Я рад объявить о первой версии моего проекта репозитория Spring Data JDBC . Целью этой библиотеки с открытым исходным кодом является предоставление универсальной, легкой и простой в использовании реализации DAO для реляционных баз данных на основе JdbcTemplate из JdbcTemplate Spring , совместимой с зонтиком проектов Spring Data.
Цели дизайна
- Легкий, быстрый и легкий наверх. Только несколько классов, нет XML, аннотации, отражения
- Это не полноценная ORM . Нет обработки отношений, ленивая загрузка, грязная проверка, кэширование
- CRUD внедряется за считанные секунды
- Для небольших приложений, где JPA является излишним
- Используйте, когда необходима простота или когда рассматривается вопрос о будущей миграции, например, в JPA
- Минималистическая поддержка различий в диалектах базы данных (например, прозрачное разбиение на страницы результатов)
Особенности
Каждый DAO обеспечивает встроенную поддержку для:
- Отображение в / из доменных объектов через абстракцию
RowMapper - Сгенерированные и определяемые пользователем первичные ключи
- Извлечение сгенерированного ключа
- Составные (многоколонные) первичные ключи
- Неизменяемые доменные объекты
- Пейджинг (запрашивает подмножество результатов)
- Сортировка по нескольким столбцам (база данных не зависит)
- Дополнительная поддержка отношений « многие к одному»
- Поддерживаемые базы данных (постоянно тестируются):
- MySQL
- PostgreSQL
- H2
- HSQLDB
- дерби
- … и, скорее всего, большинство других
- Легко расширяется на другие диалекты базы данных через класс
SqlGenerator. - Легкий поиск записей по ID
API
Совместимые с абстракцией Spring Data PagingAndSortingRepository , все эти методы реализованы для вас :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
public interface PagingAndSortingRepository<T, ID extends Serializable> extends CrudRepository<T, ID> { T save(T entity); Iterable<T> save(Iterable<? extends T> entities); T findOne(ID id); boolean exists(ID id); Iterable<T> findAll(); long count(); void delete(ID id); void delete(T entity); void delete(Iterable<? extends T> entities); void deleteAll(); Iterable<T> findAll(Sort sort); Page<T> findAll(Pageable pageable);} |
Pageable и Sort также полностью поддерживаются, а это означает, что вы можете получать страницы и сортировку по произвольным свойствам бесплатно . Например, у вас есть userRepository расширяющий PagingAndSortingRepository<User, String> (реализованный для вас библиотекой), и вы запрашиваете 5-ю страницу таблицы USERS , 10 на страницу, после применения некоторой сортировки:
|
1
2
3
4
5
6
7
8
9
|
Page<User> page = userRepository.findAll( new PageRequest( 5, 10, new Sort( new Order(DESC, "reputation"), new Order(ASC, "user_name") ) )); |
Библиотека репозитория Spring Data JDBC переведет этот вызов в (синтаксис PostgreSQL):
|
1
2
3
4
|
SELECT *FROM USERSORDER BY reputation DESC, user_name ASCLIMIT 50 OFFSET 10 |
… или даже (синтаксис Derby):
|
1
2
3
4
5
6
7
8
9
|
SELECT * FROM ( SELECT ROW_NUMBER() OVER () AS ROW_NUM, t.* FROM ( SELECT * FROM USERS ORDER BY reputation DESC, user_name ASC ) AS t ) AS aWHERE ROW_NUM BETWEEN 51 AND 60 |
Независимо от того, какую базу данных вы используете, вы получите взамен объект Page<User> (вам все равно придется самостоятельно предоставить RowMapper<User> для перевода из ResultSet в объект домена. Если вы еще не знаете проект Spring Data, Page<T> — прекрасная абстракция, не только инкапсулирующая List<User> , но и предоставляющая метаданные, такие как общее количество записей, на какой странице мы в настоящее время находимся и т. Д.
Причины использовать
- В будущем вы рассматриваете возможность перехода на JPA или даже на некоторую базу данных NoSQL. Поскольку ваш код будет опираться только на методы, определенные в
PagingAndSortingRepositoryиCrudRepositoryиз зонтичного проекта Spring Data Commons, вы можете свободно переключаться с реализацииJdbcRepository(из этого проекта) на:JpaRepository,MongoRepository,GemfireRepositoryилиGraphRepository. Все они реализуют один и тот же общий API. Конечно, не ожидайте, что переключение с JDBC на JPA или MongoDB будет таким же простым, как переключение импортированных зависимостей JAR — но по крайней мере вы минимизируете влияние, используя тот же DAO API. - Вам нужна быстрая и простая библиотека-оболочка JDBC. JPA или даже MyBatis — это перебор
- Вы хотите иметь полный контроль над сгенерированным SQL, если это необходимо
- Вы хотите работать с объектами, но не нуждаетесь в ленивой загрузке, обработке отношений, многоуровневом кэшировании, грязной проверке … Вам нужен CRUD и не намного
- Вы хотите, чтобы СУХОЙ
- Вы уже используете Spring или, может быть, даже
JdbcTemplate, но все еще чувствуете, что слишком много ручной работы - У вас очень мало таблиц базы данных
Начиная
Для большего количества примеров и рабочего кода не забудьте изучить тесты проекта .
Предпосылки
Maven координаты:
|
1
2
3
4
5
|
<dependency> <groupId>com.blogspot.nurkiewicz</groupId> <artifactId>jdbcrepository</artifactId> <version>0.1</version></dependency> |
К сожалению, проект еще не находится в центральном хранилище Maven . В настоящее время вы можете установить библиотеку в локальном хранилище, клонировав ее:
|
1
2
3
|
$ git clone git://github.com/nurkiewicz/spring-data-jdbc-repository.git$ git checkout 0.1$ mvn javadoc:jar source:jar install |
Для запуска вашего проекта должен присутствовать компонент DataSource и должно быть включено управление транзакциями. Вот минимальная конфигурация MySQL:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
@EnableTransactionManagement@Configurationpublic class MinimalConfig { @Bean public PlatformTransactionManager transactionManager() { return new DataSourceTransactionManager(dataSource()); } @Bean public DataSource dataSource() { MysqlConnectionPoolDataSource ds = new MysqlConnectionPoolDataSource(); ds.setUser("user"); ds.setPassword("secret"); ds.setDatabaseName("db_name"); return ds; } } |
Сущность с автоматически сгенерированным ключом
Допустим, у вас есть следующая таблица базы данных с автоматически сгенерированным ключом (синтаксис MySQL):
|
1
2
3
4
5
6
7
|
CREATE TABLE COMMENTS ( id INT AUTO_INCREMENT, user_name varchar(256), contents varchar(1000), created_time TIMESTAMP NOT NULL, PRIMARY KEY (id)); |
Сначала вам нужно создать объект домена, сопоставляющий User с этой таблицей (как и в любом другом ORM):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
public class Comment implements Persistable<Integer> { private Integer id; private String userName; private String contents; private Date createdTime; @Override public Integer getId() { return id; } @Override public boolean isNew() { return id == null; } //getters/setters/constructors/...} |
Помимо стандартного шаблона Java вы должны заметить реализацию Persistable<Integer> где Integer — это тип первичного ключа. Persistable<T> — это интерфейс из проекта Spring Data, и это единственное требование, которое мы предъявляем к вашему объекту домена.
Наконец, мы готовы создать наш CommentRepository DAO:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
@Repositorypublic class CommentRepository extends JdbcRepository<Comment, Integer> { public CommentRepository() { super(ROW_MAPPER, ROW_UNMAPPER, "COMMENTS"); } public static final RowMapper<Comment> ROW_MAPPER = //see below private static final RowUnmapper<Comment> ROW_UNMAPPER = //see below @Override protected Comment postCreate(Comment entity, Number generatedId) { entity.setId(generatedId.intValue()); return entity; }} |
Прежде всего мы используем аннотацию @Repository для пометки компонента DAO. Это делает возможным перевод исключений постоянства. Также такие аннотированные bean-компоненты обнаруживаются при сканировании CLASSPATH.
Как вы можете видеть, мы расширяем JdbcRepository<Comment, Integer> который является центральным классом этой библиотеки, предоставляя реализации всех методов PagingAndSortingRepository . Его конструктор имеет три обязательные зависимости: RowMapper , RowUnmapper и имя таблицы. Вы также можете указать имя столбца идентификатора, в противном случае используется "id" умолчанию.
Если вы когда-либо использовали JdbcTemplate из Spring, вы должны быть знакомы с интерфейсом RowMapper . Нам нужно как-то извлечь столбцы из ResultSet в объект. В конце концов, мы не хотим работать с необработанными результатами JDBC. Это довольно просто:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
public static final RowMapper<Comment> ROW_MAPPER = new RowMapper<Comment>() { @Override public Comment mapRow(ResultSet rs, int rowNum) throws SQLException { return new Comment( rs.getInt("id"), rs.getString("user_name"), rs.getString("contents"), rs.getTimestamp("created_time") ); }}; |
RowUnmapper происходит из этой библиотеки и, по сути, является противоположностью RowMapper : берет объект и превращает его в Map . Эта карта позже используется библиотекой для построения запросов SQL CREATE / UPDATE :
|
01
02
03
04
05
06
07
08
09
10
11
|
private static final RowUnmapper<Comment> ROW_UNMAPPER = new RowUnmapper<Comment>() { @Override public Map<String, Object> mapColumns(Comment comment) { Map<String, Object> mapping = new LinkedHashMap<String, Object>(); mapping.put("id", comment.getId()); mapping.put("user_name", comment.getUserName()); mapping.put("contents", comment.getContents()); mapping.put("created_time", new java.sql.Timestamp(comment.getCreatedTime().getTime())); return mapping; }}; |
Если вы никогда не обновляете свою таблицу базы данных (просто читая некоторые ссылочные данные, вставленные в другое место), вы можете пропустить параметр RowUnmapper или использовать MissingRowUnmapper .
Последняя часть головоломки — это postCreate() обратного вызова postCreate() который вызывается после вставки объекта. Вы можете использовать его для получения сгенерированного первичного ключа и обновления вашего доменного объекта (или возврата нового, если ваши доменные объекты неизменны). Если вам это не нужно, просто не переопределяйте postCreate() . Проверьте JdbcRepositoryGeneratedKeyTest для рабочего кода, основанного на этом примере.
К настоящему времени у вас может сложиться впечатление, что по сравнению с JPA или Hibernate довольно много ручной работы. Однако известно, что различные реализации JPA и другие среды ORM вносят значительные накладные расходы и демонстрируют некоторую кривую обучения. Эта крошечная библиотека намеренно оставляет некоторые обязанности для пользователя, чтобы избежать сложных отображений, размышлений, аннотаций … всей неявности, которая не всегда желательна. Этот проект не намеревается заменить зрелые и стабильные платформы ORM. Вместо этого он пытается заполнить нишу между необработанным JDBC и ORM, где простота и низкие издержки являются ключевыми характеристиками.
Сущность с назначенным вручную ключом
В этом примере мы увидим, как обрабатываются сущности с определяемыми пользователем первичными ключами. Начнем с модели базы данных:
|
1
2
3
4
5
6
|
CREATE TABLE USERS ( user_name varchar(255), date_of_birth TIMESTAMP NOT NULL, enabled BIT(1) NOT NULL, PRIMARY KEY (user_name)); |
… И модель домена User :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public class User implements Persistable<String> { private transient boolean persisted; private String userName; private Date dateOfBirth; private boolean enabled; @Override public String getId() { return userName; } @Override public boolean isNew() { return !persisted; } public User withPersisted(boolean persisted) { this.persisted = persisted; return this; } //getters/setters/constructors/... } |
Обратите внимание, что был добавлен специальный persisted переходный флаг. Контракт CrudRepository.save() из проекта Spring Data требует, чтобы объект знал, был ли он уже сохранен или нет ( isNew() ) — нет отдельных методов create() и update() . Реализация isNew() проста для автоматически сгенерированных ключей (см. Comment выше), но в этом случае нам нужно дополнительное переходное поле. Если вы ненавидите этот обходной путь, и вы только вставляете данные и никогда не обновляете, вам все время будет возвращаться значение true из isNew() .
И, наконец, UserRepository компонент DAO UserRepository :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
@Repositorypublic class UserRepository extends JdbcRepository<User, String> { public UserRepository() { super(ROW_MAPPER, ROW_UNMAPPER, "USERS", "user_name"); } public static final RowMapper<User> ROW_MAPPER = //... public static final RowUnmapper<User> ROW_UNMAPPER = //... @Override protected User postUpdate(User entity) { return entity.withPersisted(true); } @Override protected User postCreate(User entity, Number generatedId) { return entity.withPersisted(true); }} |
Параметры "USERS" и "user_name" обозначают имя таблицы и имя столбца первичного ключа. Я оставлю детали mapper и unmapper (см. Исходный код ). Но, пожалуйста, обратите внимание на postUpdate() и postCreate() . Они гарантируют, что после сохранения объекта устанавливается persisted флаг, чтобы последующие вызовы save() обновляли существующую сущность, а не пытались повторно ее вставить.
Проверьте JdbcRepositoryManualKeyTest для рабочего кода, основанного на этом примере.
Составной первичный ключ
Мы также поддерживаем составные первичные ключи (первичные ключи, состоящие из нескольких столбцов). Возьмите эту таблицу в качестве примера:
|
1
2
3
4
5
6
7
|
CREATE TABLE BOARDING_PASS ( flight_no VARCHAR(8) NOT NULL, seq_no INT NOT NULL, passenger VARCHAR(1000), seat CHAR(3), PRIMARY KEY (flight_no, seq_no)); |
Я хотел бы, чтобы вы заметили тип первичного ключа в Peristable<T> :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public class BoardingPass implements Persistable<Object[]> { private transient boolean persisted; private String flightNo; private int seqNo; private String passenger; private String seat; @Override public Object[] getId() { return pk(flightNo, seqNo); } @Override public boolean isNew() { return !persisted; } //getters/setters/constructors/... } |
К сожалению, мы не поддерживаем классы с небольшими значениями, инкапсулирующие все значения ID в одном объекте (как JPA делает с @IdClass ), поэтому вам придется жить с массивом Object[] . Определение класса DAO похоже на то, что мы уже видели:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
public class BoardingPassRepository extends JdbcRepository<BoardingPass, Object[]> { public BoardingPassRepository() { this("BOARDING_PASS"); } public BoardingPassRepository(String tableName) { super(MAPPER, UNMAPPER, new TableDescription(tableName, null, "flight_no", "seq_no") ); } public static final RowMapper<BoardingPass> ROW_MAPPER = //... public static final RowUnmapper<BoardingPass> UNMAPPER = //... } |
JdbcRepository<BoardingPass, Object[]> внимание на две вещи: мы расширяем JdbcRepository<BoardingPass, Object[]> и предоставляем два имени столбца идентификатора, как и ожидалось: "flight_no", "seq_no" . Мы запрашиваем такой DAO, предоставляя значения flight_no и seq_no (обязательно в этом порядке), заключенные в Object[] :
|
1
|
BoardingPass pass = repository.findOne(new Object[] {"FOO-1022", 42}); |
Без сомнения, на практике это громоздко, поэтому мы предоставляем крошечный вспомогательный метод, который вы можете статически импортировать:
|
1
2
3
4
|
import static com.blogspot.nurkiewicz.jdbcrepository.JdbcRepository.pk;//... BoardingPass foundFlight = repository.findOne(pk("FOO-1022", 42)); |
Проверьте JdbcRepositoryCompoundPkTest для рабочего кода, основанного на этом примере.
операции
Эта библиотека полностью ортогональна управлению транзакциями. Каждый метод каждого репозитория требует выполнения транзакции, и вы можете настроить ее. Обычно вы помещаете @Transactional на сервисный уровень (вызывая DAO-компоненты). Я не рекомендую размещать @Transactional над каждым компонентом DAO .
Кэширование
Библиотека репозитория Spring Data JDBC не обеспечивает абстрагирование или поддержку кэширования. Однако добавить слой @Cacheable поверх ваших DAO или сервисов, используя абстракцию кэширования в Spring , довольно просто. Смотрите также: @Cacheable overhead в Spring .
взносы
.. всегда рады. Не стесняйтесь отправлять сообщения об ошибках и тянуть запросы . Самая большая недостающая функция в настоящее время — поддержка баз данных MSSQL и Oracle. Было бы здорово, если бы кто-то мог взглянуть на это.
тестирование
Эта библиотека постоянно тестируется с использованием Travis (  ). Набор тестов состоит из 265 тестов (53 различных теста, каждый из которых выполняется на 5 разных базах данных: MySQL, PostgreSQL, H2, HSQLDB и Derby.
). Набор тестов состоит из 265 тестов (53 различных теста, каждый из которых выполняется на 5 разных базах данных: MySQL, PostgreSQL, H2, HSQLDB и Derby.
При заполнении отчетов об ошибках или при отправке новых функций попробуйте включить вспомогательные тестовые примеры. Каждый запрос на выборку автоматически тестируется в отдельной ветке.
Строительство
После разветвления официальный репозиторий построить так же просто, как запустить:
|
1
|
$ mvn install |
Вы заметите множество исключений во время выполнения теста JUnit. Это нормально. Некоторые из тестов работают с MySQL и PostgreSQL, которые доступны только на сервере Travis CI. Когда эти серверы баз данных недоступны, весь тест просто пропускается :
Полученные результаты :
|
1
|
Tests run: 265, Failures: 0, Errors: 0, Skipped: 106 |
Трассировки стека исключений берутся из корня AbstractIntegrationTest .
дизайн
Библиотека состоит только из нескольких классов, выделенных на диаграмме ниже:
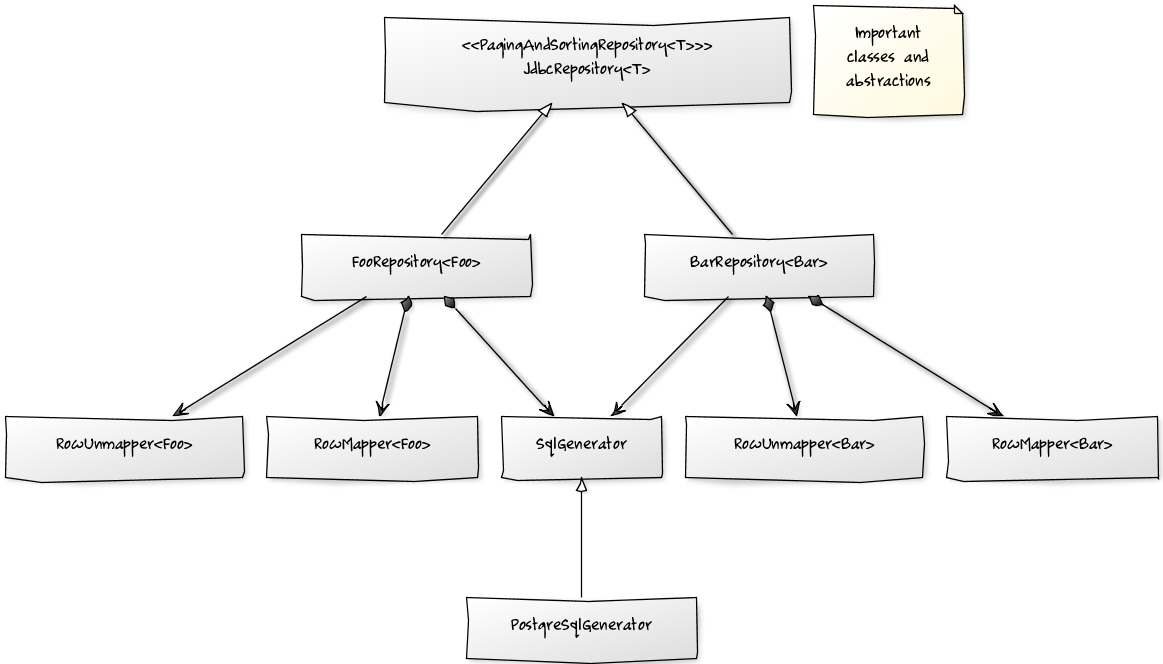
JdbcRepository является наиболее важным классом, который реализует все методы PagingAndSortingRepository . Каждый пользовательский репозиторий должен расширять этот класс. Также каждый такой репозиторий должен по крайней мере реализовывать RowMapper и RowUnmapper (только если вы хотите изменить данные таблицы).
Генерация SQL делегирована SqlGenerator . PostgreSqlGenerator. и DerbySqlGenerator предназначены для баз данных, которые не работают со стандартным генератором.
Лицензия
Этот проект выпущен под версией 2.0 лицензии Apache (так же, как Spring Framework ).
Ссылка: Распределение вероятностей для программистов от нашего партнера по JCG Томаша Нуркевича в блоге NoBlogDefFound .