При написании юнит-тестов мы в основном ориентируемся на корректность бизнеса. Мы прилагаем все усилия, чтобы осуществить счастливый путь и все крайние случаи. Мы иногда микробенчмаркируем и измеряем пропускную способность. Но один аспект, который часто упускается, — это как ведет себя наш код, когда ввод слишком велик? Мы проверяем, как мы обрабатываем обычные входные файлы, искаженные файлы, пустые файлы, отсутствующие файлы … но как насчет безумно больших входных файлов?
Давайте начнем с реального варианта использования. Перед вами была поставлена задача реализовать преобразование GPX ( формат обмена GPS , в основном XML) в JSON. Я выбрал GPX без особой причины, это просто еще один формат XML, с которым вы могли столкнуться, например, при записи похода или поездки на велосипеде с помощью GPS-приемника. Также я подумал, что будет неплохо использовать какой-то стандарт, а не еще одну «базу данных людей» в XML. Внутри файла GPX находятся сотни плоских <wpt/> записей, каждая из которых представляет одну точку в пространстве-времени:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
<gpx> <wpt lat="42.438878" lon="-71.119277"> <ele>44.586548</ele> <time>2001-11-28T21:05:28Z</time> <name>5066</name> <desc><![CDATA[5066]]></desc> <sym>Crossing</sym> <type><![CDATA[Crossing]]></type> </wpt> <wpt lat="42.439227" lon="-71.119689"> <ele>57.607200</ele> <time>2001-06-02T03:26:55Z</time> <name>5067</name> <desc><![CDATA[5067]]></desc> <sym>Dot</sym> <type><![CDATA[Intersection]]></type> </wpt> <!-- ...more... --></gpx> |
Полный пример: www.topografix.com/fells_loop.gpx . Наша задача — извлечь каждый отдельный элемент <wpt/> , отбросить элементы без атрибутов lat или lon и сохранить обратно JSON в следующем формате:
|
1
2
3
4
5
|
[ {"lat": 42.438878,"lon": -71.119277}, {"lat": 42.439227,"lon": -71.119689} ...more...] |
Это легко! Прежде всего я начал с создания классов JAXB с использованием утилиты xjc из схемы JDK и GPX 1.0 XSD . Обратите внимание, что GPX 1.1 является самой последней версией на момент написания этой статьи, но примеры, которые я получил, используют 1.0. Для сортировки JSON я использовал Джексона . Полная, работающая и протестированная программа выглядит так:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
import org.apache.commons.io.FileUtils;import org.codehaus.jackson.map.ObjectMapper;import javax.xml.bind.JAXBException;public class GpxTransformation { private final ObjectMapper jsonMapper = new ObjectMapper(); private final JAXBContext jaxbContext; public GpxTransformation() throws JAXBException { jaxbContext = JAXBContext.newInstance("com.topografix.gpx._1._0"); } public void transform(File inputFile, File outputFile) throws JAXBException, IOException { final List<Gpx.Wpt> waypoints = loadWaypoints(inputFile); final List<LatLong> coordinates = toCoordinates(waypoints); dumpJson(coordinates, outputFile); } private List<Gpx.Wpt> loadWaypoints(File inputFile) throws JAXBException, IOException { String xmlContents = FileUtils.readFileToString(inputFile, UTF_8); final Unmarshaller unmarshaller = jaxbContext.createUnmarshaller(); final Gpx gpx = (Gpx) unmarshaller.unmarshal(new StringReader(xmlContents)); return gpx.getWpt(); } private static List<LatLong> toCoordinates(List<Gpx.Wpt> waypoints) { return waypoints .stream() .filter(wpt -> wpt.getLat() != null) .filter(wpt -> wpt.getLon() != null) .map(LatLong::new) .collect(toList()); } private void dumpJson(List<LatLong> coordinates, File outputFile) throws IOException { final String resultJson = jsonMapper.writeValueAsString(coordinates); FileUtils.writeStringToFile(outputFile, resultJson); }}class LatLong { private final double lat; private final double lon; LatLong(Gpx.Wpt waypoint) { this.lat = waypoint.getLat().doubleValue(); this.lon = waypoint.getLon().doubleValue(); } public double getLat() { return lat; } public double getLon() { return lon; }} |
Выглядит довольно хорошо, несмотря на несколько ловушек, которые я оставил намеренно. Мы загружаем XML-файл GPX, извлекаем путевые точки в List , преобразуем этот список в легкие объекты LatLong , сначала отфильтровывая сломанные путевые точки. Наконец мы сбрасываем List<LatLong> обратно на диск. Однако однажды чрезвычайно длинная поездка на велосипеде OutOfMemoryError нашу систему с OutOfMemoryError . Ты знаешь, что случилось? Файл GPX, загруженный в наше приложение, был огромен, намного больше, чем мы ожидали получить. Теперь снова посмотрите на реализацию выше и посчитайте, сколько мест мы выделяем больше памяти, чем необходимо?
Но если вы хотите немедленно провести рефакторинг, остановитесь прямо здесь! Мы хотим практиковать TDD, верно? И мы хотим ограничить коэффициент WTF / мин в нашем коде? У меня есть теория, что многие «WTF» не вызваны небрежными и неопытными программистами. Часто это из-за производственных проблем в конце пятницы, совершенно неожиданных исходных данных и непредсказуемых побочных эффектов. Код получает все больше и больше обходных путей, сложный для понимания рефакторинг, более сложную логику, чем можно было ожидать. Иногда плохой код не предназначался, но требовал обстоятельств, которые мы давно забыли. Поэтому, если однажды вы увидите null проверку, которая не может произойти, или рукописный код, который мог бы быть заменен библиотекой — подумайте о контексте. При этом давайте начнем с написания тестов, доказывающих необходимость наших будущих рефакторингов. Если однажды кто-то «исправит» наш код, предполагая, что «этот глупый программист» усложнил задачу без веской причины, автоматические тесты точно скажут, почему .
Наш тест просто попытается преобразовать безумно большие входные файлы. Но прежде чем мы начнем, мы должны немного реорганизовать исходную реализацию, чтобы она вписывала InputStream и OutputStream а не входной и выходной File s — нет никаких оснований ограничивать нашу реализацию только файловой системой:
Шаг 0a: Сделайте это тестируемым
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
import org.apache.commons.io.IOUtils;public class GpxTransformation { //... public void transform(File inputFile, File outputFile) throws JAXBException, IOException { try ( InputStream input = new BufferedInputStream(new FileInputStream(inputFile)); OutputStream output = new BufferedOutputStream(new FileOutputStream(outputFile))) { transform(input, output); } } public void transform(InputStream input, OutputStream output) throws JAXBException, IOException { final List<Gpx.Wpt> waypoints = loadWaypoints(input); final List<LatLong> coordinates = toCoordinates(waypoints); dumpJson(coordinates, output); } private List<Gpx.Wpt> loadWaypoints(InputStream input) throws JAXBException, IOException { String xmlContents = IOUtils.toString(input, UTF_8); final Unmarshaller unmarshaller = jaxbContext.createUnmarshaller(); final Gpx gpx = (Gpx) unmarshaller.unmarshal(new StringReader(xmlContents)); return gpx.getWpt(); } //... private void dumpJson(List<LatLong> coordinates, OutputStream output) throws IOException { final String resultJson = jsonMapper.writeValueAsString(coordinates); output.write(resultJson.getBytes(UTF_8)); }} |
Шаг 0b: Написание входного (стресс) теста
Входные данные будут генерироваться с нуля с использованием утилиты repeat(byte[] sample, int times) разработанной ранее . Мы в основном будем повторять один и тот же элемент <wpt/> миллионы раз, обернув его заголовком и нижним колонтитулом GPX, чтобы он был правильно сформирован. Обычно я хотел бы поместить образцы в src/test/resources , но я хотел, чтобы этот код был автономным. Обратите внимание, что мы не заботимся ни о реальном входе, ни о выходе. Это уже проверено. Если преобразование выполнено успешно (мы можем добавить некоторое время ожидания, если захотим), все в порядке. Если происходит сбой с каким-либо исключением, скорее всего OutOfMemoryError , это тестовый сбой (ошибка):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
import org.apache.commons.io.FileUtilsimport org.apache.commons.io.output.NullOutputStreamimport spock.lang.Specificationimport spock.lang.Unrollimport static org.apache.commons.io.FileUtils.ONE_GBimport static org.apache.commons.io.FileUtils.ONE_KBimport static org.apache.commons.io.FileUtils.ONE_MB@Unrollclass LargeInputSpec extends Specification { final GpxTransformation transformation = new GpxTransformation() final byte[] header = """<?xml version="1.0"?> <gpx version="1.0" <time>2002-02-27T17:18:33Z</time> """.getBytes(UTF_8) final byte[] gpxSample = """ <wpt lat="42.438878" lon="-71.119277"> <ele>44.586548</ele> <time>2001-11-28T21:05:28Z</time> <name>5066</name> <desc><![CDATA[5066]]></desc> <sym>Crossing</sym> <type><![CDATA[Crossing]]></type> </wpt> """.getBytes(UTF_8) final byte[] footer = """</gpx>""".getBytes(UTF_8) def "Should not fail with OOM for input of size #readableBytes"() { given: int repeats = size / gpxSample.length InputStream xml = withHeaderAndFooter( RepeatedInputStream.repeat(gpxSample, repeats)) expect: transformation.transform(xml, new NullOutputStream()) where: size << [ONE_KB, ONE_MB, 10 * ONE_MB, 100 * ONE_MB, ONE_GB, 8 * ONE_GB, 32 * ONE_GB] readableBytes = FileUtils.byteCountToDisplaySize(size) } private InputStream withHeaderAndFooter(InputStream samples) { InputStream withHeader = new SequenceInputStream( new ByteArrayInputStream(header), samples) return new SequenceInputStream( withHeader, new ByteArrayInputStream(footer)) }} |
Здесь фактически 7 тестов, выполняющих преобразование GPX в JSON для входных данных размером: 1 КБ, 1 МБ, 10 МБ, 100 МБ, 1 ГБ, 8 ГБ и 32 ГБ. Я запускаю эти тесты на JDK 8u11x64 со следующими параметрами: -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xmx1g . 1 ГиБ памяти много, но явно не может вместить весь входной файл в памяти:
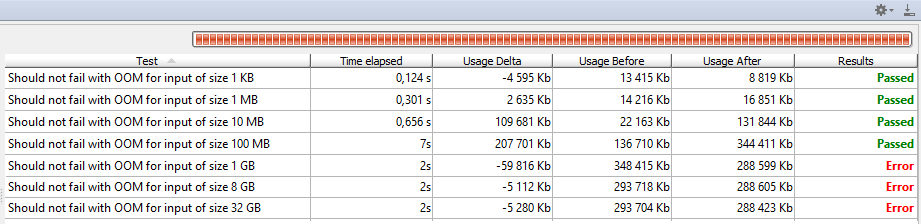
В то время как небольшие тесты проходят, входы выше 1 ГиБ быстро терпят неудачу.
Шаг 1: Избегайте хранения целых файлов в String
Трассировка стека показывает, в чем проблема:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
java.lang.OutOfMemoryError: Java heap space at java.util.Arrays.copyOf(Arrays.java:3326) at java.lang.AbstractStringBuilder.expandCapacity(AbstractStringBuilder.java:137) at java.lang.AbstractStringBuilder.ensureCapacityInternal(AbstractStringBuilder.java:121) at java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:569) at java.lang.StringBuilder.append(StringBuilder.java:190) at org.apache.commons.io.output.StringBuilderWriter.write(StringBuilderWriter.java:138) at org.apache.commons.io.IOUtils.copyLarge(IOUtils.java:2002) at org.apache.commons.io.IOUtils.copyLarge(IOUtils.java:1980) at org.apache.commons.io.IOUtils.copy(IOUtils.java:1957) at org.apache.commons.io.IOUtils.copy(IOUtils.java:1907) at org.apache.commons.io.IOUtils.toString(IOUtils.java:778) at com.nurkiewicz.gpx.GpxTransformation.loadWaypoints(GpxTransformation.java:56) at com.nurkiewicz.gpx.GpxTransformation.transform(GpxTransformation.java:50) |
loadWaypoints охотно загружает input файл GPX в String (см .: IOUtils.toString(input, UTF_8) ), чтобы позже проанализировать его. Это довольно глупо, тем более что JAXB Unmarshaller может легко читать InputStream напрямую. Давайте исправим это:
|
1
2
3
4
5
6
7
8
9
|
private List<Gpx.Wpt> loadWaypoints(InputStream input) throws JAXBException, IOException { final Unmarshaller unmarshaller = jaxbContext.createUnmarshaller(); final Gpx gpx = (Gpx) unmarshaller.unmarshal(input); return gpx.getWpt();}private void dumpJson(List<LatLong> coordinates, OutputStream output) throws IOException { jsonMapper.writeValue(output, coordinates);} |
Точно так же мы исправили dumpJson как он сначала dumpJson JSON в String а затем копировал эту String в OutputStream . Результаты немного лучше, но снова 1 GiB терпит неудачу, на этот раз, входя в бесконечный цикл смерти Full GC и, наконец, выбрасывая:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
java.lang.OutOfMemoryError: Java heap space at com.sun.xml.internal.bind.v2.runtime.unmarshaller.LeafPropertyLoader.text(LeafPropertyLoader.java:50) at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallingContext.text(UnmarshallingContext.java:527) at com.sun.xml.internal.bind.v2.runtime.unmarshaller.SAXConnector.processText(SAXConnector.java:208) at com.sun.xml.internal.bind.v2.runtime.unmarshaller.SAXConnector.endElement(SAXConnector.java:171) at com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.endElement(AbstractSAXParser.java:609) [...snap...] at com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl$JAXPSAXParser.parse(SAXParserImpl.java:649) at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallerImpl.unmarshal0(UnmarshallerImpl.java:243) at com.sun.xml.internal.bind.v2.runtime.unmarshaller.UnmarshallerImpl.unmarshal(UnmarshallerImpl.java:214) at javax.xml.bind.helpers.AbstractUnmarshallerImpl.unmarshal(AbstractUnmarshallerImpl.java:157) at javax.xml.bind.helpers.AbstractUnmarshallerImpl.unmarshal(AbstractUnmarshallerImpl.java:204) at com.nurkiewicz.gpx.GpxTransformation.loadWaypoints(GpxTransformation.java:54) at com.nurkiewicz.gpx.GpxTransformation.transform(GpxTransformation.java:47) |
Шаг 2: (плохо) замена JAXB на StAX
Мы можем подозревать, что основной проблемой сейчас является синтаксический анализ XML с использованием JAXB, который всегда охотно отображает весь XML-файл в объекты Java. Легко представить, почему не удается преобразовать файл размером 1 ГБ в граф объектов. Мы хотели бы как-то взять больше контроля над чтением XML и его потреблением по частям. SAX традиционно использовался в таких обстоятельствах, однако модель push-программирования в SAX API очень неудобна. SAX использует механизм обратного вызова, который очень инвазивен и не очень удобочитаем. StAX (Streaming API for XML) , работающий на несколько более высоком уровне, предоставляет модель pull. Это означает, что клиентский код решает, когда и сколько потреблять входных данных. Это дает нам лучший контроль над вводом и обеспечивает большую гибкость. Чтобы познакомить вас с API, вот почти эквивалентный код loadWaypoints() , но я пропускаю атрибуты <wpt/> которые позже не нужны:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
private List<Gpx.Wpt> loadWaypoints(InputStream input) throws JAXBException, IOException, XMLStreamException { final XMLInputFactory factory = XMLInputFactory.newInstance(); final XMLStreamReader reader = factory.createXMLStreamReader(input); final List<Gpx.Wpt> waypoints = new ArrayList<>(); while (reader.hasNext()) { switch (reader.next()) { case XMLStreamConstants.START_ELEMENT: if (reader.getLocalName().equals("wpt")) { waypoints.add(parseWaypoint(reader)); } break; } } return waypoints;}private Gpx.Wpt parseWaypoint(XMLStreamReader reader) { final Gpx.Wpt wpt = new Gpx.Wpt(); final String lat = reader.getAttributeValue("", "lat"); if (lat != null) { wpt.setLat(new BigDecimal(lat)); } final String lon = reader.getAttributeValue("", "lon"); if (lon != null) { wpt.setLon(new BigDecimal(lon)); } return wpt;} |
Посмотрите, как мы явно запрашиваем XMLStreamReader для получения дополнительных данных? Однако тот факт, что мы используем более низкоуровневый API (и намного больше кода), не означает, что он должен быть лучше, если используется неправильно. Мы продолжаем строить огромный список waypoints , поэтому неудивительно, что мы снова видим OutOfMemoryError :
|
1
2
3
4
5
6
7
8
9
|
java.lang.OutOfMemoryError: Java heap space at java.util.Arrays.copyOf(Arrays.java:3204) at java.util.Arrays.copyOf(Arrays.java:3175) at java.util.ArrayList.grow(ArrayList.java:246) at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:220) at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:212) at java.util.ArrayList.add(ArrayList.java:443) at com.nurkiewicz.gpx.GpxTransformation.loadWaypoints(GpxTransformation.java:65) at com.nurkiewicz.gpx.GpxTransformation.transform(GpxTransformation.java:52) |
Именно там, где мы ожидали. Хорошей новостью является то, что тест 1 ГиБ пройден (с кучей 1 ГиБ), поэтому мы как бы движемся в правильном направлении. Но это заняло 1 минуту, чтобы закончить из-за чрезмерного GC.
Шаг 3: StAX реализован правильно
Обратите внимание, что реализация с использованием StAX в предыдущем примере будет столь же хороша с SAX. Однако причина, по которой я выбрал StAX, заключалась в том, что теперь мы можем превратить файл XML в Iterator<Gpx.Wpt> . Этот итератор будет использовать XML-файл кусками, лениво и только по запросу. Позже мы также можем использовать этот итератор лениво, что означает, что мы больше не храним весь файл в памяти. Итераторы, хотя и неуклюжи для работы, все же намного лучше, чем работа с XML напрямую или с обратными вызовами SAX:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
import com.google.common.collect.AbstractIterator;private Iterator<Gpx.Wpt> loadWaypoints(InputStream input) throws JAXBException, IOException, XMLStreamException { final XMLInputFactory factory = XMLInputFactory.newInstance(); final XMLStreamReader reader = factory.createXMLStreamReader(input); return new AbstractIterator<Gpx.Wpt>() { @Override protected Gpx.Wpt computeNext() { try { return tryPullNextWaypoint(); } catch (XMLStreamException e) { throw Throwables.propagate(e); } } private Gpx.Wpt tryPullNextWaypoint() throws XMLStreamException { while (reader.hasNext()) { int event = reader.next(); switch (event) { case XMLStreamConstants.START_ELEMENT: if (reader.getLocalName().equals("wpt")) { return parseWaypoint(reader); } break; case XMLStreamConstants.END_ELEMENT: if (reader.getLocalName().equals("gpx")) { return endOfData(); } break; } } throw new IllegalStateException("XML file didn't finish with </gpx> element, malformed?"); } };} |
Это становится сложным! Я использую AbstractIterator из Guava для обработки утомительного состояния hasNext() . Каждый раз, когда кто-то пытается Gpx.Wpt следующий элемент Gpx.Wpt из итератора (или вызвать hasNext() ), мы потребляем немного XML, и этого достаточно, чтобы вернуть одну запись. Если XMLStreamReader встречает конец XML ( </gpx> ), мы сообщаем об окончании итератора, возвращая endOfData() . Это очень удобный шаблон, где XML читается лениво и подается через удобный итератор. Эта реализация сама по себе потребляет очень мало постоянного объема памяти. Однако мы изменили API с List<Gpx.Wpt> на Iterator<Gpx.Wpt> , что Iterator<Gpx.Wpt> изменения в остальной части нашей реализации:
|
01
02
03
04
05
06
07
08
09
10
|
private static List<LatLong> toCoordinates(Iterator<Gpx.Wpt> waypoints) { final Spliterator<Gpx.Wpt> spliterator = Spliterators.spliteratorUnknownSize(waypoints, Spliterator.ORDERED); return StreamSupport .stream(spliterator, false) .filter(wpt -> wpt.getLat() != null) .filter(wpt -> wpt.getLon() != null) .map(LatLong::new) .collect(toList());} |
toCoordinates() ранее принимал List<Gpx.Wpt> . Итераторы нельзя превратить в Stream напрямую, поэтому нам нужно это неуклюжее преобразование через Spliterator . Вы думаете, что все кончено? ! Тест GiB проходит немного быстрее, но более требовательные тесты не проходят, как и раньше:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
java.lang.OutOfMemoryError: Java heap space at java.util.Arrays.copyOf(Arrays.java:3175) at java.util.ArrayList.grow(ArrayList.java:246) at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:220) at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:212) at java.util.ArrayList.add(ArrayList.java:443) at java.util.stream.ReduceOps$3ReducingSink.accept(ReduceOps.java:169) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.Iterator.forEachRemaining(Iterator.java:116) at java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:512) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:502) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at com.nurkiewicz.gpx.GpxTransformation.toCoordinates(GpxTransformation.java:118) at com.nurkiewicz.gpx.GpxTransformation.transform(GpxTransformation.java:58) at com.nurkiewicz.LargeInputSpec.Should not fail with OOM for input of size #readableBytes(LargeInputSpec.groovy:49) |
Помните, что OutOfMemoryError не всегда выбрасывается из места, которое фактически потребляет большую часть памяти. К счастью, на этот раз это не так. Посмотрите внимательно на дно: collect(toList()) .
Шаг 4: Как избежать потоков и сборщиков
Это разочаровывает. Потоки и коллекторы были спроектированы с нуля, чтобы поддерживать лень. Однако практически невозможно реализовать сборщик (см. Также: Введение в написание пользовательских сборщиков в Java 8 и группирование, выборка и пакетирование — настраиваемые сборщики ) из эффективного потока в итератор, что является большим недостатком проекта. Поэтому мы должны полностью забыть о потоках и использовать простые итераторы до конца. Итераторы не очень изящны, но позволяют потреблять входной элемент за элементом, имея полный контроль над потреблением памяти. Нам нужен способ filter() входного итератора, отбрасывающего битые элементы и записи map() в другое представление. Guava, опять же, предоставляет несколько удобных утилит для этого, полностью заменив stream() :
|
1
2
3
4
5
6
7
|
private static Iterator<LatLong> toCoordinates(Iterator<Gpx.Wpt> waypoints) { final Iterator<Gpx.Wpt> filtered = Iterators .filter(waypoints, wpt -> wpt.getLat() != null && wpt.getLon() != null); return Iterators.transform(filtered, LatLong::new);} |
Iterator<Gpx.Wpt> в, Iterator<LatLong> в. Обработка не производилась, файл XML почти не затрагивался, предельное потребление памяти. Нам повезло, Джексон принимает итераторы и прозрачно читает их, создавая JSON итеративно. Таким образом, потребление памяти также остается низким. Угадайте, что мы сделали это!
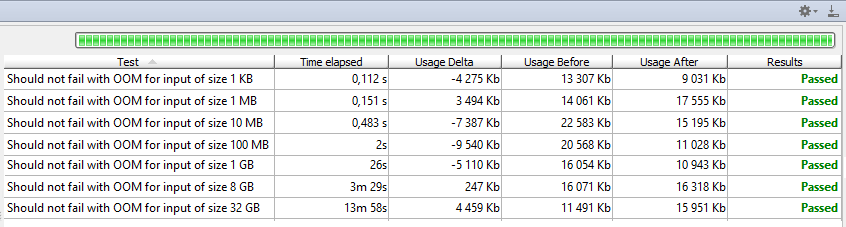
Потребление памяти низкое и стабильное, я думаю, мы можем с уверенностью предположить, что оно постоянно. Наш код обрабатывает около 40 МБ / с, поэтому не удивляйтесь, что почти 14 минут потребовалось для обработки 32 ГБ. О, и я упоминал, что я запускаю последний тест с -Xmx32M ? Правильно, обработка 32 ГиБ прошла успешно без потери производительности, используя в тысячи раз меньше памяти. И в 3000 раз меньше, по сравнению с первоначальной реализацией. По сути, последнее решение с использованием итераторов способно обрабатывать даже бесконечные потоки XML. Это не просто теоретический случай, представьте себе потоковый API, который создает бесконечный поток сообщений …
Окончательная реализация
Это наш код в целом:
|
001
002
003
004
005
006
007
008
009
010
011
012
013
014
015
016
017
018
019
020
021
022
023
024
025
026
027
028
029
030
031
032
033
034
035
036
037
038
039
040
041
042
043
044
045
046
047
048
049
050
051
052
053
054
055
056
057
058
059
060
061
062
063
064
065
066
067
068
069
070
071
072
073
074
075
076
077
078
079
080
081
082
083
084
085
086
087
088
089
090
091
092
093
094
095
096
097
098
099
100
101
102
103
104
105
|
package com.nurkiewicz.gpx;import com.google.common.base.Throwables;import com.google.common.collect.AbstractIterator;import com.google.common.collect.Iterators;import com.topografix.gpx._1._0.Gpx;import org.codehaus.jackson.map.ObjectMapper;import javax.xml.bind.JAXBException;import javax.xml.stream.XMLInputFactory;import javax.xml.stream.XMLStreamConstants;import javax.xml.stream.XMLStreamException;import javax.xml.stream.XMLStreamReader;import java.io.BufferedInputStream;import java.io.BufferedOutputStream;import java.io.File;import java.io.FileInputStream;import java.io.FileOutputStream;import java.io.IOException;import java.io.InputStream;import java.io.OutputStream;import java.math.BigDecimal;import java.util.Iterator;public class GpxTransformation { private static final ObjectMapper jsonMapper = new ObjectMapper(); public void transform(File inputFile, File outputFile) throws JAXBException, IOException, XMLStreamException { try ( InputStream input = new BufferedInputStream(new FileInputStream(inputFile)); OutputStream output = new BufferedOutputStream(new FileOutputStream(outputFile))) { transform(input, output); } } public void transform(InputStream input, OutputStream output) throws JAXBException, IOException, XMLStreamException { final Iterator<Gpx.Wpt> waypoints = loadWaypoints(input); final Iterator<LatLong> coordinates = toCoordinates(waypoints); dumpJson(coordinates, output); } private Iterator<Gpx.Wpt> loadWaypoints(InputStream input) throws JAXBException, IOException, XMLStreamException { final XMLInputFactory factory = XMLInputFactory.newInstance(); final XMLStreamReader reader = factory.createXMLStreamReader(input); return new AbstractIterator<Gpx.Wpt>() { @Override protected Gpx.Wpt computeNext() { try { return tryPullNextWaypoint(); } catch (XMLStreamException e) { throw Throwables.propagate(e); } } private Gpx.Wpt tryPullNextWaypoint() throws XMLStreamException { while (reader.hasNext()) { int event = reader.next(); switch (event) { case XMLStreamConstants.START_ELEMENT: if (reader.getLocalName().equals("wpt")) { return parseWaypoint(reader); } break; case XMLStreamConstants.END_ELEMENT: if (reader.getLocalName().equals("gpx")) { return endOfData(); } break; } } throw new IllegalStateException("XML file didn't finish with </gpx> element, malformed?"); } }; } private Gpx.Wpt parseWaypoint(XMLStreamReader reader) { final Gpx.Wpt wpt = new Gpx.Wpt(); final String lat = reader.getAttributeValue("", "lat"); if (lat != null) { wpt.setLat(new BigDecimal(lat)); } final String lon = reader.getAttributeValue("", "lon"); if (lon != null) { wpt.setLon(new BigDecimal(lon)); } return wpt; } private static Iterator<LatLong> toCoordinates(Iterator<Gpx.Wpt> waypoints) { final Iterator<Gpx.Wpt> filtered = Iterators .filter(waypoints, wpt -> wpt.getLat() != null && wpt.getLon() != null); return Iterators.transform(filtered, LatLong::new); } private void dumpJson(Iterator<LatLong> coordinates, OutputStream output) throws IOException { jsonMapper.writeValue(output, coordinates); }} |
Резюме (TL; DR)
Если вы недостаточно терпеливы, чтобы выполнить все шаги, вот три основных вывода:
- Ваша первая цель — простота . Первоначальная реализация JAXB была идеальной (с небольшими изменениями), сохраните ее, если ваш код не должен обрабатывать большие входные данные.
- Протестируйте свой код на безумно больших входных данных , например, используя сгенерированный
InputStream, производя гигабайты ввода Огромный набор данных является еще одним примером крайнего случая. Не проверяйте вручную, один раз. Одно неосторожное изменение или «улучшение» может испортить вашу производительность в будущем. - Оптимизация не является оправданием для написания плохого кода . Обратите внимание, что наша реализация по-прежнему является составной и простой в использовании. Если бы мы прошли SAX и просто указали всю логику в обратных вызовах SAX, ремонтопригодность сильно пострадала бы.
| Ссылка: | Тестирование кода для чрезмерно больших входных данных от нашего партнера JCG Томаша Нуркевича в блоге Java и соседстве . |