У меня было несколько сообщений в блоге, тушащихся в моем мозгу некоторое время. Стив Нельсон в прошлом году помог мне с регулярным выражением (Regex), и я решил больше практиковать свои навыки Regex. Эта серия покажет, как использовать регулярные выражения в Eclipse, и мы узнаем несколько полезных советов на этом пути.
Эта серия для вас, если вы разработчик, который читает сообщения Бена Наделя, содержащие регулярные выражения , и не знает, о чем он говорит. Серьезно, Бен, это непостижимо для нас, простых смертных:
<cfset blogContent = reReplace (blogContent, «</? \ w + (\ s * [\ w:] + \ s * = \ s * (» «[^» «] *» «| ‘[^’] * ‘ )) * \ s * /?> «,» «,» all «) />
(Похоже, сумасшедшая кошачья кошечка пошла на прану на клавиатуре, не так ли?)
Хватит хохота и тому подобное. На с обучением.
Примечание редактора:
Просто чтение этих постов в блоге не поможет вам. Откройте затмение и скопируйте / вставьте этот материал в диалог поиска / замены. Вы узнаете больше, или ваши деньги вернутся!
Итак, во-первых, нам нужен вариант использования. Давайте представим, что мы проходим старый код и собираемся добавить HTMLEditFormat вокруг некоторых аргументов, чтобы формы не ломались при наличии кавычек.
Предположим, этот набор объявлений:
<input name="fred" value="willy" /> <input name="bill" value="mickey" /> <input name="erin" value="harry" /> <input name="baz" value="pissette" />
Мы хотим превратить: <input name = «fred» value = «willy» /> в: <input name = «fred» id = «fred» value = «willy» />
Как правило, это была бы утомительная цепочка предплечья / запястья на клавиатуре, яростно резавшая / вставляющая и, как правило, хлопающая. Не так с регулярными выражениями. Regex — это сопоставитель шаблонов, и он может делать вещи Мы можем видеть, что наш код повторяется, и шаблон, который нам нужен: создать новый атрибут с именем ‘id’ и заполнить его значением из атрибута ‘name’ … что мы и будем делать снова и снова с помощью cut / паста / и т.д..
Мы можем определить этот шаблон в gobbledegook, определяя регулярное выражение, конечно, иначе я бы написал этот пост о Cute LOLCats, а не Cute Regexes. Не так ли? Мы пройдем упражнение, а затем посмотрим, почему оно сработало.
В Eclipse выполните следующее:
- Откройте новый файл и вставьте вышеуказанный набор объявлений: (запомните фрагмент выше, начиная с <input name = «fred» value = «willy» /> …)
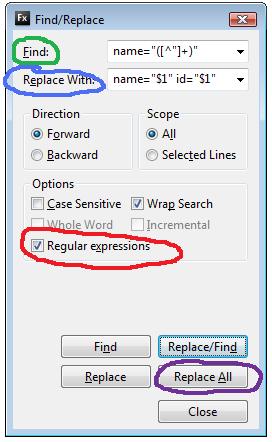
- Откройте диалог поиска (я использую CTRL + F) и убедитесь, что включена опция Регулярное выражение
- Введите следующее в поле « Найти»: « Имя входа =« ([^ »] +)»
- Введите следующее в Replace: Input name = «$ 1» id = «$ 1»
- Нажмите Find и убедитесь, что шаблон соответствует тому, что мы хотим
- Наконец, нажмите Заменить все
Вы должны иметь это:
<input name="fred" id="fred" value="willy" /> <input name="bill" id="bill" value="mickey" /> <input name="erin" id="erin" value="harry" /> <input name="baz" id="baz" value="pisser" />
(если нет, вы пропустили шаг. Посмотрите на изображение и сравните с тем, что есть в диалоговом окне «Найти / заменить». Убедитесь, что в выражении поиска нет лишних пробелов)
Blamo! Ваш код теперь правильно отсортирован с новым атрибутом ID, и у вас даже не было синдрома запястного канала! Давайте расшифруем код, не так ли?
Вот часть поиска регулярного выражения: name = «([^»]) + «
- name = « Первый символьный блок — это слово ‘name’, за которым следует знак равенства, а затем двойная кавычка. Все эти литералы не нуждаются в экранировании.
- ( Следующий символ — открытая скобка. Он определяет начало группы. Помните, что мы хотим использовать значение атрибута name, чтобы заполнить имя атрибута ID.
- [^ «] + Следующий блок определяет любой символ, который не является двойной кавычкой. Обратите внимание, что он начинается с открытой скобки, используемой для определения набора. Внутри открытой скобки указан карат. Это означает, что это противоположный день, и наш набор должен НЕ ВКЛЮЧАЕТ все, что следует. Далее следует двойная кавычка, потому что значение атрибута находится внутри границ двойных кавычек. Мы закрываем этот набор символов с помощью закрывающей скобки, затем символ плюс, потому что символ плюс определяет 1 или более предыдущего символа в выражении. Мы определенно хотим иметь более одного символа перед закрывающей двойной кавычкой, иначе мы не хотим совпадения.
- ) И, наконец, мы имеем закрывающую скобку , образующая конца нашей группы и еще двойные кавычки , символизирующие конец нашего согласования границы.
Все это определяет границы для символа, проходящего регулярное выражение gnome, чтобы взять материал внутри атрибута и удержать его.
Затем в разделе «Заменить» мы использовали: name = «$ 1» id = «$ 1»
- Атрибуты ‘name’ и ‘id’ вместе с обоими знаками равенства и обоими наборами двойных кавычек являются буквальными, экранирование не требуется.
- $ 1 относится к группе, которую мы определили во входных данных Find, и мы используем ее дважды. $ n называется обратной ссылкой.
Таким образом, на простом английском языке мы попросили регулярное выражение find / replace gnome: взять содержимое внутри атрибута ‘name’ и вставить его обратно в атрибут ‘name’, а также в новый атрибут ‘id’.
Я уверен, что вы можете согласиться, что это было намного проще, чем феерия копирования / вставки ..
Часть вторая
В нашем последнем упражнении мы рассмотрели простой способ добавления нового атрибута в тег HTML. Это было достигнуто путем создания шаблона, определения группы и использования обратной ссылки. На этот раз мы рассмотрим несколько более сложный вариант использования.
Предположим, этот набор объявлений:
product.setColor(arguments.color); product.setSize(arguments.size); product.setCondition(arguments.condition); product.setRating(arguments.rating); product.setReliability(arguments.reliability); product.setNeedsBatteries(arguments.needsBatteries);
То, что мы хотим, это превратить: product.setColor (arguments.color); into: product.setColor (htmlEditFormat (arguments.color));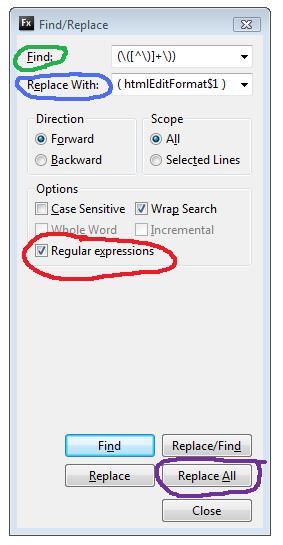
Как правило, это была бы утомительная цепочка предплечья / запястья на клавиатуре, яростно резавшая / вставляющая и, как правило, хлопающая. Не так с регулярными выражениями. Regex — это сопоставитель шаблонов, и он может делать вещи Мы можем видеть, что наш код повторяется, и шаблон, который нам нужен: взять все внутри скобок и обернуть его в функцию htmlEditFormat (). (То же самое мы бы делали снова и снова через вырезать / вставить / и т.д., не так ли?)
Мы можем определить этот шаблон в gobbledegook, определяющем регулярное выражение. Когда читаешь один кусок за раз, это действительно имеет смысл. Мы пройдем упражнение, а затем посмотрим, почему оно сработало.
В Eclipse выполните следующее:
Примечание редактора:
Просто чтение этих постов в блоге не поможет вам. Откройте затмение и скопируйте / вставьте этот материал в диалог поиска / замены. Вы узнаете больше, или ваши деньги вернутся!
- Откройте новый файл и вставьте вышеуказанный набор объявлений: (запомните фрагмент выше, начиная с product.setColor (arguments.color); …)
- Откройте диалог поиска (я использую CTRL + F) и убедитесь, что включена опция Регулярное выражение
- Введите следующее в поле « Найти»: «Ввод (\ ([^ \)] + \)»
- Введите следующее в Replace: Input (htmlEditFormat $ 1)
- Нажмите Find и убедитесь, что шаблон соответствует тому, что мы хотим
- Наконец, нажмите Заменить все
Вы должны иметь это:
product.setColor( htmlEditFormat( htmlEditFormat(arguments.color) ) ); product.setSize( htmlEditFormat(arguments.size) ); product.setCondition( htmlEditFormat(arguments.condition) ); product.setRating( htmlEditFormat(arguments.rating) ); product.setReliability( htmlEditFormat(arguments.reliability) ); product.setNeedsBatteries( htmlEditFormat(arguments.needsBatteries) );
(если нет, вы пропустили шаг. Посмотрите на изображение и сравните с тем, что есть в диалоговом окне «Найти / заменить». Убедитесь, что в выражении поиска нет лишних пробелов)
Blamo! Ваш код теперь все правильно HTMLEditFormatted, и у вас даже не было синдрома запястного канала! Давайте расшифруем код, не так ли?
Вот часть поиска регулярного выражения: (\ ([^ \)] + \))
- ( Первый символьный блок представляет собой открытую скобку. Это в основном определяет группу. Вы можете видеть, что все выражение заключено в круглые скобки, поэтому мы будем рассматривать то, что найдено как группа.
- \ ( Следующий фрагмент — это обратная косая черта. Чаще всего это экранирующий символ, что означает, что следующий символ рассматривается как литеральный символ, который мы хотим найти в нашей строке. Взяв следующий символ, мы видим, что хотим найти открытый символ. скобка.
- [^ \)] Следующий блок определяет любой символ, который не является закрывающей скобкой. Обратите внимание, что он начинается с открытой скобки, используемой для определения набора. Внутри открытого кронштейна находится карат. Это означает, что это противоположный день, и наш набор НЕ должен включать в себя все, что следует. Далее следует обратный слеш и закрывающая скобка, регулярное выражение для литерала ( затем закрывающая скобка.
- + \) Следующий фрагмент — это символ плюс, за которым следует обратный слеш и закрывающая скобка. Символ «плюс» определяет 1 или более следующего символа в выражении, который на самом деле является следующим следующим символом, поскольку нам необходимо использовать обратную косую черту, чтобы избежать закрывающей скобки.
- ) Последний кусок, закрывающая скобка, определяющая конец нашей группы.
Все это определяет границы, по которым персонаж проходит по регулярному выражению gnome, чтобы взять содержимое в скобках и удержать его.
Затем в разделе Replace мы использовали: (htmlEditFormat $ 1)
- Окружающие скобки являются буквальными, как и htmlEditFormat.
- $ 1 относится к группе, которую мы определили во входных данных Find. (помните термин обратная ссылка?)
Таким образом, на простом английском языке мы попросили регулярное выражение найти / заменить gnome: взять содержимое в скобках и обернуть его (HTMLEditFormat + GROUPTEXT +).