnicodeSet (ICU4J) 56,1 (2015) | да | Лицензия ICU | — | — | — |
Если вы хотите перезапустить тесты, проверьте исходный код и запустите его следующим образом:
|
1
2
3
4
|
# we need to skip tests since almost all libraries fail a test or an othermvn -Dmaven.test.skip=true clean package# run the benchmarksjava -cp lib/jint.jar:target/benchmarks.jar net.greypanther.javaadvent.regex.RegexBenchmarks |
И, наконец, как насчет задачи regexdna для игры The Computer Language Benchmarks Game ? Я получил Java на # 1, используя битовые операции, чтобы проверить блоки по 8 байт, если они являются потенциальными совпадениями, и только затем проверить их на соответствие регулярным выражениям. Как я уже говорил ранее: если вам нужна производительность, вам нужно написать свои собственные парсеры.
| Ссылка: | Тесты библиотеки регулярных выражений Java — 2015 от нашего партнера JCG Аттилы Михали Балаза в блоге Java Advent Calendar . |