Моя цель здесь — показать, как Spring Kafka предоставляет абстракцию для сырых API Kafka Producer и Consumer, которые просты в использовании и знакомы кому-то с опытом работы в Spring.
Пример сценария
Пример сценария прост: у меня есть система, которая создает сообщение, и другая, которая его обрабатывает.
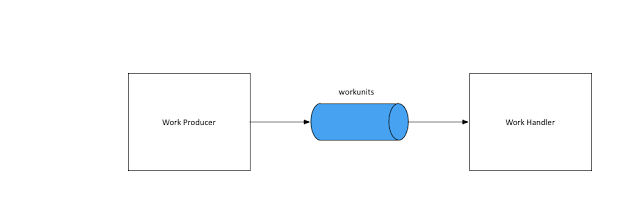
Реализация с использованием Raw Kafka Producer / Consumer API
Для начала я использовал сырые API Kafka Producer и Consumer для реализации этого сценария. Если вы предпочитаете смотреть код, он доступен в моем репозитории github здесь .
Режиссер
Далее настраивается экземпляр KafkaProducer, который используется для отправки сообщения в тему Kafka:
|
1
2
|
KafkaProducer<String, WorkUnit> producer = new KafkaProducer<>(kafkaProps, stringKeySerializer(), workUnitJsonSerializer()); |
Я использовал вариант конструктора KafkaProducer, который использует собственный сериализатор для преобразования объекта домена в представление json.
Как только экземпляр KafkaProducer станет доступен, его можно будет использовать для отправки сообщения в кластер Kafka, здесь я использовал синхронную версию отправителя, которая ждет ответа, который должен быть возвращен.
|
1
2
3
4
|
ProducerRecord<String, WorkUnit> record = new ProducerRecord<>("workunits", workUnit.getId(), workUnit);RecordMetadata recordMetadata = this.workUnitProducer.send(record).get(); |
потребитель
На стороне потребителя мы создаем KafkaConsumer с вариантом конструктора, принимающего десериализатор, который знает, как прочитать сообщение json и преобразовать его в экземпляр домена:
|
1
|
KafkaConsumer<String, WorkUnit> consumer |
|
1
|
= new KafkaConsumer<>(props, stringKeyDeserializer() |
|
1
|
, workUnitJsonValueDeserializer()); |
Как только экземпляр KafkaConsumer становится доступным, можно создать цикл слушателя, который читает пакет записей, обрабатывает их и ожидает поступления новых записей:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
consumer.subscribe("workunits);try { while (true) { ConsumerRecords<String, WorkUnit> records = this.consumer.poll(100); for (ConsumerRecord<String, WorkUnit> record : records) { log.info("consuming from topic = {}, partition = {}, offset = {}, key = {}, value = {}", record.topic(), record.partition(), record.offset(), record.key(), record.value()); } }} finally { this.consumer.close();} |
Реализация с использованием Spring Kafka
У меня есть реализация с использованием Spring-kafka, доступная в моем репозитории github .
Режиссер
Spring-Kafka предоставляет класс KafkaTemplate в качестве оболочки над KafkaProducer для отправки сообщений в тему Kafka:
|
01
02
03
04
05
06
07
08
09
10
11
|
@Beanpublic ProducerFactory<String, WorkUnit> producerFactory() { return new DefaultKafkaProducerFactory<>(producerConfigs(), stringKeySerializer(), workUnitJsonSerializer());}@Beanpublic KafkaTemplate<String, WorkUnit> workUnitsKafkaTemplate() { KafkaTemplate<String, WorkUnit> kafkaTemplate = new KafkaTemplate<>(producerFactory()); kafkaTemplate.setDefaultTopic("workunits"); return kafkaTemplate;} |
Стоит отметить, что, хотя ранее я реализовал пользовательский сериализатор / десериализатор для отправки типа домена как json, а затем для его конвертации обратно, Spring-Kafka предоставляет Seralizer / Deserializer для json из коробки.
И используя KafkaTemplate для отправки сообщения:
|
1
2
3
4
5
6
7
|
SendResult<String, WorkUnit> sendResult = workUnitsKafkaTemplate.sendDefault(workUnit.getId(), workUnit).get();RecordMetadata recordMetadata = sendResult.getRecordMetadata();LOGGER.info("topic = {}, partition = {}, offset = {}, workUnit = {}", recordMetadata.topic(), recordMetadata.partition(), recordMetadata.offset(), workUnit); |
потребитель
Потребительская часть реализована с использованием шаблона Listener, который должен быть знаком любому, кто внедрил прослушиватели для RabbitMQ / ActiveMQ. Вот первая конфигурация для настройки контейнера слушателя:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
@Beanpublic ConcurrentKafkaListenerContainerFactory<String, WorkUnit> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<String, WorkUnit> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConcurrency(1); factory.setConsumerFactory(consumerFactory()); return factory;}@Beanpublic ConsumerFactory<String, WorkUnit> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerProps(), stringKeyDeserializer(), workUnitJsonValueDeserializer());} |
и сервис, который отвечает на сообщения, прочитанные контейнером:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
@Servicepublic class WorkUnitsConsumer { private static final Logger log = LoggerFactory.getLogger(WorkUnitsConsumer.class); @KafkaListener(topics = "workunits") public void onReceiving(WorkUnit workUnit, @Header(KafkaHeaders.OFFSET) Integer offset, @Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) { log.info("Processing topic = {}, partition = {}, offset = {}, workUnit = {}", topic, partition, offset, workUnit); }} |
Здесь все сложности настройки цикла слушателя, как с необработанным потребителем, исключаются и хорошо скрываются контейнером слушателя.
Вывод
Я ознакомился со многими внутренними компонентами настройки размеров партии, вариаций подтверждения, разных сигнатур API. Мое намерение состоит в том, чтобы просто продемонстрировать пример общего использования с использованием сырых API Kafka и показать, как оболочка Spring-Kafka упрощает его.
Если вы заинтересованы в дальнейших исследованиях, образец потребительского сырья можно найти здесь, а Spring Kafka — здесь.
| Ссылка: | Spring Kafka Producer / Consumer образец от нашего партнера JCG Биджу Кунджуммен в блоге « все и вся» . |