На конференции OOP 2018 в Мюнхене я представил обновленную версию моего выступления о создании масштабируемых, критически важных микросервисов с использованием экосистемы Apache Kafka и сред глубокого обучения, таких как TensorFlow, DeepLearning4J или H2O . Я хочу поделиться обновленной слайд-колодой и обсудить несколько обновлений о новейших тенденциях, которые я включил в доклад.
Основная история та же, что и в моем сообщении в блоге Confluent об экосистеме Apache Kafka и машинном обучении : как создать и развернуть масштабируемое машинное обучение в производстве с помощью Apache Kafka. Но я больше сосредоточился на глубоком обучении / нейронных сетях. Я также обсудил некоторые инновации в экосистеме Apache Kafka и тенденции ML в последние месяцы: платформы KSQL, ONNX, AutoML, ML от Uber и Netflix . Давайте посмотрим на эти интересные темы и как это связано друг с другом.
KSQL — Потоковый язык SQL поверх Apache Kafka.
« KSQL — это потоковый движок SQL для Apache Kafka . KSQL опускает полосу входа в мир потоковой обработки, предоставляя простой и полностью интерактивный интерфейс SQL для обработки данных в Kafka. Вам больше не нужно писать код на языке программирования, таком как Java или Python! KSQL имеет открытый исходный код (лицензию Apache 2.0), распространяется, масштабируется, надежен и работает в режиме реального времени. Он поддерживает широкий спектр мощных операций обработки потоков, включая агрегации, объединения, управление окнами, сеансы и многое другое ». Подробнее здесь: « Представляем KSQL: потоковый SQL с открытым исходным кодом для Apache Kafka ».
Вы можете писать SQL-подобные запросы для развертывания масштабируемых, критически важных приложений для обработки потоков (которые используют Kafka Streams под капотом). Определенно основной момент в экосистеме открытого исходного кода Kafka.
KSQL и машинное обучение
KSQL построен поверх Kafka Streams и поэтому позволяет создавать масштабируемые, критически важные сервисы. Модели машинного обучения, включая нейронные сети, легко встраиваются, создавая пользовательскую функцию (UDF) . В эти дни я готовлю пример, в котором я применяю нейронную сеть — точнее, авто-кодер — для сенсорной аналитики, чтобы обнаружить аномалии — то есть критические значения в проверках состояния здоровья — гостей больницы в режиме реального времени, чтобы отправить предупреждение врачу.
Давайте теперь поговорим о некоторых интересных новых разработках в экосистеме машинного обучения.
ONNX — открытый формат для представления моделей глубокого обучения
« ONNX — это открытый формат для представления моделей глубокого обучения . С помощью ONNX разработчики искусственного интеллекта могут легче перемещать модели между современными инструментами и выбирать оптимальную для них комбинацию ».
Это похоже на PMML (язык разметки прогнозируемой модели, см. « Что такое PMML » в KDnuggets) и PFA (Portable Format for Analytics), два других стандарта для определения и совместного использования моделей машинного обучения. Тем не менее, ONNX отличается в нескольких аспектах:
- фокусируется на глубокое обучение
- за ним стоят несколько крупных технологических компаний (AWS, Microsoft, Facebook) и производители оборудования (AMD, NVidia, Intel, Qualcomm и т. д.).
- уже поддерживает многие ведущие фреймворки с открытым исходным кодом (включая TensorFlow, Pytorch, MXNet)
ONNX уже GA в версии 1.0 и готов к производству ( как было объявлено Amazon, Microsoft и Facebook в декабре 2017 года ). Существует также хорошее руководство по началу работы для различных фреймворков .
ONNX и экосистема Apache Kafka
К сожалению, ONNX пока не поддерживает Java . Следовательно, пока нет поддержки для встраивания его в Java API Kafka Streams. Только через обходной путь, такой как выполнение вызова REST или встраивание привязки JNI. Но я уверен, что это только вопрос времени, потому что платформа Java так важна на многих предприятиях для развертывания критически важных приложений.
Прямо сейчас вы можете использовать Java API от Kafka или других клиентов Kafka. Confluent предоставляет официальных клиентов для нескольких языков программирования, например, для Python или Go , которые также идеально подходят для приложений машинного обучения.
Автоматизированное машинное обучение (иначе AutoML)
«Автоматизированное машинное обучение (AutoML) — это горячая новая область, цель которой — упростить выбор различных алгоритмов машинного обучения, настроек их параметров и методов предварительной обработки, которые улучшают их способность обнаруживать сложные шаблоны в больших данных», — говорится в заявлении. здесь
С AutoML вы можете создавать аналитические модели без каких-либо знаний о машинном обучении. Реализации AutoML используют различные реализации деревьев решений, кластеризации, нейронных сетей и т. Д. Для построения и сравнения различных моделей из коробки. Вы просто загружаете или подключаете свой набор исторических данных и нажимаете несколько кнопок, чтобы начать процесс. Может быть, не идеально подходит для каждого варианта использования, но вы можете легко улучшить многие существующие процессы без необходимости в редких и дорогих специалистах по данным.
DataRobot или Google AutoML являются двумя из многих известных облачных предложений в этой области. AutoML от H2O интегрирован в среду ML с открытым исходным кодом, но они также предлагают хороший коммерческий продукт, ориентированный на пользовательский интерфейс, который называется « Driverless AI ». Я настоятельно рекомендую потратить 30 минут на любой инструмент AutoML. Действительно интересно видеть, как инструменты ИИ развиваются в наши дни.
AutoML и экосистема Apache Kafka
Большинство инструментов AutoML предлагают развертывание своих моделей. Вы можете получить доступ к аналитическим моделям, например, через интерфейс REST. Не идеальное решение для масштабируемой архитектуры событийного типа, такой как Kafka. Хорошая новость: многие решения AutoML также позволяют экспортировать сгенерированные модели, чтобы вы могли развернуть их в своем приложении . Например, AutoML в средах с открытым исходным кодом H2O является лишь одним из многих вариантов. Вы используете только другую операцию на выбранном вами языке программирования (R, Python, Scala, Web UI):
|
1
2
3
4
|
aml <- h2o.automl(x = x, y = y, training_frame = train, leaderboard_frame = test, max_runtime_secs = 30) |
Подобно тому, что вы бы сделали для построения линейной регрессии, дерева решений или нейронной сети. В результате генерируется Java-код, который вы можете легко встроить в микросервис Kafka Streams или в любое другое приложение Kafka. AutoML позволяет создавать и развертывать высокомасштабируемое машинное обучение без глубоких знаний ML.
ML Platforms: Микеланджело Убера; Netflix ‘Meson
Технические гиганты, как правило, на несколько лет опережают «традиционные предприятия». Они уже построили много лет назад то, что вы строите сегодня или завтра. Платформы ML не имеют никакой разницы. Написание исходного кода ML для обучения аналитической модели — это лишь малая часть реальной инфраструктуры ML. Вам нужно подумать обо всем процессе разработки. На следующем рисунке показана « Скрытая техническая задолженность в системах машинного обучения »:
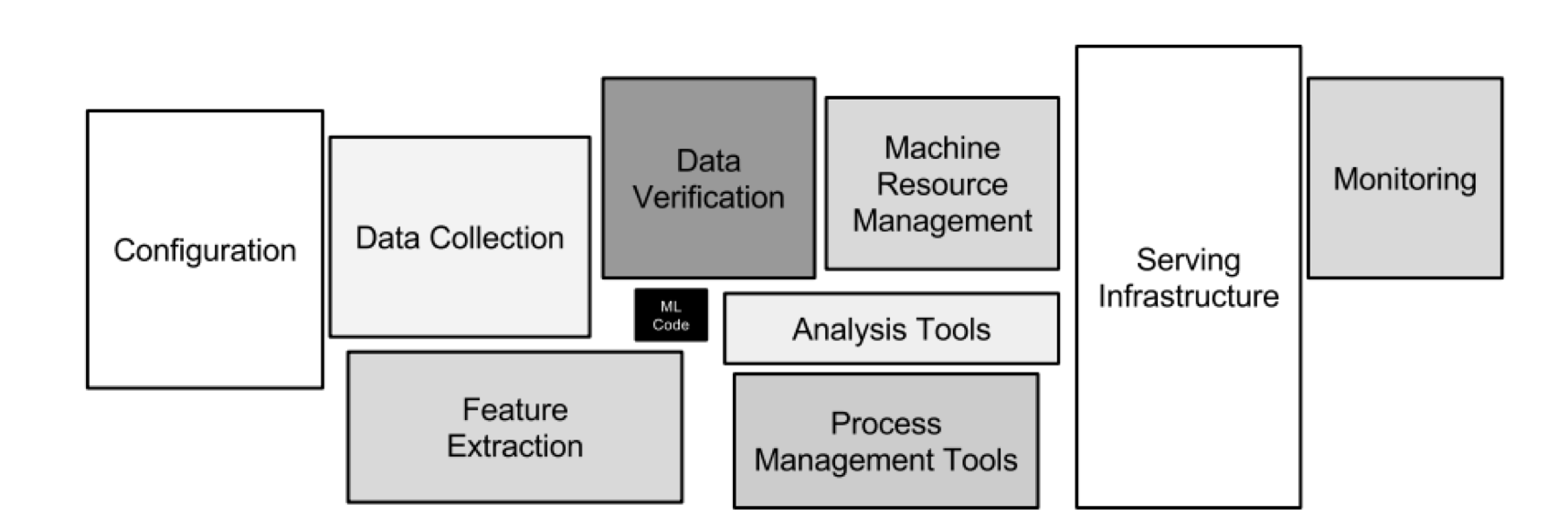
Вероятно, вы построите несколько аналитических моделей с разными технологиями. Не все будет встроено в ваш кластер Spark или Flink или в единую облачную инфраструктуру. Вы можете запустить TensorFlow на большом дорогом графическом процессоре в общедоступном облаке для создания мощных нейронных сетей. Или используйте H2O для построения небольших, но очень эффективных и производительных деревьев решений, которые делают вывод за несколько микросекунд … У ML много вариантов использования.
Вот почему многие технические гиганты создали свои собственные платформы ML, такие как Uber’s Michelangelo или Netflix ‘Meson . Эти платформы ML позволяют им создавать и отслеживать мощные масштабируемые аналитические модели, а также сохранять гибкость в выборе правильной технологии ML для каждого варианта использования.
Apache Kafka экосистема для платформ ML
Одна из причин успеха Apache Kafka — это огромное признание многих технических гигантов. Почти все великие компании Силиконовой долины, такие как LinkedIn, Netflix, Uber, Ebay, пишут в блоге «вы зовете меня» и рассказывают об использовании Kafka в качестве управляемой событиями центральной нервной системы для своих критически важных приложений. Многие сосредотачиваются на распределенной потоковой платформе для обмена сообщениями, но мы также видим все больше и больше принятия таких дополнений, как Kafka Connect, Kafka Streams, REST Proxy, Schema Registry или KSQL.
Если вы снова посмотрите на рисунок выше, подумайте о Кафке: разве это не идеально подходит для платформы ML? Обучение, мониторинг, развертывание, вывод, настройка, A / B-тестирование и т. Д. И т. Д. И т. Д. Вероятно, именно поэтому Uber, Netflix и многие другие уже используют Kafka в качестве центрального компонента в своей инфраструктуре ML.
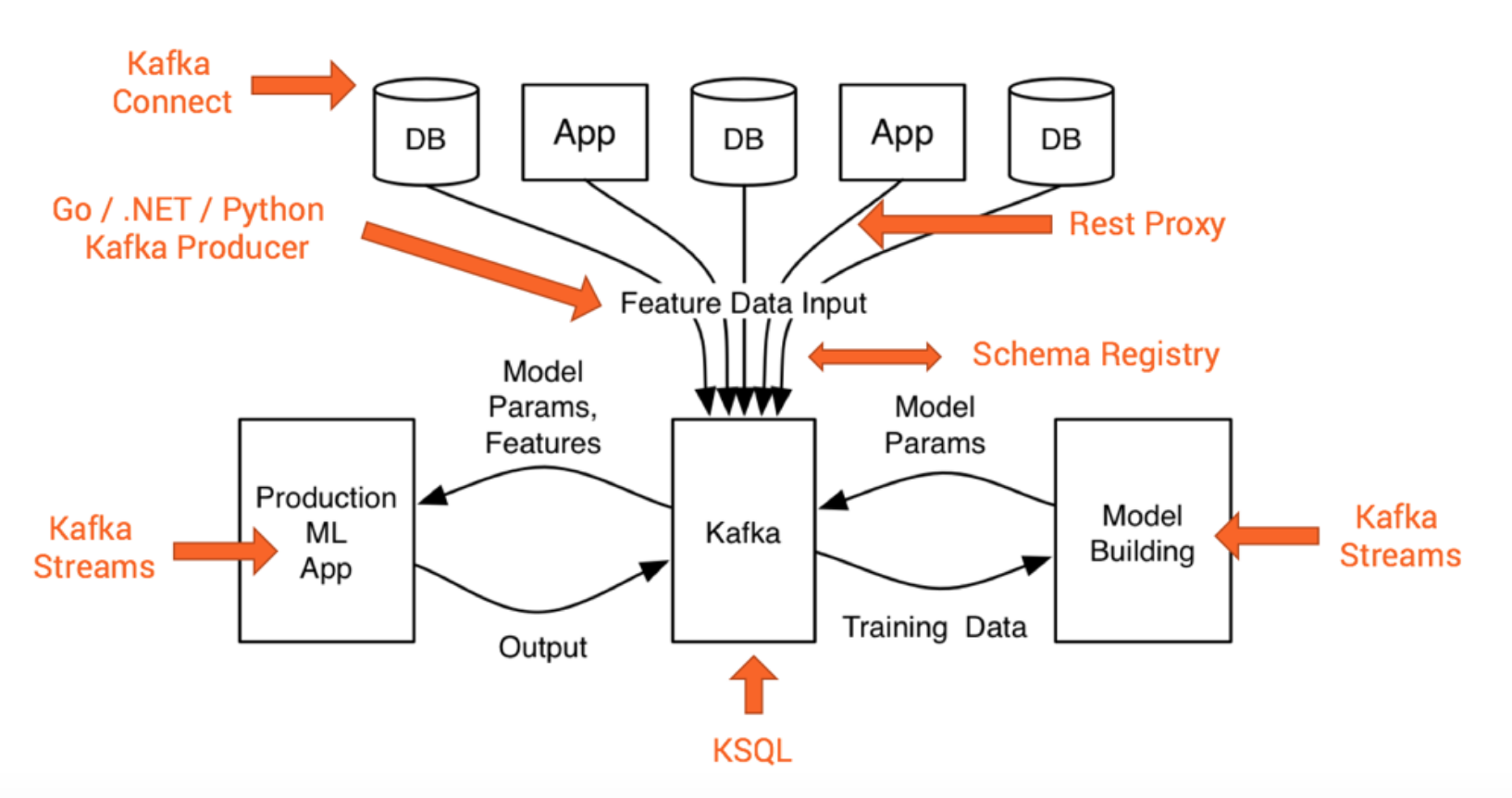
И опять же, вы не обязаны использовать только одну конкретную технологию. Одна из замечательных концепций проектирования Kafka заключается в том, что вы можете снова и снова обрабатывать данные из распределенного журнала фиксации. Это означает, что вы можете либо создать разные модели с одной технологией, такой как приемник Kafka (скажем, Apache Flink или Spark), либо подключить различные технологии, такие как scikit-learn для локального тестирования, TensorFlow, работающий на графических процессорах Google Cloud для мощного глубокого обучения, и установка на месте. узлов H2O для AutoML и некоторых других приложений Kafka Streams ML, развернутых в контейнерах Docker или Kubernetes. Все эти приложения ML потребляют данные параллельно в своем темпе и с той частотой, в которой они нуждаются.
Вот отличный пример того, как автоматизировать обучение и развертывание масштабируемого микросервиса ML с Kafka и Kafka Streams . Нет необходимости добавлять еще один большой кластер данных. Это одно из ключевых отличий использования Kafka Streams или KSQL для ваших приложений ML вместо других сред обработки потоков.
Apache Kafka и Deep Learning — слайд-колода из ООП
Наконец, после всех этих дискуссий об экосистеме Apache Kafka и новых тенденциях в области машинного обучения / глубокого обучения, вот мои обновленные слайды из моего выступления на конференции ООП 2018:
Тенденции машинного обучения в 2018 году в сочетании с экосистемой Apache Kafka от Kai Wähner
Я также создал несколько примеров с использованием Apache Kafka, Kafka Streams и различных ML-фреймворков с открытым исходным кодом, таких как H2O, TensorFlow и DeepLearning4j (DL4J) . Проект Github демонстрирует, насколько просто развертывать аналитические модели в высокомасштабируемом, отказоустойчивом и критически важном микросервисе Kafka. Демоверсия KSQL также скоро появится.
Пожалуйста, поделитесь своим мнением. Вы уже используете Kafka в области машинного обучения? Какие компоненты помимо ядра Kafka вы используете? Не стесняйтесь связаться со мной, чтобы обсудить это более подробно.
| Опубликовано на Java Code Geeks с разрешения Кая Вейнера, партнера нашей программы JCG. Смотреть оригинальную статью здесь: Тенденции машинного обучения в 2018 году в сочетании с экосистемой Apache Kafka
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |