Существуют разные методы многопоточности в Java. Можно распараллелить кусок кода в Java либо синхронизировать ключевые слова, блокировки или атомарные переменные. Этот пост будет сравнивать эффективность использования синхронизированного ключевого слова, ReentrantLock, getAndIncrement () и выполнения непрерывных испытаний вызовов get () и compareAndSet (). Для тестирования производительности созданы различные типы классов Matrix, в том числе и простой. Для сравнения, все ячейки увеличились в 100 раз для разных размеров матриц, с разными типами синхронизации, количеством потоков и размерами пула на компьютере с процессором Intel Core I7 (имеет 8 ядер — 4 из них действительные), Ubuntu 14.04 LTS и Java 1.7.0_60.
Это класс теста производительности в виде простой матрицы:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
/*** Plain matrix without synchronization.*/public class Matrix {private int rows;private int cols;private int[][] array;/*** Matrix constructor.** @param rows number of rows* @param cols number of columns*/public Matrix(int rows, int cols) {this.rows = rows;this.cols = cols;array = new int[rows][rows];}/*** Increments all matrix cells.*/public void increment() {for (int i = 0; i < rows; i++) {for (int j = 0; j < cols; j++) {array[i][j]++;}}}/*** Returns a string representation of the object which shows row sums of each row.** @return a string representation of the object.*/@Overridepublic String toString() {StringBuffer s = new StringBuffer();int rowSum;for (int i = 0; i < rows; i++) {rowSum = 0;for (int j = 0; j < cols; j++) {rowSum += array[i][j];}s.append(rowSum);s.append(" ");}return s.toString();}} |
Для других, методы приращения их перечислены, потому что остальные части одинаковы для каждого типа матрицы. Синхронизированная матрица:
|
1
2
3
4
5
6
7
8
9
|
public void increment() {for (int i = 0; i < rows; i++) {for (int j = 0; j < cols; j++) {synchronized (this) {array[i][j]++;}}}} |
Блокировка матрицы:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
public void increment() {for (int i = 0; i < rows; i++) {for (int j = 0; j < cols; j++) {lock.lock();try {array[i][j]++;} finally {lock.unlock();}}}} |
Атомная матрица getAndIncrement:
|
1
2
3
4
5
6
7
|
public void increment() {for (int i = 0; i < rows; i++) {for (int j = 0; j < cols; j++) {array[i][j].getAndIncrement();}}} |
Непрерывные испытания матрицы get () и compareAndSet ():
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
public void increment() {for (int i = 0; i < rows; i++) {for (int j = 0; j < cols; j++) {for (; ; ) {int current = array[i][j].get();int next = current + 1;if (array[i][j].compareAndSet(current, next)) {break;}}}}} |
Также рабочие классы создаются для каждой матрицы. Вот рабочий класс равнины:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
/*** Worker for plain matrix without synchronization.** @author Furkan KAMACI* @see Matrix*/public class PlainMatrixWorker extends Matrix implements Runnable {private AtomicInteger incrementCount = new AtomicInteger(WorkerDefaults.INCREMENT_COUNT);/*** Worker constructor.** @param rows number of rows* @param cols number of columns*/public PlainMatrixWorker(int rows, int cols) {super(rows, cols);}/*** Increments matrix up to a maximum number.** @see WorkerDefaults*/@Overridepublic void run() {while (incrementCount.getAndDecrement() > 0) {increment();}}} |
Для правильного сравнения на все тесты по умолчанию отвечают 20 раз. Средние и стандартные ошибки рассчитываются для каждого результата. Из-за большого количества измерений в наборе тестов (тип матрицы, размер матрицы, размер пула, количество потоков и истекшее время) некоторые функции отображаются в виде агрегированных данных на диаграммах. Вот результаты: Для размера пула 2 и количества потоков 2:
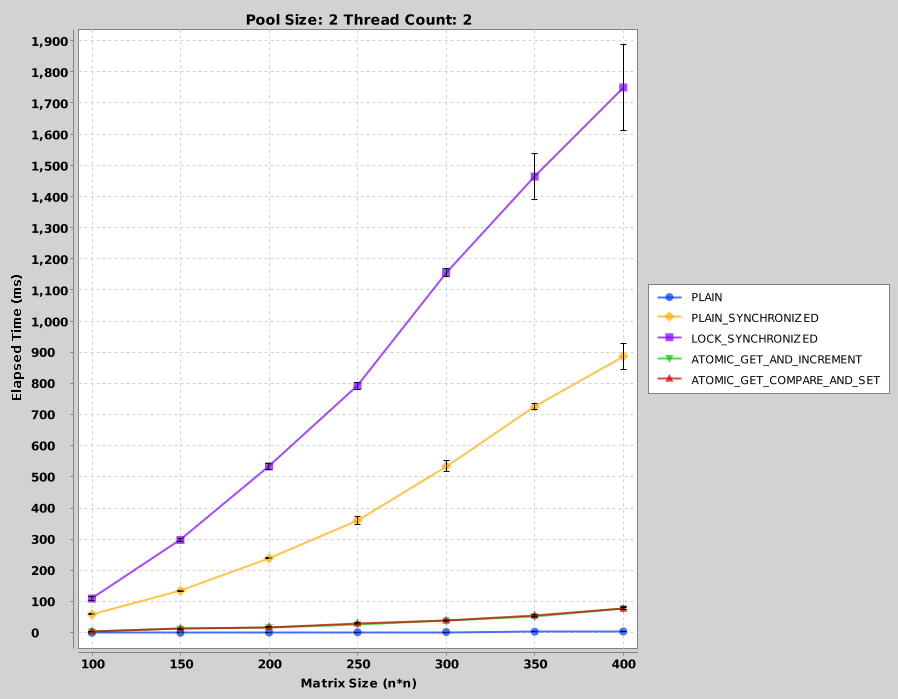
Для размера пула 4 и количества потоков 4:

Для размера пула 6 и количества потоков 6:

Для размера пула 8 и количества потоков 8:

Для размера пула 10 и количества потоков 10:
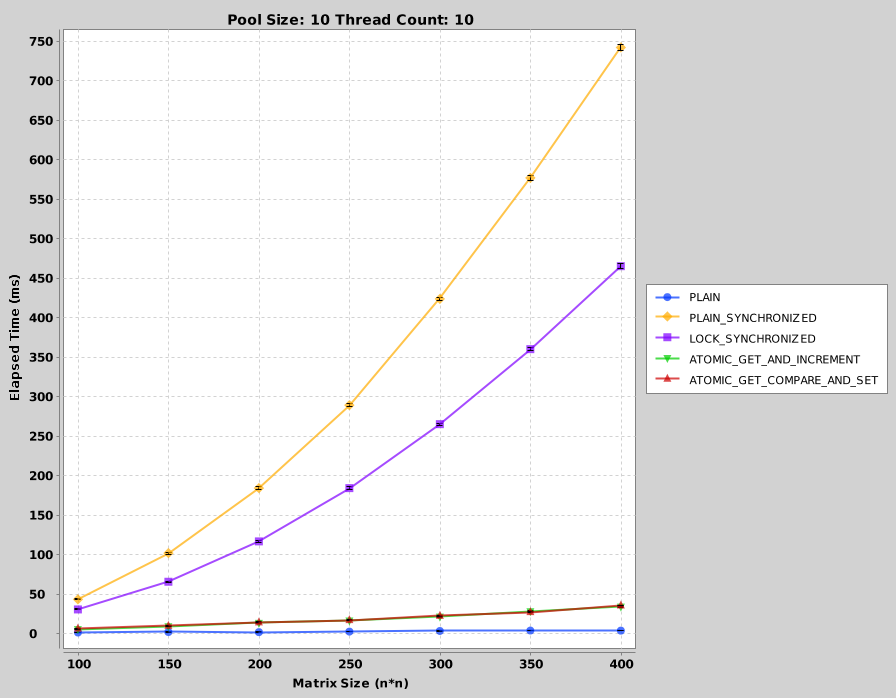
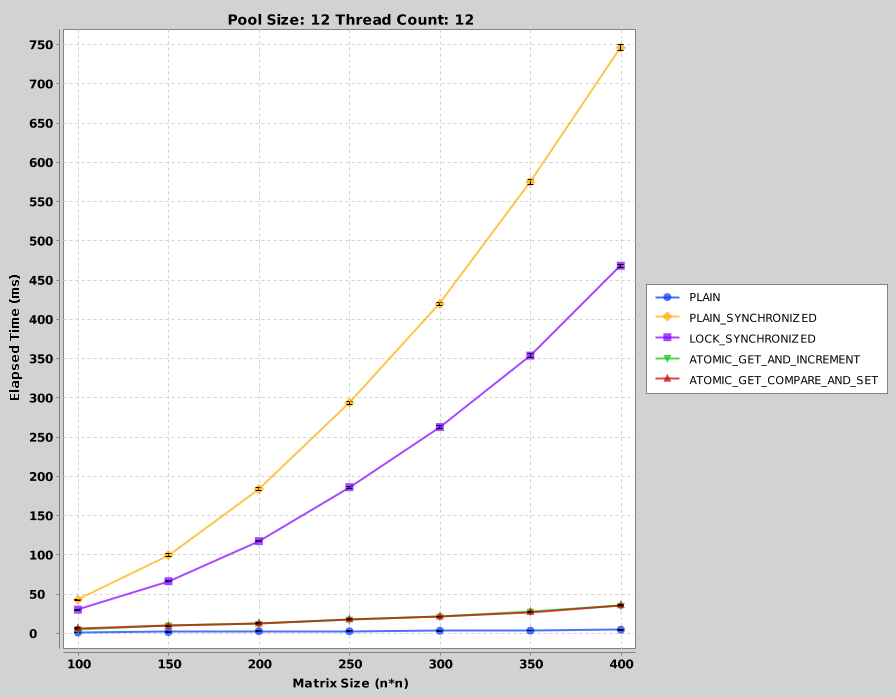
Для размера пула 12 и количества нитей 12:
Вывод
Легко увидеть, что простая версия работает быстрее всего. Однако это не дает правильных результатов, как ожидалось. Хуже производительность видна с синхронизированными блоками (когда синхронизация выполняется с « этим »). Замки немного лучше, чем синхронизированные блоки. Однако атомные переменные заметно лучше всех. При сравнении атомарных getAndIncrement и непрерывных испытаний вызовов get () и compareAndSet () показано, что их производительность одинакова. Причину этого легко понять, когда проверен исходный код Java:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
/*** Atomically increments by one the current value.** @return the previous value*/public final int getAndIncrement() {for (;;) {int current = get();int next = current + 1;if (compareAndSet(current, next))return current;}} |
Видно, что getAndIncrement реализован с помощью непрерывных испытаний get () и compareAndSet () в исходном коде Java (версия 1.7). С другой стороны, когда проверяются другие результаты, можно увидеть влияние размера пула. При использовании размера пула, который меньше фактического значения потока, может возникнуть проблема с производительностью. Итак, сравнение производительности многопоточности в Java показывает, что когда часть кода решается синхронизировать, а производительность является проблемой, и если потоки такого типа будут использоваться, как в тесте, следует попытаться использовать атомарные переменные. Другими вариантами должны быть блокировки или синхронизированные блоки. Также это не означает, что синхронизированные блоки всегда лучше блокировок из-за эффекта JIT-компилятора и запуска фрагмента кода несколько раз или нет.
- Исходный код для сравнения производительности многопоточности в Java можно скачать здесь: https://github.com/kamaci/performance
| Ссылка: | Сравнение производительности многопоточности на Java от нашего партнера по JCG Фуркана Камачи в блоге FURKAN KAMACI . |