После первого сообщения о клиентах HTTP , к которому я перенаправляю вас для ознакомления с эффективным HTTP на JVM, давайте теперь поговорим о серверах HTTP.
Существует несколько тестов для HTTP-серверов, но им часто мешают такие недостатки, как:
- Неэффективное использование сценариев с высокой степенью параллелизма и, в более общем плане, рассмотрение нереалистичных и непредставительных сценариев, например:
- Сценарий с чисто накладными расходами , когда обработка запросов в основном равна нулю (на практике всегда есть некоторая обработка, которую нужно выполнить).
- Сценарий максимального параллелизма , где ожидающие запросы не могут превышать заданный лимит, и генератор нагрузки будет ждать, когда он будет достигнут (в действительности клиенты HTP не прекращают запуск новых запросов только потому, что заданное число их еще выполняется).
- Реально не подключать, изолировать и / или определять размеры процессов формирования нагрузки и нагрузки.
- Не назначать сопоставимые системные ресурсы для загрузки целей.
- Не включая достаточно широкий диапазон подходов (например, концентрируясь только на «синхронизирующих» или «асинхронных» серверах).
- Не анализируя данные для получения результатов .
Мы собираемся проанализировать новые критерии, которые пытались решить вышеупомянутые проблемы и которые дали очень интересные и иногда неожиданные результаты:
- Синхронные, блокирующие потоки серверы Jetty и Undertow также могут эффективно использоваться в сценариях с высокой степенью параллелизма, при условии, что запросы не очень долговечны.
- Когда запросы должны оставаться активными в течение очень длительного времени (например, длительный опрос, продвижение сервера), асинхронные серверы и серверы, использующие волокна Quasar, могут поддерживать гораздо больше одновременно активных запросов.
- Асинхронные API-интерфейсы значительно сложнее, в то время как волокна являются прямыми (так же, как и традиционные блокирующие потоки) и работают очень хорошо не только в сценариях с высоким параллелизмом, но и в широком спектре случаев.
Тесты и генераторы нагрузки
Сценарии с высокой степенью параллелизма стали важным примером использования и оценки. Они могут быть результатом длительных запросов из-за определенной функциональности (например, чатов) и / или, иногда, нежелательной технической ситуации (например, «медитативный» уровень данных).
Используемый генератор нагрузки, как и прежде , является jbender Pinterest, который в свою очередь основан на HTTP-клиентах Quasar и Comsat . Благодаря волокнам Quasar jbender поддерживает множество одновременных запросов даже от одного узла, прекрасный синхронный API и, будучи платформой для нагрузочного тестирования, а не одним инструментом, обеспечивает большую гибкость и удобство (включая, например, проверку ответов).
Цели загрузки служат минимальным «привет» HTTP-ответом 1 после ожидания, специфичного для эталонного теста, что является очень простым способом проверки параллелизма: чем дольше ожидание, тем больше длительность запроса и уровень параллелизма, который должен поддерживать целевой объект загрузки, чтобы чтобы избежать очередей запросов.
Что касается случаев загрузки, только первый эталонный тест является максимальным параллелизмом, и он имеет единственную цель измерить фактическое максимальное количество запросов, которые могут быть обработаны одновременно; это делается путем запуска максимально возможного количества запросов и их ожидания в течение очень долгого времени. Все остальные варианты загрузки имеют целевую частоту , что означает, что они измеряют поведение целей загрузки с некоторой целевой частотой запросов независимо от того, могут ли они (или не могут) отправлять запросы достаточно быстро 2 . Ниже приведено более подробное описание:
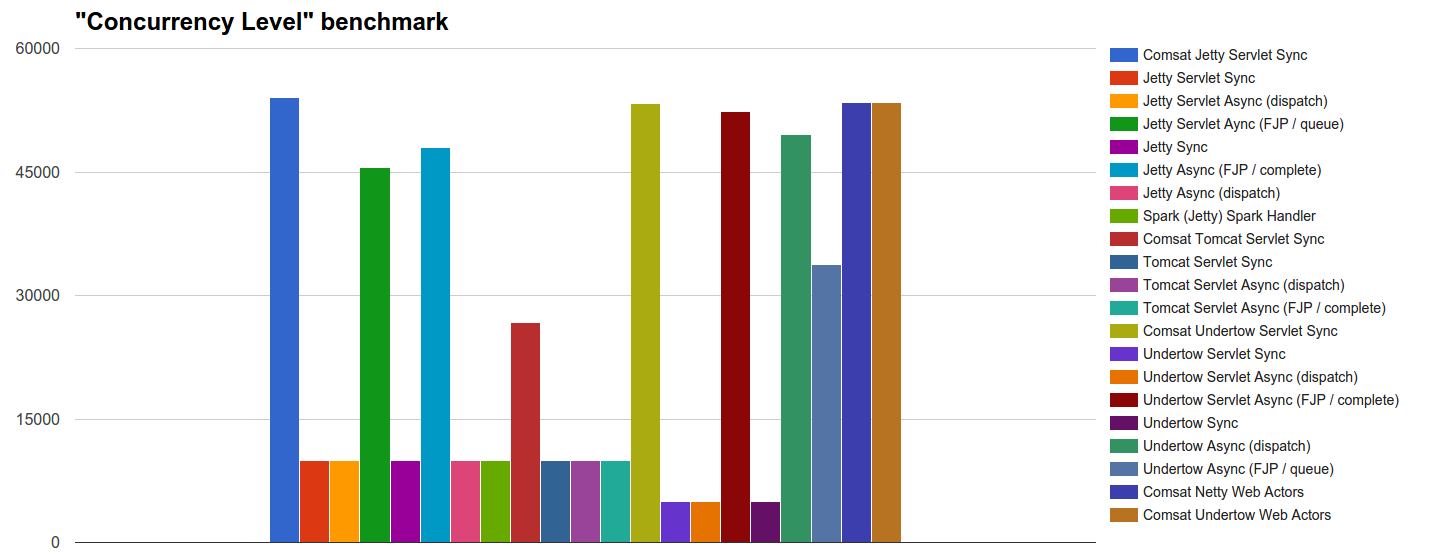
- Уровень параллелизма : мы проверяем, сколько из 54k одновременных входящих запросов каждый сервер может начать обрабатывать.
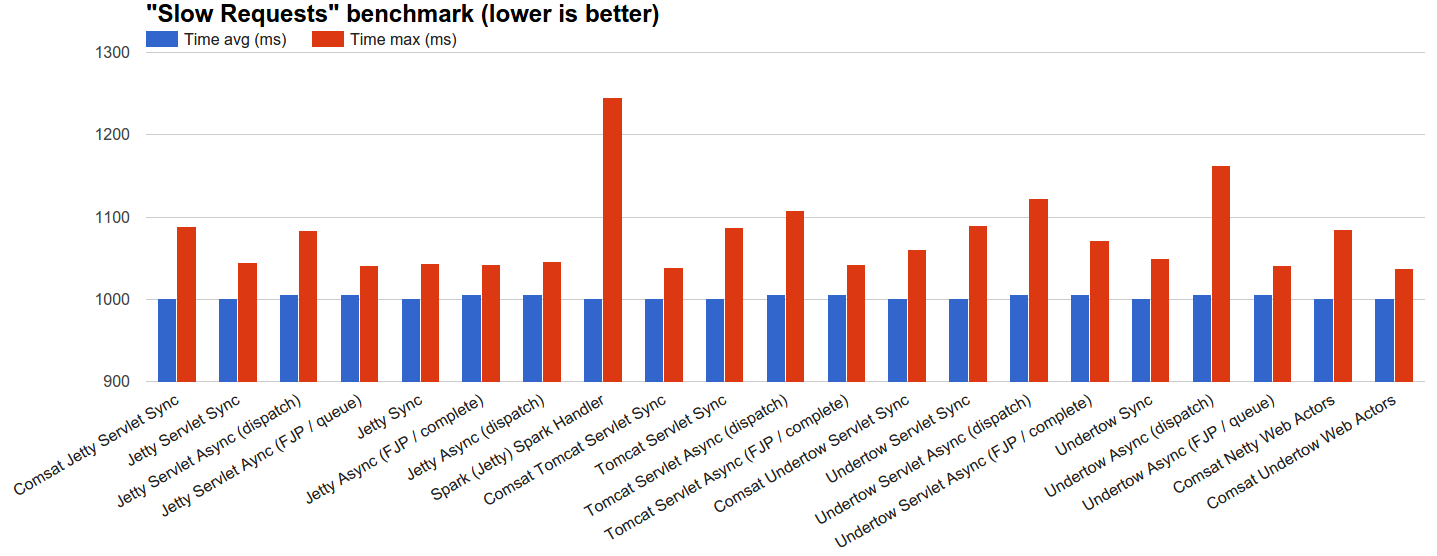
- Медленные запросы : мы позволяем серверам обрабатывать 100 000 запросов, распределенных с использованием генератора экспоненциальных интервалов JBender с целевой скоростью 1 000 об / с, где каждый запрос ждет 1 с, а затем завершается. Обоснование состоит в том, чтобы увидеть, как каждый сервер ведет себя при разумной нагрузке одновременных медленных запросов.
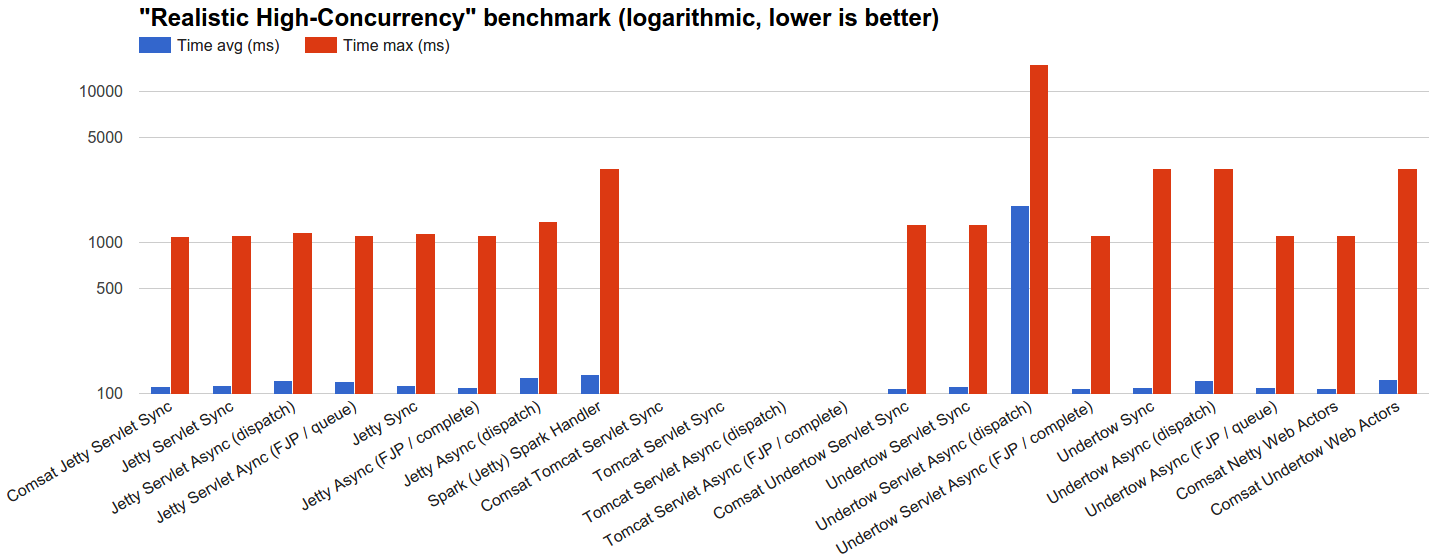
- Реалистичный высокий параллелизм : мы позволяем серверам обрабатывать 100 тыс. Запросов, распределенных с использованием генератора экспоненциальных интервалов JBender с целью 10 тыс. Оборотов в секунду, где каждый запрос ожидает 100 мс, а затем завершается. Обоснование состоит в том, чтобы увидеть, как каждый сервер ведет себя при высокой нагрузке одновременных запросов со временем жизни, которое может разумно представлять некоторый OLTP .
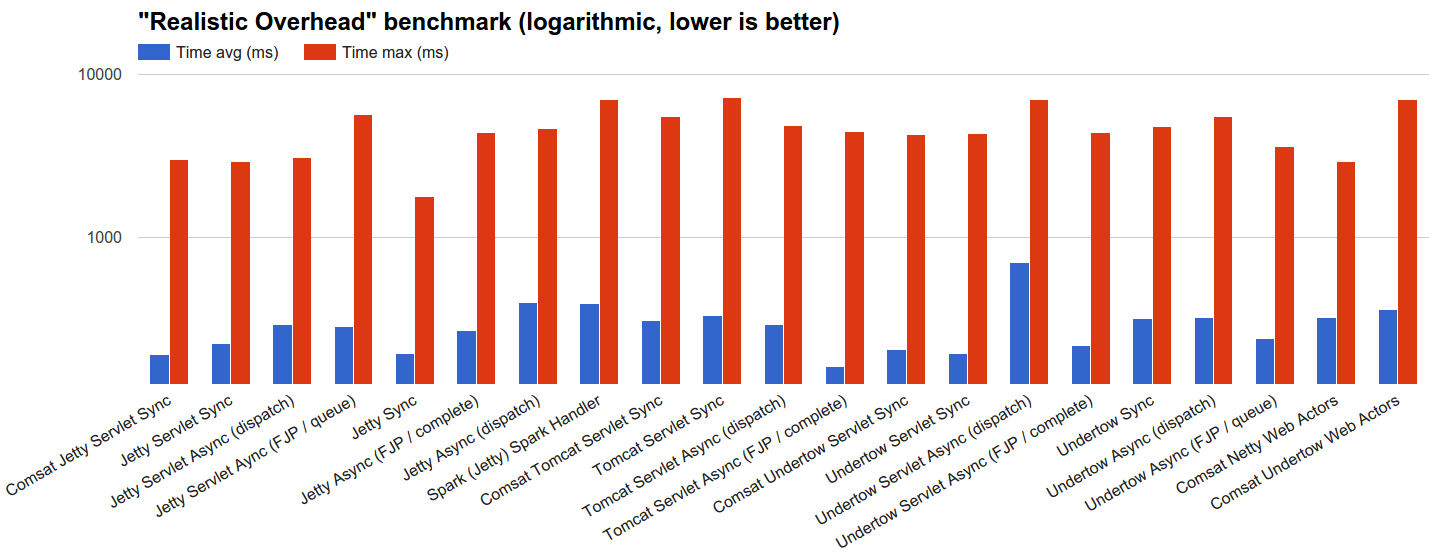
- (Немного больше) Реалистичные издержки : мы позволяем серверам обрабатывать 100 тыс. Запросов, распределенных с использованием генератора экспоненциальных интервалов JBender с целью 100 тыс. Оборотов в секунду, где каждый запрос завершается немедленно: посмотрим, как каждый сервер ведет себя при довольно серьезном потоке входящих запросов с нет времени обработки вообще. Поскольку сеть настолько быстра, насколько это возможно (см. Следующий раздел), но на самом деле есть (и это не
localhost), обоснование этого теста заключается в проверке влияния на производительность реалистичных издержек обработки запросов, которые всегда включают (в в лучшем случае) быстрая сеть и быстрая ОС (и, конечно, программный стек сервера).
Поскольку мы тестируем серверы JVM, а HotSpot JVM включает в себя оптимизирующий компилятор с профилем JIT , перед тестами 2-4, приведенными выше, я всегда выполняю предварительный прогон 100k запросов на фиксированном уровне параллелизма, равном 1000 запросов. Каждый рисунок — лучший результат 10 прогонов, в которых ни цель загрузки, ни генератор нагрузки не были остановлены, чтобы дать JVM наилучшие шансы для оптимизации путей кода.
Генератор нагрузки JBender, основанный на comsat-httpclient (который основан на асинхронном HTTP-клиенте Apache 4.1 ), использовался для тестов 1, 2 и 3, а также для циклов прогрева, в то время как для comsat-okhttp (построен на асинхронном языке OkHttp 2.6 ) , который имеет тенденцию работать лучше с короткими запросами, был использован для теста 4. Оба были настроены следующим образом:
- Нет попыток.
- 1 час чтения / записи.
- Максимальный размер пула соединений.
- Количество рабочих потоков равно количеству ядер.
- Файлы cookie отключены, поэтому каждый запрос относится к вновь созданному сеансу 3 .
системы
Были приняты некоторые системные меры предосторожности:
- Мы не хотим, чтобы генератор нагрузки и серверные процессы крали ресурсы друг у друга, поэтому их необходимо разделять до степени, достаточной для достижения изоляции ресурсов.
- Мы не хотим, чтобы генератор нагрузки стал узким местом, поэтому безопаснее всего позволить ему использовать большое количество ресурсов (относительно сервера) и лучшие настройки производительности JVM (что, конечно же, мы хотим и для серверов).
- Мы хотим, чтобы сеть была фактически там, чтобы мы имитировали реалистичный сценарий, но мы также хотим, чтобы она была максимально быстрой, чтобы она также не стала узким местом.
Следующая среда тестирования AWS была настроена с учетом вышеуказанных соображений:
- Загрузить цель :
- AWS EC2 Linux m4.large (8 ГБ, 2 vcpus, умеренная производительность сети с расширенными сетевыми возможностями)
- Oracle JDK 1.8.0_b72 со следующими флагами:
|
1
2
3
4
5
|
-server-XX:+AggressiveOpts-XX:+DisableExplicitGC-XX:+HeapDumpOnOutOfMemoryError-Xms4G -Xmx4G |
- Генератор нагрузки :
- AWS EC2 Linux m4.xlarge (16 ГБ, 4 vcpus, высокая производительность сети с улучшенной сетью)
- Oracle JDK 1.8.0_b72 со следующими флагами:
|
1
2
3
4
5
|
-server-XX:+AggressiveOpts-XX:+DisableExplicitGC-XX:+HeapDumpOnOutOfMemoryError-Xms12G -Xmx12G -XX:+UseG1GC -XX:MaxGCPauseMillis=10 |
«M» виртуальных экземпляров AWS EC2 предназначены для обеспечения более предсказуемой производительности по сравнению с некоторыми другими типами, такими как «t».
Внутренняя сеть AWS несла эталонную нагрузку, и экземпляры находились в одном и том же регионе и в одной зоне доступности для обеспечения наилучшего подключения.
Несколько замечаний о настройках JVM:
- Генераторы нагрузки использовали кучи памяти 12 ГБ; сборщик мусора G1, который пытается минимизировать паузы и поддерживать высокую пропускную способность, становится жизнеспособным вариантом, превышающим кучу 6 ГБ, и используется для минимизации дрожания во время генерации нагрузки.
- Для целей загрузки использовалась куча 4 ГБ памяти; это удобная сумма, но ее недостаточно, чтобы воспользоваться преимуществами G1, поэтому вместо нее был использован сборщик, оптимизирующий пропускную способность по умолчанию. Обоснованием является представление серверных сред, в которых доступность памяти адекватна, но, тем не менее, несколько ограничена (например, по причинам стоимости, например, из парка облачных серверов).
Настройка ОС Linux была выполнена как на генераторе нагрузки, так и на серверных системах на основе небольшого отклонения от рекомендаций JBender .
Загрузите цели и загрузите код генераторов
Код этих тестов был изначально разветвлен от jemper’а jempower , представленного в недавнем посте о тестах , который в свою очередь взят из TechEmpower . Он был преобразован в многомодульный проект Gradle с полной JVM, использующий в качестве средства запуска Capsule вместо сценариев.
Код также был существенно реорганизован для того, чтобы отделить обработчики от серверных технологий и от целей загрузки, каждый из которых интегрирует обработчик с технологией, поддерживающей его API. Он также был переработан, чтобы разделить как можно больше логики и настроек.
Я также добавил больше целей загрузки для синхронных API-интерфейсов, блокирующих потоки и Comsat (волоконно-блокирующие блоки), а также интересные асинхронные варианты, и я удалил цель Kilim, поскольку библиотека, кажется, не поддерживается.
Соответствие API и серверные технологии: целевые показатели нагрузки
Тесты охватывают несколько целей загрузки на основе ряда API и серверных технологий:
- Стандартный синхронный JEE Servlet API на следующих серверных технологиях:
- Undertow
1.3.15.Final - Причал
9.3.6.v20151106 - Tomcat
8.0.30 - Синхронизирующие волоконные сервлеты Comsat
0.7.0-SNAPSHOT(без изменений, начиная со стабильной0.6.0), которые реализованы поверх асинхронного API Servlet и могут работать в любом контейнере сервлета 3.0. Они были запущены на всех вышеперечисленных серверных технологиях.
- Undertow
- Стандартный асинхронный API сервлетов JEE (
startAsync& friends, 3.0+) с исполнителями, предоставленными контейнерами (dispatch), и исполнителями, предоставленными пользователями (complete) на тех же серверных технологиях, упомянутых выше. - Нестандартизированный Comsat Web Actors API
0.7.0-SNAPSHOT(0.6.0с дальнейшими исправлениями и улучшениями веб-участников), который присоединяет входящие (запрос) и исходящие (ответ) очереди к реальным облегченным последовательным процессам (волокнам), которые получают входящие запросы. и отправлять ответы с помощью простых, синхронных и эффективных (в частности, волоконно-оптических, а не блокирующих потоков) операцийreceiveиsend. Эти процессы являются полноценными актерами в стиле эрланга 4 . В настоящее время Web Actors могут работать в контейнере сервлетов как обработчик Undertow, а также как собственный обработчик Netty ; нативные развертывания Netty и Undertow были включены в тест. Версия Netty была4.0.34.Finalи Undertow такая же, как и выше. - Нестандартизированные встроенные API Jetty , как sync, так и async 5 , на той же Jetty, что и выше.
- Нестандартизированные API-обработчики Undertow , как синхронизирующие, так и асинхронные, в том же Undertow, что и выше.
- Нестандартные API-интерфейсы Spark-сервера / обработчика
2.3использующие Jetty9.3.2.v20150730.
Обработчики синхронизации — самые простые: они будут выполнять всю обработку запросов в том же потоке ОС (или, когда Comsat используется, оптоволокно ), который его запустил. Ожидание перед ответом реализуется через простой поток (или оптоволоконный) спящий режим.
Асинхронные обработчики являются более сложными, потому что они откладывают завершение запроса и должны выполнять дополнительную работу по бухгалтерскому учету и планированию. Все они начнутся с немедленного сохранения ожидающего запроса в статическом массиве, откуда они впоследствии будут выбраны для обработки с помощью TimerTask запланированного каждые 10 мс, и в этот момент стратегия отличается в зависимости от обработчика:
- Асинхронные обработчики, использующие
dispatch, планируют задание обработки запроса для предоставленного сервером исполнителя. Когда время ожидания не равно 0, оно реализуется через простой спящий поток. - Другие асинхронные обработчики не полагаются на серверных исполнителей и запускают обработку запросов, используя различные стратегии, как показано ниже. Если время ожидания не равно 0, все они будут дополнительно отправлять задание на выполнение
ScheduledExecutorService: это имитирует полностью неблокирующую реализацию, где внешние (например, DB, микро-сервисы и т. Д.) Вызовы выполняются через асинхронный API. также. Максимальный номер потока вScheduledExecutorбудет таким же, как и у предоставленного сервером исполнителя.- FJP : задание обработки запроса отправляется в пул разветвленного соединения с настройками по умолчанию.
- Очередь : пакет, содержащий все ожидающие запросы, будет вставлен в очередь, непрерывно
pollтремя потоками, каждый из которых будет последовательно обрабатывать полученный пакет.
Веб-субъекты «на сеанс» нацелены на порождение одного субъекта на сеанс, и, поскольку файлы cookie отключены, это означает, что каждый запрос обрабатывается другим субъектом, поддерживаемым его собственным волокном 6 .
Настройки ресурса HTTP-сервера смещены в сторону технологий синхронизации на основе потоков, которые могут использовать гораздо больше потоков ОС, чем асинхронные / оптоволоконные: это потому, что на самом деле вы были бы вынуждены сделать это, если бы вы использовали их в высоком параллелизме сценарий. Кроме того, одни и те же настройки HTTP-сервера были использованы как можно более равномерно:
- Синхронные и асинхронные серверы, использующие
dispatch, использовали максимум 5 тыс. Потоков ввода-вывода плюс 5 тыс. Рабочих потоков в Undertow, где проводится это различие, и 10 тыс. Общих потоков обработки в Tomcat, Jetty и Spark. - Другие асинхронные серверы, работающие на Tomcat, Jetty и Netty, использовали максимум 100 потоков обработки.
- Другие асинхронные серверы, работающие в Undertow, могут использовать максимум 50 потоков ввода-вывода и 50 рабочих потоков.
- Очередь принятия сокета (задержка AKA) может хранить не более 10 тыс. Соединений.
- Продолжительность сеанса 1 минута.
- Для Tomcat, Jetty, Netty и Undertow
TCP_NODELAYявно установлен в значениеtrue. - Для Jetty, Netty и Undertow
SO_REUSEADDRявно установлено в значениеtrue.
Данные
Вы можете получить доступ к электронной таблице тестов напрямую , вот статистика:
| Тесты HTTP-сервера | «Уровень параллелизма» | «Медленные запросы» | «Реалистичный высокий параллелизм» | «Реалистичные накладные расходы» | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Загрузить цель | Максимум | Ошибки # | Время в среднем (мс) | Максимальное время (мс) | Ошибки (#) | Время в среднем (мс) | Максимальное время (мс) | Ошибки (%) | Время в среднем (мс) | Максимальное время (мс) | Ошибки (#) |
| Comsat Jetty Servlet Sync | 54001 | 0 | 1000.777 | 1088.422 | 0 | 110,509 | 1103.102 | 0 | 189,742 | 3015.705 | 0 |
| Jetty Servlet Sync | 9997 | 0 | 1000.643 | 1044.382 | 0 | 112,641 | 1114.636 | 0 | 222,452 | 2936.013 | 0 |
| Jetty Servlet Async (отправка) | 9997 | 0 | 1005.828 | 1083.179 | 0 | 121,719 | 1173.357 | 0 | 289,229 | 3066.036 | 0 |
| Jetty Servlet Aync (FJP / очередь) | 45601 | 4435 | 1005.769 | 1041.236 | 0 | 119,819 | 1120.928 | 0 | 281,602 | 5700.059 | 0 |
| Jetty Sync | 9997 | 54 | 1000.645 | 1043.857 | 0 | 113,508 | 1143.996 | 0 | 193,487 | 1779.433 | 0 |
| Jetty Async (FJP / полная) | 47970 | 1909 | 1005.754 | 1041,76 | 0 | 109,067 | 1120.928 | 0 | 266,918 | 4408.214 | 0 |
| Jetty Async (отправка) | 9997 | 0 | 1005.773 | 1045,43 | 0 | 127,65 | 1385.169 | 0 | 397,948 | 4626.317 | 0 |
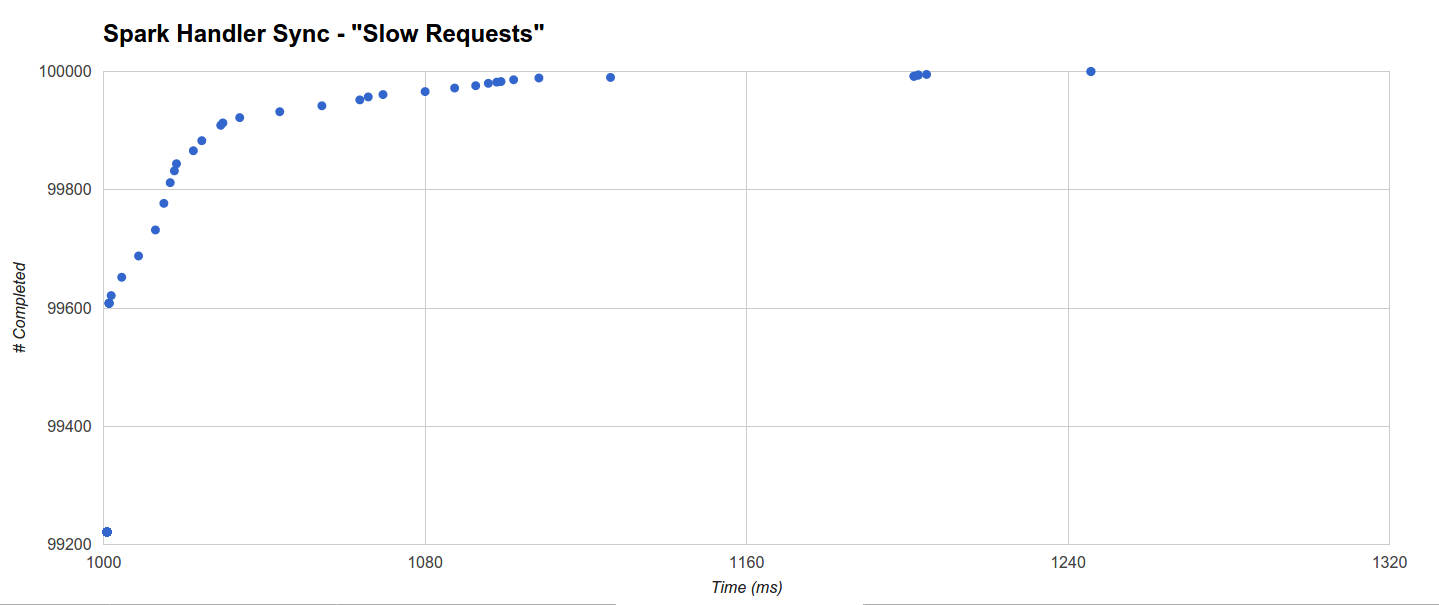
| Spark (Jetty) Spark Handler | 9997 | 58 | 1000.718 | 1245.708 | 0 | 134,482 | 3118.465 | 0 | 391,374 | 7021.265 | 0 |
| Comsat Tomcat Servlet Sync | 26682 | 13533 | 1000.636 | 1039.139 | 0 | N / A | N / A | N / A | 307,903 | 5523.898 | 0 |
| Tomcat Servlet Sync | 9999 | 0 | 1000.625 | 1087.373 | 0 | N / A | N / A | N / A | 329,06 | 7239.369 | 0 |
| Tomcat Servlet Async (отправка) | 9999 | 0 | 1005.986 | 1108.345 | 0 | N / A | N / A | N / A | 289,703 | 4886.364 | 0 |
| Tomcat Servlet Async (FJP / полный) | 9999 | 29965 | 1005.891 | 1041,76 | 0 | N / A | N / A | N / A | 159,501 | 4483.711 | 0 |
| Comsat Undertow Servlet Sync | 53351 | 0 | 1000.648 | 1060.635 | 0 | 107,757 | 1309.671 | 0 | 204,795 | 4273.996 | 0 |
| Синхронизация с сервлетом Undertow | 4999 | 7758 | 1000.723 | 1089,47 | 0 | 110,599 | 1319.109 | 0 | 193,436 | 4307,55 | 0 |
| Undertow Servlet Async (отправка) | 4999 | 576 | 1006.011 | 1123.025 | 0 | 1756.198 | 15183,38 | 83 | 697,811 | 6996.099 | 0 |
| Servlet Undertow Async (FJP / завершено) | 52312 | 1688 | 1005,81 | 1071.645 | 0 | 108,324 | 1113.588 | 0 | 214,423 | 4408.214 | 0 |
| Синхронизация Undertow | 4999 | 0 | 1000.644 | 1049.625 | 0 | 108,843 | 3114.271 | 0 | 316,991 | 4789.895 | 0 |
| Undertow Async (отправка) | 49499 | 4501 | 1005.742 | 1162.871 | 0 | 121,554 | 3116.368 | 0 | 318,306 | 5486,15 | 0 |
| Undertow Async (FJP / очередь) | 33720 | 0 | 1005.656 | 1040.712 | 0 | 109,899 | 1113.588 | 0 | 236,558 | 3632.267 | 0 |
| Comsat Netty Web Actors | 53448 | 0 | 1000.701 | 1085.276 | 0 | 107,697 | 1106.248 | 0 | 320,986 | 2917.138 | 0 |
| Comsat Undertow Web Actors | 53436 | 0 | 1000.674 | 1037.042 | 0 | 123,791 | 3118.465 | 0 | 358,97 | 7046.431 | 0 |
А вот и графики:
Полученные результаты
В основном это были ошибки «сброса соединения» (возможно, из-за замедления при приеме), хотя в крайних случаях из-за замедления обработки параллелизм превышал количество портов, доступных для сетевого интерфейса.
Некоторые специфичные для бенчмарка соображения:
- Уровень параллелизма : этот тест четко показывает, сколько запросов может действительно обрабатываться одновременно каждой целью нагрузки. Почти все не
dispatchасинхронные обработчики, а также обработчики Comsat позволяют запускать большинство запросов немедленно, кроме всех технологий на основе Tomcat. Другие технологии позволяют запускать как можно больше запросов, чем максимальный размер их пулов потоков: оставшиеся входящие запросы могут быть связаны с потоками-приемниками TCP, но не начнут обработку, пока некоторые потоки в пуле не станут свободными. - Медленные запросы : в этом сценарии вскоре достигается равновесие, когда в среднем 1000 потоков (или волокон) выполняются одновременно в течение всего времени тестирования. Здесь серверы синхронизации, как правило, работают лучше всего, в том числе сервлеты Comsat и веб-акторы, в то время как асинхронные технологии оплачивают накладные расходы за дополнительный механизм бухгалтерского учета.
- Реалистичный высокий уровень параллелизма : целевые объекты нагрузки подвергаются сильному давлению высокого уровня параллелизма в этом эталонном тесте, в котором асинхронные технологии и технологии Comsat работают хорошо, в то время как блокировка потоков,
dispatchи Tomcat отстают или даже имеют серьезные проблемы, не позволяющие идти в ногу. Заметными исключениями являются синхронные обработчики Jetty и Undertow, производительность которых очень хорошая, вероятно, из-за разумных стратегий управления соединениями, хотя причины не совсем очевидны, и потребуется дополнительное расследование. Цели загрузки Tomcat не прошли успешно эти тесты, и было бы интересно выяснить, что именно привело к зависанию ЦП при 0% загрузки ЦП после определенного количества выполненных запросов и целого ряда ошибок. - Реалистичные накладные расходы : целевые объекты загрузки просто должны отсылать ответы как можно скорее, потому что ждать нет. Асинхронные обработчики не используют
ScheduledExecutorв этом сценарии, и их предел пропускной способности определяется общими накладными расходами технологии.
Распределение времени выполнения запроса также поддерживает некоторые соображения: генераторы нагрузки этого теста использовали предоставленный JBender регистратор событий, основанный на HDRHistogram Джила Тене. Вы можете получить доступ к данным гистограммы напрямую .
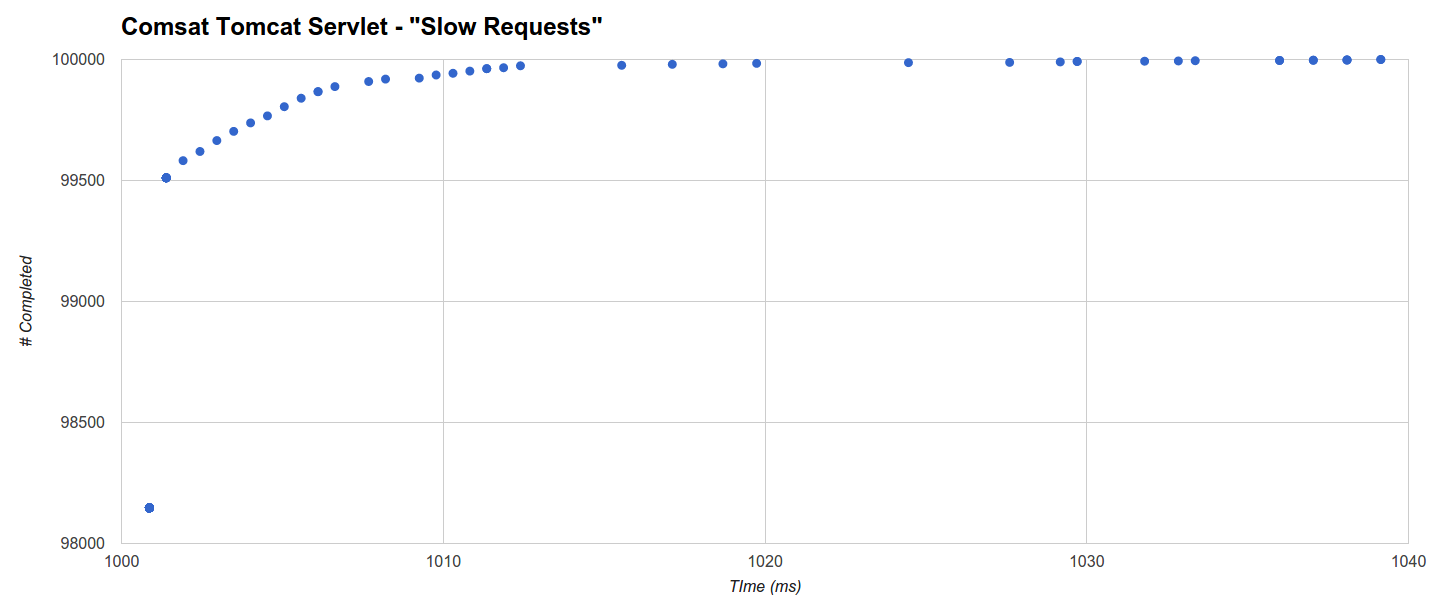
Гистограмма о минимальном максимальном времени для теста «Медленные запросы» показывает, что сервлет Tomcat Comsat (второй лучший) выполняет 98147 запросов из 100000 в течение 1 мс с абсолютного минимума 1 с (время ожидания), а время завершения оставшихся запросов распределяется между 1001,39 мс и 1039,139 мс (максимум):
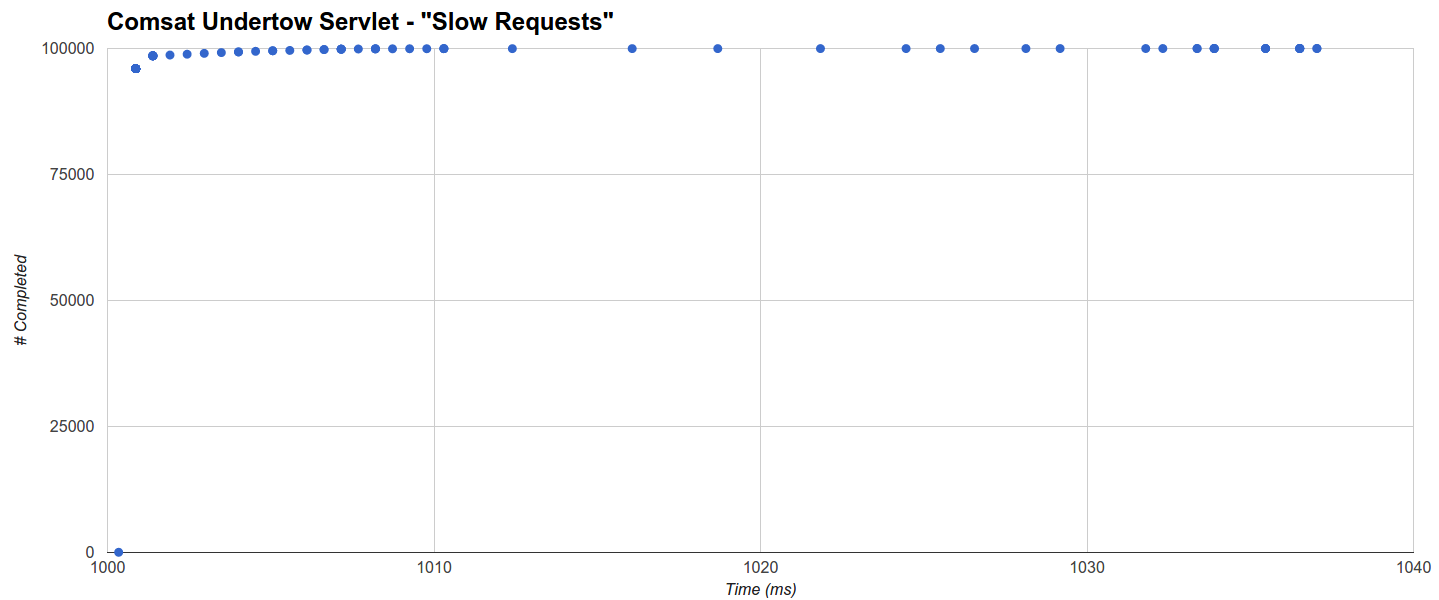
Сервлет Comsat Undertow имеет минимальную максимальную задержку, но в среднем он немного хуже, поскольку он выполняет около 96% запросов в течение 1001 мс, а остаток распределяется равномерно до 1037.042 мс (максимум):
С другой стороны, Spark (наихудший) имеет менее равномерное распределение: он выполняет еще больше за 1001мс (99221), но немногие другие запросы могут занять до 1245,708мс (максимум):
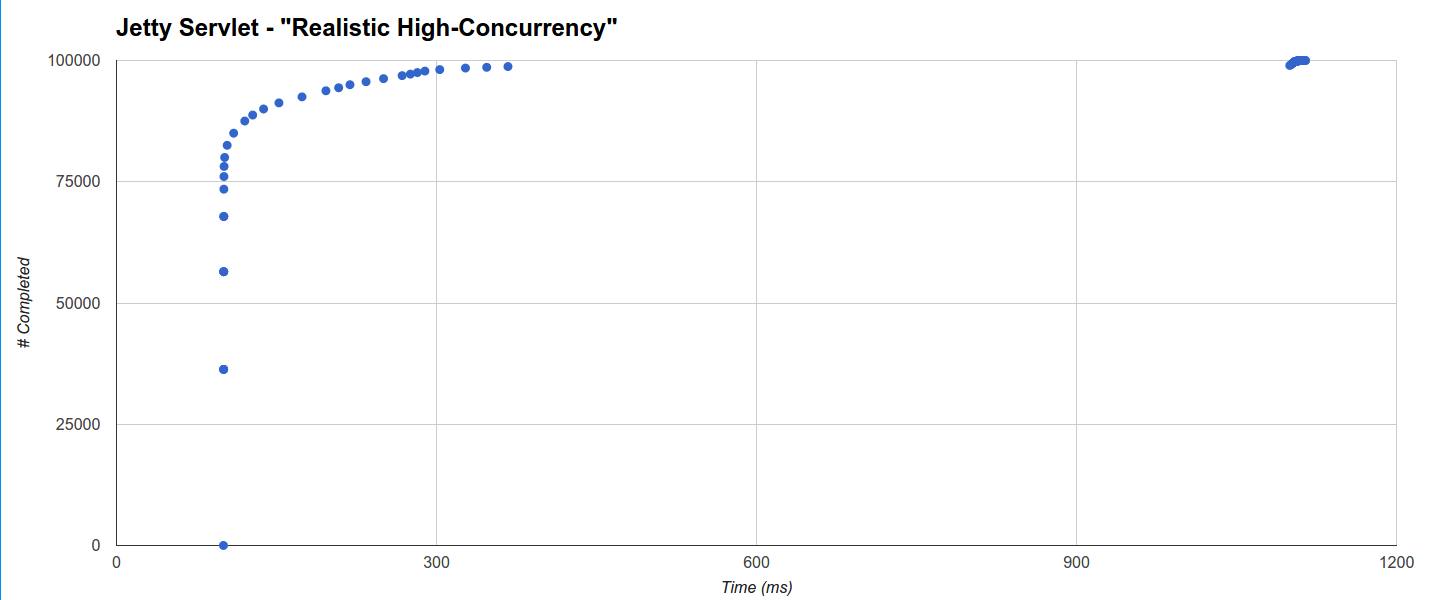
В «Реалистичном высоком параллелизме» наименьшая максимальная задержка генерируется Comsat Jetty Servlet, но цель Jetty Servlet, блокирующая потоки, не сильно отстает: она выполняет 78152 запроса в течение 101 мс (минимум равен времени ожидания 100 мс) и завершается из остальных распределены в два отдельных кластера, один регулярно распределяется от 100 мс до 367 мс, а другой — около 1100 мс до максимума 1114,636 мс:
Цель Serslet Jetty Comsat ведет себя очень схожим образом: 75303 запроса завершаются в течение 101 мс, причем почти все оставшиеся выполняются в течение 328,466 мс, и только 48 — около 1097 мс, максимум до 1103,102 мс:
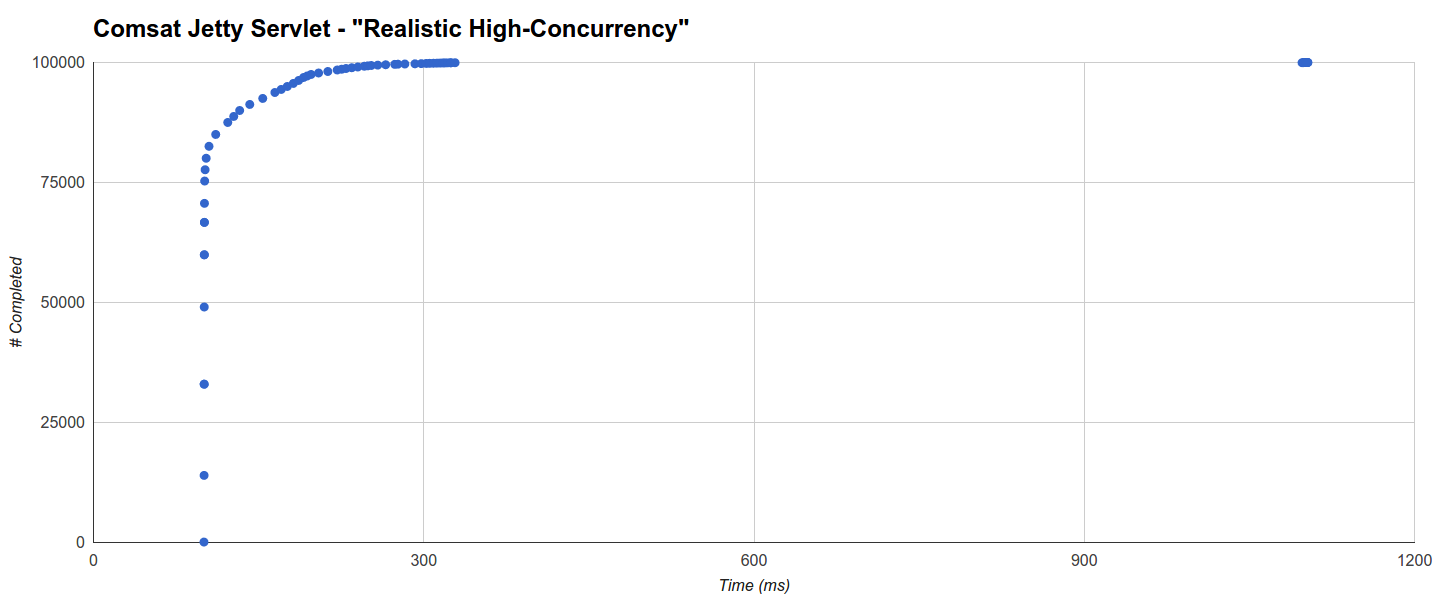
Интересно, что расстояние от основного кластера до «хвостового» примерно соответствует максимальной паузе GC для этого цикла (576 мс).
Spark, построенный на чуть более старой версии 9.3 Jetty, демонстрирует аналогичное поведение, но первый кластер имеет больший разброс во времени (более половины или запрос завершен между 101 мс и 391 мс) и с дополнительными «хвостовыми» кластерами около 1300 мс и 3118 мс (чьи слишком приблизительное расстояние соответствует максимальному времени GC для этого пробега, т.е. 1774 мс):
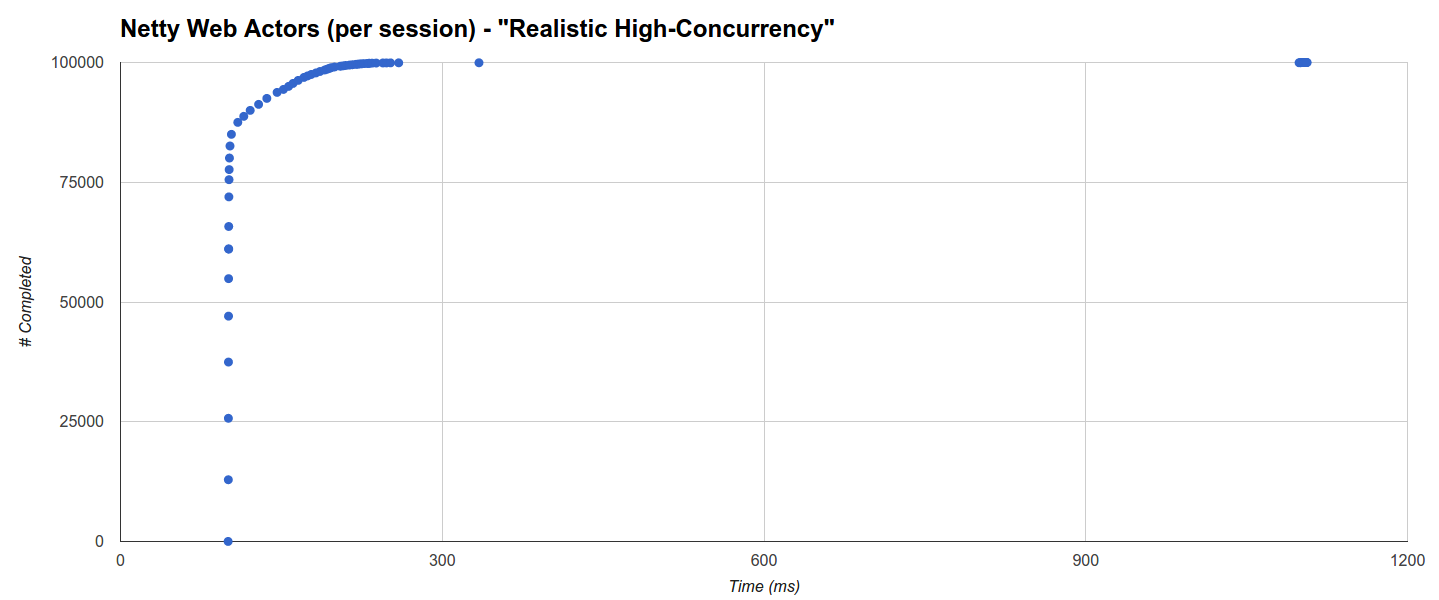
Распределение для Comsat Netty Web Actors (за сеанс) отличается: около 66% завершается в течение 101 мс, а 85% — в течение 103,5 мс, а затем происходит почти логарифмическое, довольно равномерное распределение до ок. 260 мс, в этот момент происходит прерывание, кластер в 334 мс и окончательный кластер от 1098 мс до 1106 мс. В этом случае, по-видимому, нет никакой корреляции с активностью GC, которая, как и ожидалось, намного выше и с максимальным временем GC более 4 с:
Вместо этого у Undertow очень низкие накладные расходы GC, в том числе при интеграции с волокнами Quasar (6 GC работают с максимальной скоростью 407 мс в этом последнем случае). В частности, сервлет Comsat Undertow Servlet имеет более 92,5% запросов, выполненных в течение 101 мс, основной кластер до 341 мс, который включает в себя более 99,5% запросов, и еще два кластера, которые, по-видимому, не находятся в прямой зависимости от активности GC:
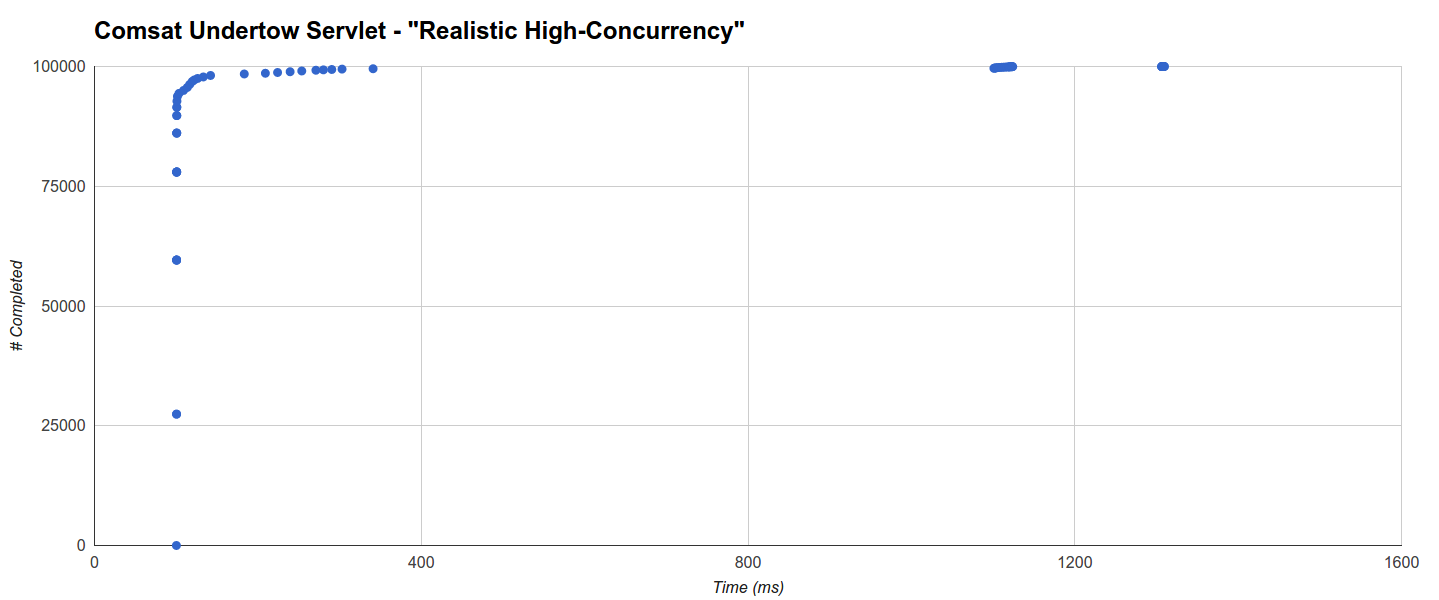
График Undertow Sync очень похож, и основной кластер еще более узкий: более 90% запросов выполняются в течение 101 мс, что приводит к очень хорошему среднему значению, но с дополнительными хвостовыми кластерами, которые увеличивают максимум до более 3 секунд.
Наконец, асинхронный сервлет Undertow, использующий dispatch вызов, имеет худшую производительность, и его многокластерное распределение очень медленно растет до 15 секунд! Кажется, что расстояния между кластерами не особенно коррелируют с максимальным временем работы ГХ:
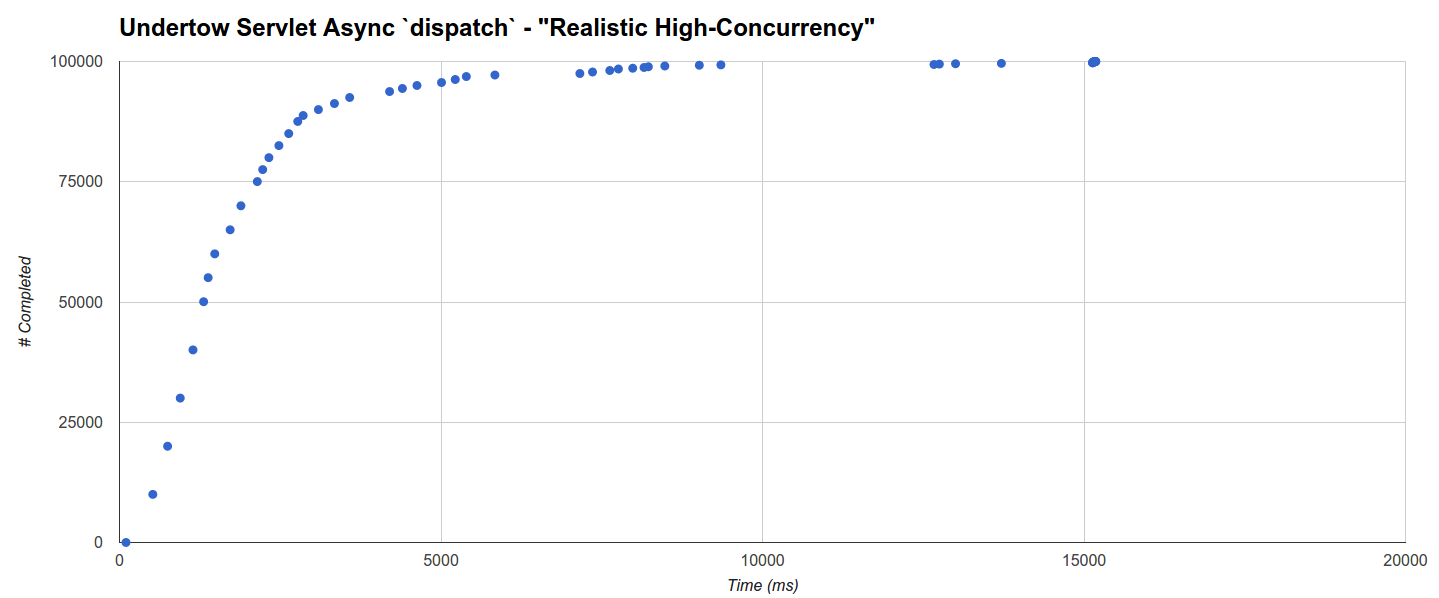
Эта целевая нагрузка имеет низкую производительность также в тесте «Реалистичные издержки», что предполагает, что, возможно, Undertow реализует менее оптимально асинхронный вызов сервлета dispatch .
Эти наблюдения заставляют думать, что в сценариях параллелизма от средней до высокой высокая задержка, по-видимому, больше коррелирует с базовой технологией сети / HTTP, чем с технологией обработки запросов или API, а в некоторых случаях, более конкретно, с чувствительностью к дрожанию, вызванному, например, активностью GC. Это также предполагает, что основной кластер распределений коррелирует с базовой сетью / HTTP-технологией.
Помимо асинхронной работы сервлетов Undertow с использованием dispatch , гистограммы «Реалистичные издержки» показывают равномерно распределенную структуру, общую для всех целей, с 2 или 3 различными тенденциями: одна о быстро завершенных запросах вплоть до числа, специфичного для цели, и другая, включая оставшиеся запросы, которые были выполнены. помедленнее.
Например, целевой объект Jetty Sync Handler (лучший) выполняет 75% запросов за 31,457 мс, тогда как остальные, кажется, распределяются равномерно до максимума 1779,433 мс:
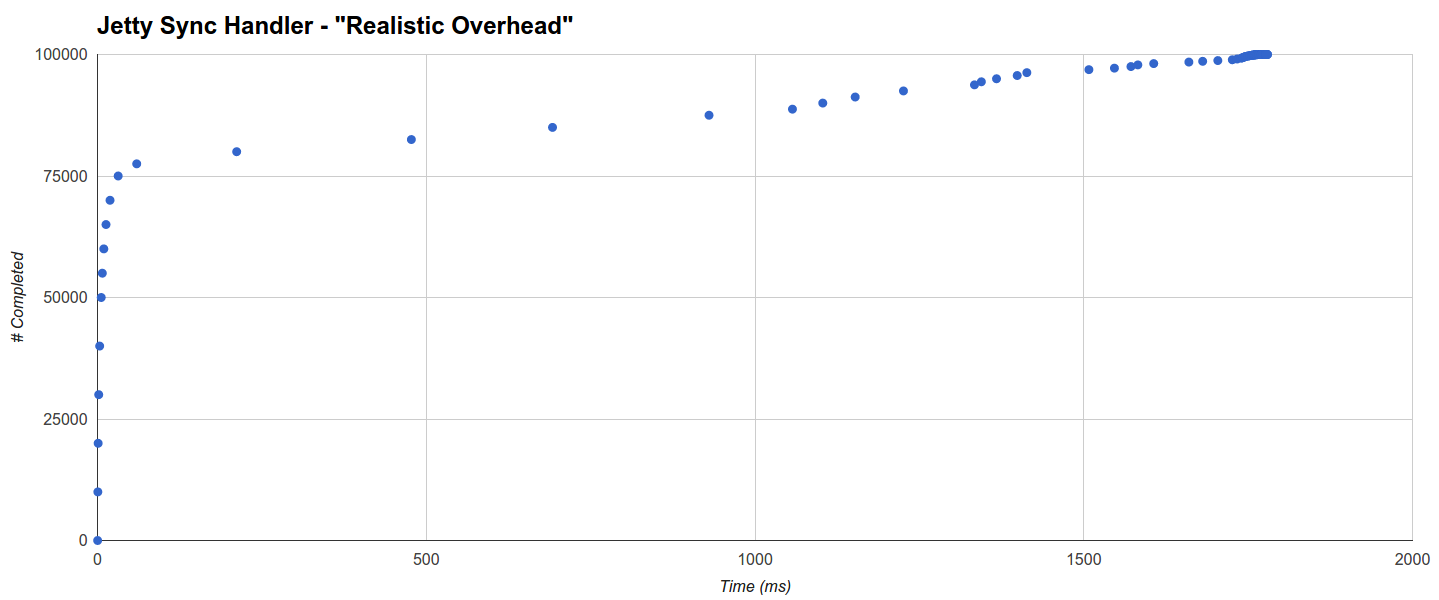
Его активность GC также очень ограничена (3 запуска с максимумом 113 мс).
Tomcat Servlet является худшим с 65% запросов, выполненных за 32,621 мс, 99219 запросов, выполненных за 2227 мс, и еще одной тенденцией, которая добавляет еще 5 с ко времени завершения только ок. 80 запросов. В этом случае вмешательство GC также низкое (хотя оно выше, чем у Jetty):
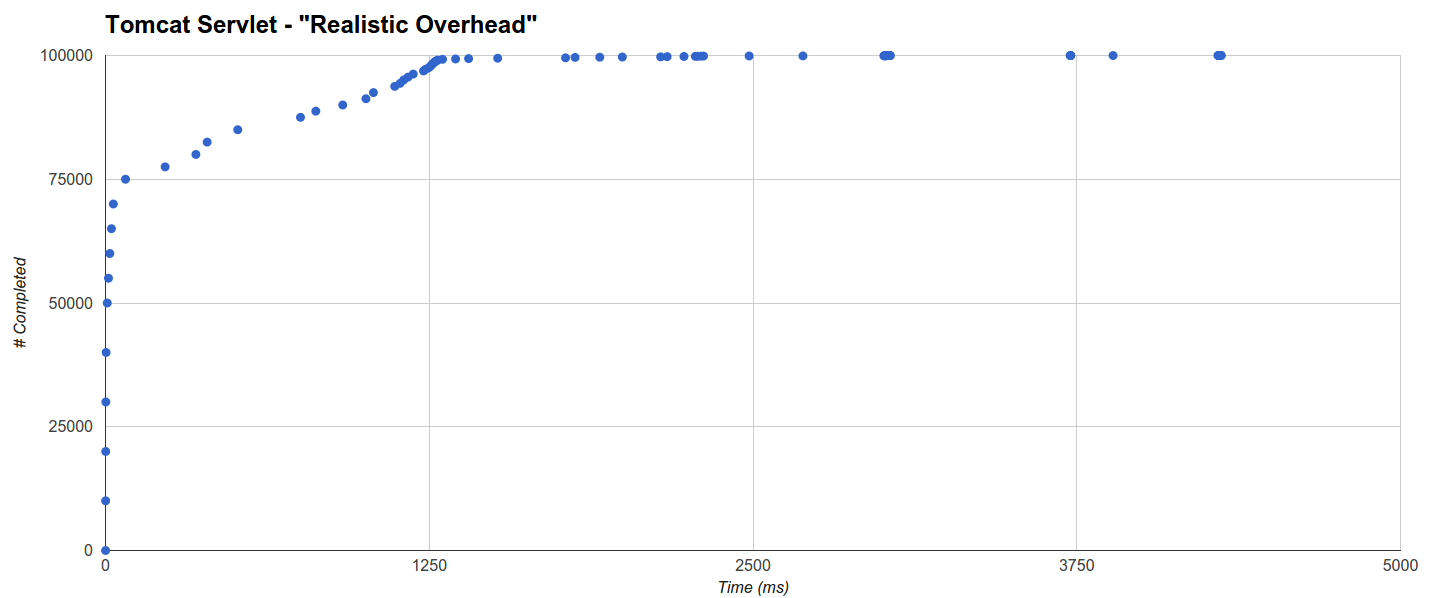
занятия
Результаты приводят к некоторым важным соображениям:
- Если вы не имеете дело со сценариями с высокой степенью параллелизма, нет необходимости рассматривать асинхронные библиотеки, потому что серверы на основе волокон и потоков будут работать идеально и, что не менее важно, они позволят вам написать хорошо читаемый, поддерживаемый и ориентированный на будущее синхронный код ,
- Даже в ситуациях с высоким уровнем параллелизма действительно не нужно прыгать в асинхронную яму, потому что волоконно-оптические серверы имеют очень широкий диапазон применения: с волокнами Quasar вы получаете очень высокий уровень параллелизма, очень хорошую общую производительность и код на будущее. пакет.
- Надо сказать, что некоторым синхронным серверам с блокировкой потоков удается добиться хорошей производительности даже в сценариях с высокой степенью параллелизма и пониманием того, каким именно образом это может быть интересным исследованием. Их фактический максимальный параллелизм намного ниже, чем у асинхронного или квазарского, поэтому, если вы хотите начать обрабатывать как можно больше запросов как можно раньше, вам все же лучше использовать асинхронные / оптоволоконные технологии.
- При нулевом времени обработки запроса даже синхронный однопоточный сервер может работать достаточно хорошо: проблема начинается, когда увеличивается время обработки запроса и начинается эффект параллелизма.
Также наблюдения (и ошибки), сделанные во время выполнения тестов, даже до анализа результатов, подчеркнули важность адекватного подхода к некоторым специфическим особенностям JVM:
- JVM проделывает невероятную работу по оптимизации кода, используя информацию времени выполнения: если вы не верите мне, попробуйте запустить ваше приложение с флагом
-Xcompи без-Xcomp, который выполняет предварительный запуск JIT, и убедитесь сами, как вы получите наилучшие результаты ( подсказка:-Xcomp, вероятно, даст значительно худшую производительность). С другой стороны, это означает, что постепенный разогрев JVM является важным шагом, который необходимо выполнить перед тем, как подвергать HTTP-сервер входящим запросам, поскольку неоптимизированные пути кода могут легко не справиться с внезапной высокой степенью параллелизма и / или высокой скоростью. Скорость нагрузки и вызывает более или менее серьезные сбои. - Джиттер / сбой является серьезной проблемой, особенно для максимальной задержки, но он может даже поставить систему на колени, если это произойдет в «плохой» момент (например, большое количество входящих запросов). Паузы GC являются важным фактором, влияющим на дрожание, поэтому, как правило, рекомендуется тщательно продумать настройку памяти JVM и GC, который вы собираетесь использовать. В частности, максимальная задержка в тестах, кажется, зависит или, в некоторых случаях, даже коррелирует с прогонами GC; Еще один намек в этом направлении заключается в том, что тест производительности с небольшой кучей в 1 ГБ отдает предпочтение более сложным технологиям (асинхронным и оптоволоконным) даже в случаях низкого параллелизма из-за повышенного давления GC даже на более простых серверах. Это означает, что стоит уменьшить количество и продолжительность GC, но как мы можем это сделать? Одним из способов является точный выбор настроек памяти JVM и, если возможно, использование GC с более низкой задержкой, таких как G1 или коммерческая JVM Azul Zing . Другой способ — еще раз выбрать самый простой инструмент для работы: если вы не находитесь в ситуации с высокой степенью параллелизма, просто используйте самые простые технологии, потому что они будут генерировать меньше мусора по сравнению с более сложными.
- По той же причине, если вам нужны сеансы, тогда веб-субъекты для каждого сеанса хороши, поскольку они в основном также включают парадигму «веб-сервер-на-пользователя», как в Erlang ; с другой стороны, если вам не нужен ни сеанс, ни такая надежность, то вы просто получите накладные расходы GC, потому что новый субъект (и его граф объектов) должен быть создан (а затем собран мусором) потенциально для каждого запроса , Это отражено в результатах «Реалистичные накладные расходы».
Дальнейшая работа
Хотя этот тест может стать хорошей отправной точкой для вашей оценки, он ни в коем случае не является исчерпывающим, и его можно улучшить многими способами, например:
- Добавление большего количества целей загрузки.
- Добавление тестовых случаев.
- Сравнительный анализ в других системах (например, HW, другие облака, другие экземпляры AWS).
- Сравнительный анализ JVM не от Oracle.
- Сравнительный анализ с различными настройками JVM.
- Дальнейший анализ данных системы.
- Изучение любопытных поведений, как удивительно хороших (например, серверы синхронизации потоков Jetty с блокировкой потоков в сценариях с высоким параллелизмом), так и удивительно плохих (например, обработчики Undertow на основе
dispatchи сервлеты Tomcat). - Лучше анализировать корреляции, например, между GC-вызванным джиттером и статистикой.
Несмотря на то, что это дорогостоящая работа, я думаю, что, как правило, требуется больше бенчмаркинга, потому что он действительно ведет к лучшему пониманию, улучшению и оценке программных систем.
Вывод
Основная цель состояла в том, чтобы увидеть, как различные API и технологии HTTP-сервера работают в сценариях, приближенных к реальному, когда отдельные процессы JVM клиента и сервера с предопределенными системными ресурсами обмениваются данными в реальной сети и обработка запросов не равна нулю время.
Оказывается, что волокна Quasar можно использовать для создания универсальных исполнителей, которые выдерживают нагрузки с высокой степенью параллелизма и, что не менее важно, являются гораздо лучшими инструментами написания программного обеспечения, чем асинхронные API. Оказывается, опять же, что серебряной пули не существует: в разных ситуациях требуются разные решения, и даже технологии, которые иногда считаются пассивными, как блокирующие потоки серверы (или даже однопоточные серверы), могут выполнять эту работу.
Помимо производительности, выбор API должен играть важную роль в вашем решении, поскольку он будет определять будущее вашего серверного кода. В зависимости от ситуации нестандартный API (и связанные с ним риски, затраты на принятие и отказ) могут быть или не быть жизнеспособным вариантом в зависимости от требований вашего проекта и среды разработки. Еще одна вещь, которую следует учитывать, заключается в том, что асинхронные API-интерфейсы значительно сложнее в использовании, чем синхронизирующие, и имеют тенденцию заражать всю кодовую базу с помощью асинхронности 7 , что означает, что использование асинхронных API-интерфейсов может помешать поддержке вашего кода и сократить его будущее.
Тем не менее, я полностью осознаю тот факт, что тесты производительности представляют собой частичную картину с максимальными усилиями (и использованием) постоянно меняющихся ландшафтов ограниченных инструментов и знаний, и что разработка, запуск и публикация тестов производительности — это тяжелая работа и серьезные инвестиции. ,
Я надеюсь, что этот раунд будет полезен для многих, и я буду тепло приветствовать и ценить, а также поощрять любые предложения, улучшения и дальнейшие усилия.
- Количество чистого ввода / вывода намеренно минимально, потому что я не был, и я все еще не заинтересован в изучении эффективности чтения / записи сокетов. ↩
- Конечно, даже эталон целевого уровня не полностью отражает реальную ситуацию, потому что показатель редко фиксируется и / или известен заранее, но мы можем по крайней мере увидеть, что происходит, например, с некоторыми наихудшими показателями.
- Относится только к интерфейсным API и технологиям.
- Нравится ли вам актеры или нет, возможность обрабатывать HTTP-запросы в JVM с помощью
for(;;) { reply(process(receive())); }for(;;) { reply(process(receive())); }Цикл в легких потоках, прикрепленных к входящим / исходящим очередям, это то, что лично я всегда хотел. Еще важнее то, что это обеспечивает совершенно новый уровень надежности, как если бы у каждого пользователя был свой веб-сервер . - Они основаны на сервлетах, но не совсем одинаковы, особенно части настройки / конфигурации.
- Развертывания Web Actors на основе Netty и Undertow предоставляют готовую стратегию для
per-session, но они также позволяют программно назначать участников запросам с использованием стратегии, предоставленной разработчиком. - Это связано с тем, что код, вызывающий асинхронную функцию, должен будет либо передать какой-либо обратный вызов, либо иметь дело с возвращаемым значением в будущем или обещанием (что, в свою очередь, означает либо блокировку потока во время ожидания результата, если это вообще возможно, либо рассказывая, как продолжить, когда таковой имеется).
| Ссылка: | Тестирование HTTP-серверов с высокой степенью параллелизма на JVM от нашего партнера по JCG Фабио Тудоне в блоге Parallel Universe . |