Spring XD — это мощный инструмент, представляющий собой устанавливаемый набор сервисов Spring Boot, которые работают либо автономно, либо над YARN, либо над EC2. Spring XD также включает веб-сайт интерфейса администратора и инструмент командной строки для управления заданиями и потоками. Spring XD — это мощный набор сервисов, которые работают с различными источниками данных.
Для идеального использования он должен работать внутри кластера Apache Spark или Hadoop. В первом разделе мы настроим запуск XD на машине Centos / RHEL с необходимыми службами данных. Они предназначены для инфраструктуры, необходимой для работы, а также для приема данных. Вы можете интегрировать существующие RDBMS, MongoDB, Kafka, Apache Spark, Hadoop, REST, RabbitMQ и другие сервисы.
Вы также можете установить XD на Mac, Windows и другие дистрибутивы Linux. Для базового использования на компьютере разработчика просто загрузите Spring XD с веб-сайта Spring.IO и запустите xd / xd / bin / xd-standalone, и этого будет достаточно для запуска загрузки данных.
1. Spring XD Setup
Во-первых, давайте установим Spring XD на ваш сервер Linux, отметив требования к запуску. Если у вас нет необходимых сервисов, загрузка XD включает их версию для запуска.
Ссылка:
- http://docs.spring.io/spring-xd/docs/current/reference/html/#_redhat_centos_installation
- https://github.com/spring-projects/spring-xd/wiki/Running-Distributed-Mode
- https://github.com/spring-projects/spring-xd/wiki/XD-Distributed-Runtime
Требования:
- Apache Zookeeper 3.4.6
- Redis
- СУБД (MySQL, Postgresql, Apache Derby и т. Д.)
обогатителей:
- GemFire (настоятельно рекомендуется для сетки данных в памяти)
- GemFire XD (настоятельно рекомендуется для базы данных в памяти)
- RabbitMQ (настоятельно рекомендуется)
- Apache Yarn
Установка MySQL на Centos / RHEL / Fedora
Реляционная база данных необходима для хранения информации о вашей работе, в то время как может использоваться СУБД в памяти, для реального использования — СУБД. Если у вас есть СУБД, которая доступна из вашего кластера XD, вы можете использовать ее. Я предпочитаю использовать базу данных с открытым исходным кодом только для XD, для этого вы можете установить MySQL или Postgresql.
|
1
|
sudo yum install mysql-server |
Установите Postgresql (не устанавливайте на тот же компьютер, что и GreenPlum)
|
1
|
sudo yum install postgresql-server |
Установка Redis
(См. RabbitMQ)
|
1
2
3
4
|
ᅠwget -q -O – http://packages.pivotal.io/pub/rpm/rhel6/app-suite/app-suite-installer | shᅠ ᅠ ᅠ ᅠ ᅠ ᅠsudo yum install pivotal-redisᅠ ᅠ ᅠ ᅠ ᅠ ᅠsudo service pivotal-redis-6379 startᅠ ᅠ ᅠ ᅠ ᅠ ᅠsudo chkconfig —level 35 pivotal-redis-6379 on |
Установка RabbitMQ
Требуется RabbitMQ, даже если у вас есть другая очередь сообщений. Достаточно одного узла, но он необходим для связи. Я настоятельно рекомендую иметь реальный кластер RMQ, поскольку он соответствует большинству потоковых потребностей.
|
1
2
3
|
ᅠsudo wget -q -O – packages.pivotal.io | shsudo wget -q -O – http://packages.pivotal.io/pub/rpm/rhel6/app-suite/app-suite-installer | sh |
В зависимости от разрешений вам, возможно, придется отправить это в файл, выполнить chmod 700 и запустить его с помощью sudo ./installer.sh
|
1
2
3
4
5
6
|
ᅠsudo yum search pivotal pivotal-rabbitmq-server.noarch: The RabbitMQ serversudo yum install pivotal-rabbitmq-serversudo rabbitmq-plugins enable rabbitmq_management ᅠ ᅠ |
Это может привести к конфликту с портами, если вы выполняете другие операции на этом компьютере.
|
1
2
|
ᅠsudo /sbin/service rabbitmq-server start |
Установить Spring-XD
Самый простой способ установки — использовать официальные выпуски Pivotal для RHEL, поскольку они сертифицированы. Вам не нужно быть клиентом, чтобы использовать их. Существует несколько других способов загрузки / установки XD, но это самый простой способ для RHEL, поскольку он настраивает их как службы.
|
1
2
3
|
sudo wget -q -O – http://packages.pivotal.io/pub/rpm/rhel6/app-suite/app-suite-installer sh sudo yum install spring-xd |
Рекомендация
Также рекомендуется развернуть узлы XD и DataNode в одном контейнере и использовать разбиение данных. Это ускорит обработку данных и прием пищи.
Настройка вашей базы данных вакансий
Измените источник данных, выберите один из приведенных ниже вариантов для простоты настройки. В базе данных заданий хранятся информация и метаданные задания Spring XD. Это необходимо Это будет очень маленький объем данных.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
/opt/pivotal/spring-xd/xd/configᅠ#spring:# ᅠdatasource:# ᅠ ᅠurl: jdbc:mysql://mysqlserver:3306/xdjobs# ᅠ ᅠusername: xdjobsschema# ᅠ ᅠpassword: xdsecurepassword# ᅠ ᅠdriverClassName: com.mysql.jdbc.Driver# ᅠ ᅠvalidationQuery: select 1#Config for use with Postgres - uncomment and edit with relevant values for your environment#spring:# ᅠdatasource:# ᅠ ᅠurl: jdbc:postgresql://postgresqlserver:5432/xdjobs# ᅠ ᅠusername: xdjobsschema# ᅠ ᅠpassword: xdsecurepassword# ᅠ ᅠdriverClassName: org.postgresql.Driver# ᅠ ᅠvalidationQuery: select 1 |
Проверьте, работает ли один узел Spring-XD:
|
1
2
|
cd /opt/pivotal/springxd/xd/bin./xd-singlenode —hadoopDistro phd20 |
Если вы используете дистрибутив Hadoop, отличный от Pivotal HD 2.0, вы можете указать это здесь или оставить этот флаг выключенным.
Проверьте, работает ли Spring-XD Shell
|
1
2
|
cd /opt/pivotal/springxd/shell/binᅠ ᅠ ./xd-shell—hadoopDistro phd20 |
В оболочке есть справка и ярлыки, просто начните печатать, а табуляция разрешит вам имена и параметры.
Установите переменную среды для Spring XD
|
1
|
export XD_HOME=/opt/pivotal/spring-xd/xd |
Для доступа по умолчанию я использую:
|
1
|
/opt/pivotal/spring-xd/shell/bin/xd-shell —hadoopDistro phd20 |
Для тестирования контейнеров и серверов администрирования для распределенной Spring XD (DIRT)
|
1
2
|
sudo service spring-xd-admin startsudo service spring-xd-container start |
Для тестирования Spring XD
- http://blog.pivotal.io/pivotal/products/spring-xd-for-real-time-analytics
- https://github.com/spring-projects/spring-xd-samples
Некоторые команды Spring XD Shell для тестирования
|
1
2
3
4
5
6
7
8
9
|
had config fs —namenode hdfs://pivhdsne:8020admin config server http://localhost:9393runtime containersruntime moduleshadoop fs ls /xd/stream create ticktock —definition “time | log”stream deploy ticktockstream list |
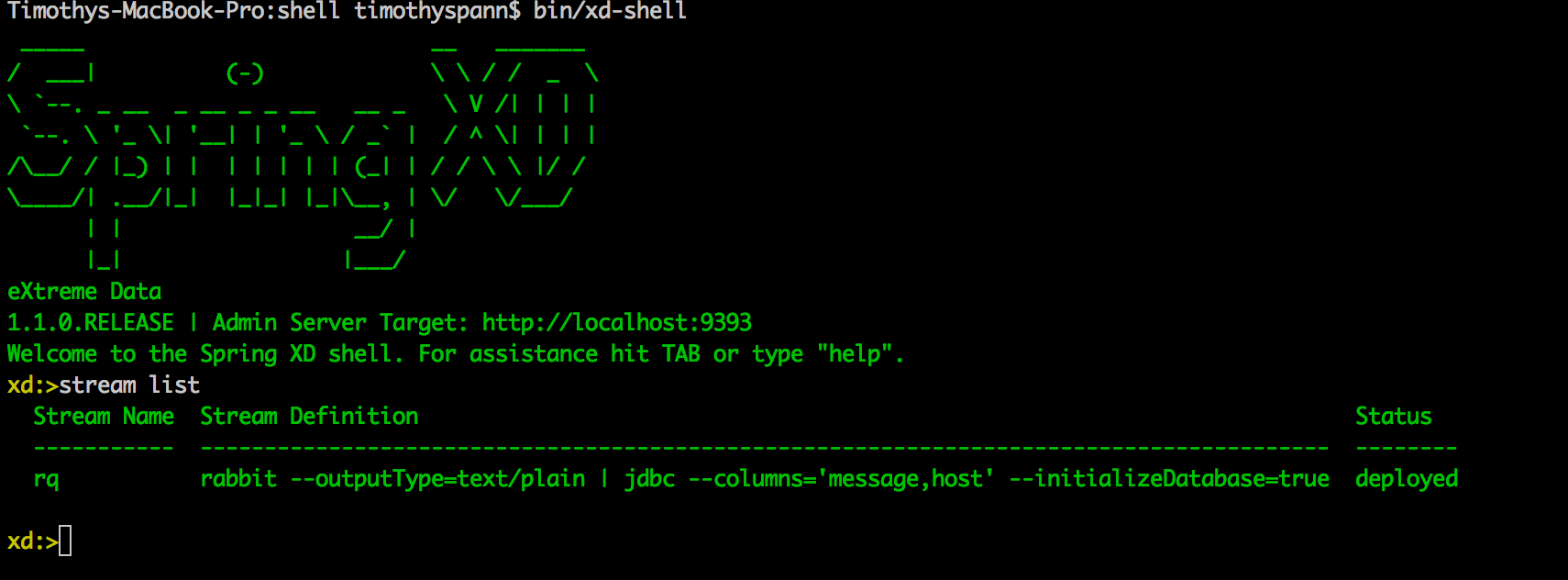
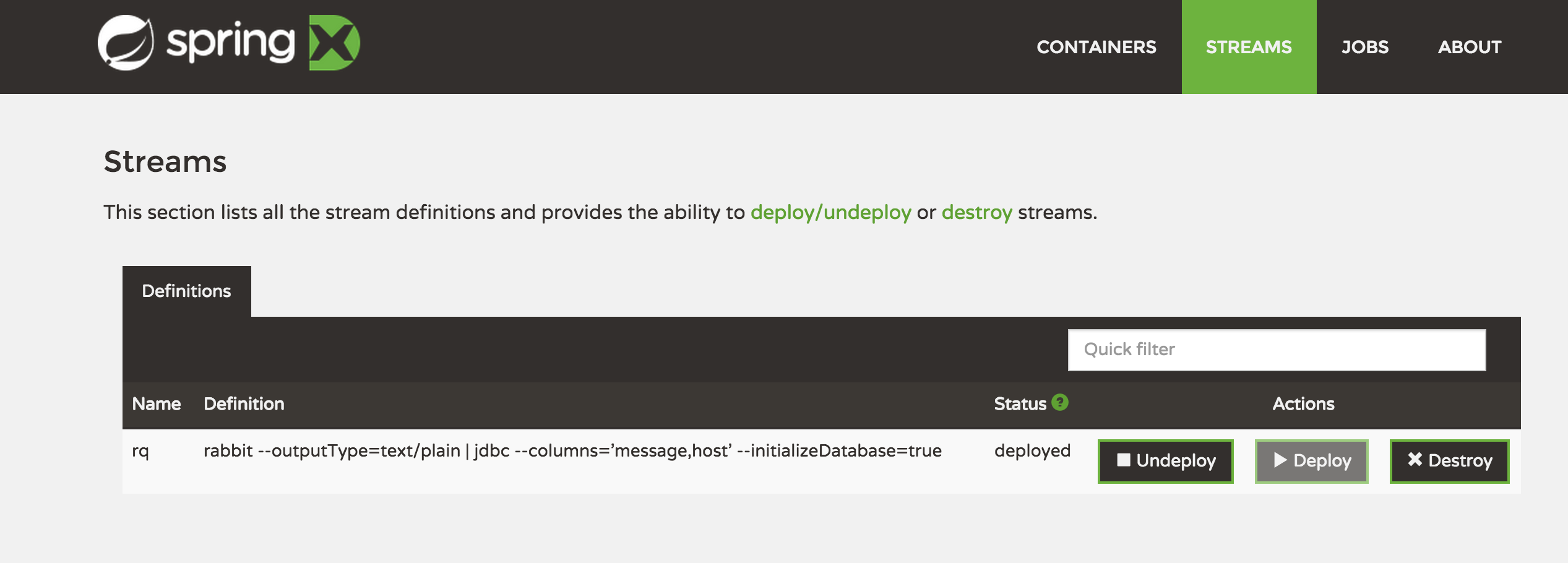
Проверьте веб-интерфейс
2. Spring XD Job и Stream с SQL
Предостережение: полные списки полей сокращены ради пространства, вы должны перечислить все поля, с которыми вы работаете.
Сначала мы создадим простое filejdbc Spring Job, которое загружает необработанный файл с разделителями тильды в HAWQ . Все эти поля входят как поля TEXT, что может быть хорошо для некоторых целей, но не для наших нужд. Мы также создаем поток XD с пользовательским приемником (см. XML, без кодирования), который запускает команду SQL для вставки из этой таблицы и преобразования в другие типы HAWQ (например, числа и время).
Мы запускаем вторичный поток через командную строку REST POST, но мы могли бы использовать синхронизированный триггер или многие другие способы (автоматический, сценарий или ручной), чтобы запустить его. Вы также можете просто создать пользовательское задание XD, которое выполняло приведение типов и некоторые манипуляции или делало это с помощью преобразования скрипта Groovy. Там много вариантов в XD .
jobload.xd
|
1
2
3
4
5
6
7
8
9
|
job create loadjob --definition "filejdbc --resources=file:/tmp/xd/input/files/*.* --names=time,userid,dataname,dataname2,dateTimeField, lastName, firstName, city, state, address1, address2 --tableName=raw_data_tbl --initializeDatabase=true--driverClassName=org.postgresql.Driver --delimiter=~ --dateFormat=yyyy-MM-dd-hh.mm.ss --numberFormat=%d --username=gpadmin --url=jdbc:postgresql:gpadmin" --deploystream create --name streamload --definition "http | hawq-store" --deployjob launch jobloadclearjob liststream list |
- Job загружает файл в таблицу Raw HAWQ со всеми текстовыми столбцами.
- Поток запускается нажатием веб-страницы или вызовом командной строки
(нужен hawq-магазин). Это вставляет в реальную таблицу и усекает временную.
triggerrun.sh (скрипт оболочки BASH для тестирования)
|
1
|
curl -s -H "Content-Type: application/json" -X POST -d "{id:5}" http://localhost:9000 |
добавлен JAR-файл JDBC Spring-Integration в / opt / pivotal / spring-xd / xd / lib
hawq-store.xml (Spring Integration / XD Configuration)
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
/opt/pivotal/spring-xd/xd/modules/sink/hawq-store.xml<?xml version="1.0" encoding="UTF-8"?> xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:int="http://www.springframework.org/schema/integration" xsi:schemaLocation="http://www.springframework.org/schema/beans<int:channel id="input" /><int-jdbc:store-outbound-channel-adapter channel="input" query="insert into real_data_tbl(time, userid, firstname, ...) select cast(time as datetime), cast(userid as numeric), firstname, ... from dfpp_networkfillclicks" data-source="dataSource" /><bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource"> <property name="driverClassName" value="org.postgresql.Driver"/> <property name="url" value="jdbc:postgresql:gpadmin"/> <property name="username" value="gpadmin"/> <property name="password" value=""/></bean></beans> |
createtable.sql
|
1
2
3
4
5
6
7
8
9
|
CREATE TABLEᅠraw_data_tbl ( time text, userid text ,... somefieldᅠtext ) WITH (APPENDONLY=true) DISTRIBUTED BY (time); |
3. Spring XD Сценарии для оболочки
Мой сценарий общей настройки (я сохраняю его в файле setup.xd и загружаю его через скрипт – script –file setup.xd )
|
1
2
3
4
|
had config fs --namenode hdfs://localhost:8020admin config server http://localhost:9393hadoop fs ls /stream list |
Скрипт для загрузки файла в GemFireXD через Spring-XD
|
1
|
stream create --name fileload --definition "file --dir=/tmp/xd/input/load --outputType=text/plain | ᅠjdbc --tableName=APP.filetest --columns=id,name" --deploy |
4. Конфигурация Spring XD для GemFire XD
Скопируйте драйвер JDBC GemFire XD в Spring-XD (может также потребоваться tools.jar)
|
1
|
cp /usr/lib/gphd/Pivotal_GemFireXD_10/lib/gemfirexd-client.jar /opt/pivotal/spring-xd/xd/lib/ |
Измените свойства JDBC Sink, чтобы они указывали на Gemfire XD. Если вы используете виртуальную машину Pivotal HD и устанавливаете Spring-XD с Yum (sudo yum update spring-xd), это расположение:
|
1
2
3
4
5
|
/opt/pivotal/spring-xd/xd/config/modules/sink/jdbc/jdbc.propertiesurl = jdbc:gemfirexd://localhost:1527username = gfxdpassword = gfxddriverClassName = com.pivotal.gemfirexd.jdbc.ClientDriver |
Для Peer Client Driver вам нужно больше файлов из GemFireXD Lib (двоичные файлы .so), связывание, вероятно, хорошая идея.
5. Настройка GemFire XD
|
1
2
3
4
5
6
|
gfxdconnect client 'localhost:1527';create table filetest (id int, name varchar(100)) REPLICATE PERSISTENT;select id, kind, netservers from sys.members;ᅠselect * from filetest; |
Spring XD Commands
|
1
|
stream list |
покажи свои потоки
Ссылка:
- Spring XD Документация
- Spring XD Wiki
- Установите Spring XD на Centos
- GemFire XD Documents
- Загрузка файла Spring XD в JDBC ᅠ
- Spring XD с Hadoop
6. Загрузка данных из RabbitMQ в RDBMS через Spring XD
Простой поток для чтения из очереди кроликов с именем «rq» и отправки его в базу данных SQL со столбцами «message and host», создав новую таблицу с именем «rq».
|
1
|
stream create --name rq --definition "rabbit --outputType=text/plain | jdbc --columns='message,host' --initializeDatabase=true" --deploy |
7. Вставка данных из API REST в HDFS через Spring XD
|
1
|
stream create --name hdfssave --definition "http | hdfs" –deploy |