Это пакетное руководство Spring, которое является частью среды Spring. Spring Batch предоставляет многократно используемые функции, которые необходимы для обработки больших объемов записей, включая ведение журнала / трассировку, управление транзакциями, статистику обработки заданий, перезапуск заданий, пропуск и управление ресурсами. Он также предоставляет более продвинутые технические услуги и функции, которые позволят выполнять пакетные задания чрезвычайно большого объема и с высокой производительностью благодаря методам оптимизации и разделения.
Здесь вы можете найти четкое объяснение его основных компонентов и концепций, а также несколько рабочих примеров. Этот учебник не о платформе Spring в целом; ожидается, что вы знакомы с такими механизмами, как Inversion of Control и Dependency Injection, которые являются основными опорами среды Spring. Предполагается также, что вы знаете, как настроить контекст среды Spring для базовых приложений, и что вы привыкли работать с аннотациями и файлами конфигурации на основе проектов Spring.
Если это не так, я бы порекомендовал перейти на официальную страницу Spring Framework и изучить основные учебные пособия, прежде чем начать изучать, что такое Spring batch и как он работает. Вот очень хороший: http://docs.spring.io/docs/Spring-MVC-step-by-step/ .
В конце этого урока вы можете найти сжатый файл со всеми перечисленными примерами и некоторыми дополнениями.
Программное обеспечение, использованное при разработке этого руководства, перечислено ниже:
- Java обновление 8 версия 3.1
- Apache Maven 3.2.5
- Затмение Луны 4.4.1
- Spring Batch 3.0.3 и все его зависимости (я действительно рекомендую использовать Maven или Gradle, чтобы разрешить все необходимые зависимости и избежать головной боли)
- Spring Boot 1.2.2 и все его зависимости (я действительно рекомендую использовать Maven или Gradle, чтобы разрешить все необходимые зависимости и избежать головной боли)
- MySQL Community Server версия 5.6.22
- MongoDB 2.6.8
- HSQLDB версия 1.8.0.10
В этом руководстве не будет объяснено, как использовать Maven, хотя оно используется для решения зависимостей, компиляции и выполнения предоставленных примеров. Дополнительную информацию можно найти в следующей статье http://examples.javacodegeeks.com/enterprise-java/maven/log4j-maven-example/ .
Модуль Spring boot также активно используется в примерах, для получения дополнительной информации о нем, пожалуйста, обратитесь к официальной документации Spring Boot: http://projects.spring.io/spring-boot/ .
Содержание
- 1. Введение
- 2. Концепции
- 3. Используйте случаи
- 4 Контроль потока
- 5. Пользовательские Писатели, Читатели и Процессоры
- 6. Пример плоского файла
- 7. Пример MySQL
- 8. В памяти пример
- 9. Модульное тестирование
- 10. Обработка ошибок
- 11. Параллельная обработка
- 12. Повторение работы
- 13. JSR 352
- 14. Резюме
- 15. Ресурсы
- 16. Скачать
1. Введение
Spring Batch — это среда с открытым исходным кодом для пакетной обработки. Он построен как модуль внутри среды Spring и зависит от этой среды (среди прочих). Перед тем, как продолжить Spring Batch, мы собираемся поместить здесь определение пакетной обработки:
«Пакетная обработка — это выполнение ряда программ (« заданий ») на компьютере без ручного вмешательства» (из Википедии).
Таким образом, в нашем случае пакетное приложение выполняет серию заданий (итеративных или параллельных), где входные данные считываются, обрабатываются и записываются без какого-либо взаимодействия. Мы посмотрим, как Spring Batch может помочь нам в этом.
Spring Batch предоставляет механизмы для обработки большого количества данных, такие как управление транзакциями, обработка заданий, управление ресурсами, ведение журналов, трассировка, преобразование данных, интерфейсы и т. Д. Эти функции доступны «из коробки» и могут повторно использоваться приложениями, содержащими Spring Batch. фреймворк. Используя эти разнообразные методы, платформа заботится о производительности и масштабируемости при обработке записей.
Обычно пакетное приложение можно разделить на три основные части:
- Чтение данных (из базы данных, файловой системы и т. Д.)
- Обработка данных (фильтрация, группировка, расчет, проверка …)
- Запись данных (в базу данных, отчетность, распространение…)
Spring Batch содержит функции и абстракции (как мы объясним в этой статье) для автоматизации этих основных шагов и позволяет разработчикам приложений настраивать их, повторять их, повторять их, останавливать их, выполняя их как отдельный элемент или сгруппированные (управление транзакциями) , и т.д.
Он также содержит классы и интерфейсы для основных форматов данных, отраслевых стандартов и поставщиков, таких как XML, CSV, SQL, Mongo DB и т. Д.
В следующих главах этого руководства мы собираемся объяснить и предоставить примеры всех этих шагов и возможностей различий, которые предлагает Spring Batch.
2. Концепции
Вот наиболее важные концепции в среде Spring Batch:
работы
Задания — это абстракции для представления пакетных процессов, то есть последовательности действий или команд, которые должны выполняться внутри пакетного приложения.
Spring batch содержит следующий интерфейс для представления рабочих мест: http://docs.spring.io/spring-batch/apidocs/org/springframework/batch/core/Job.html . Простые задания содержат список шагов, которые выполняются последовательно или параллельно.
Для настройки задания достаточно инициализировать список шагов, это пример конфигурации на основе xml для фиктивного задания:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
<step id="stepCook" next="stepEntries"> <tasklet> <chunk reader="cookReader" writer="cookProcessor" processor="cookWriter" commit-interval="1" /> </tasklet> </step> <step id="stepEntries" next="stepMeat"> <tasklet> <chunk reader="entriesReader" writer="entriesProcessor" processor="entriesWriter" commit-interval="1" /> </tasklet> </step> <step id="stepMeat" next="stepWine"> <tasklet ref="drinkSomeWine" /> </step> <step id="stepWine" next="clean"> <tasklet> <chunk reader="wineReader" writer="wineProcessor" processor="wineWriter" commit-interval="1" /> </tasklet> </step> <step id="clean"> <tasklet ref="cleanTheTable" /> </step> </job> |
Job launcher
Этот интерфейс http://docs.spring.io/spring-batch/apidocs/org/springframework/batch/core/launch/JobLauncher.html представляет модуль запуска работ. Реализации его метода run() заботятся о запуске выполнения заданий для заданных заданий и параметров задания.
Экземпляр задания
Это абстракция, представляющая один прогон для данного задания. Это уникальный и узнаваемый. Класс, представляющий эту абстракцию: http://docs.spring.io/spring-batch/apidocs/org/springframework/batch/core/JobInstance.html .
Экземпляры задания могут быть перезапущены, если они не были успешно завершены, и если задание может быть перезапущено. В противном случае возникнет ошибка.
меры
Шаги — это в основном части, составляющие задание (и экземпляр задания). Step является частью Job и содержит всю необходимую информацию для выполнения действий пакетной обработки, которые, как ожидается, будут выполнены на этом этапе задания. Шаги в Spring Batch состоят из ItemReader , ItemProcessor и ItemWriter и могут быть очень простыми или чрезвычайно сложными в зависимости от сложности их членов.
Шаги также содержат параметры конфигурации для их стратегии обработки, интервала фиксации, механизма транзакций или репозиториев заданий, которые могут использоваться. Spring Batch обычно использует обработку чанков, то есть считывание всех данных за один раз, а также обработку и запись «чанков» этих данных в предварительно настроенный интервал, называемый интервалом фиксации.
Вот очень простой пример конфигурации шага на основе XML с интервалом 10:
|
1
2
3
4
5
|
<step id="step" next="nextStep"> <tasklet> <chunk reader="customItemReader" writer="customItemWriter" processor="customItemProcessor" commit-interval="10" /> </tasklet></step> |
А следующий фрагмент — это версия на основе аннотаций, определяющая задействованных читателей, писателей и процессоров, стратегию обработки чанков и интервал фиксации 10 (именно этот мы используем в большинстве примеров в этом уроке):
|
1
2
3
4
5
6
7
8
9
|
@Beanpublic Step step1(StepBuilderFactory stepBuilderFactory, ItemReader reader, ItemWriter writer, ItemProcessor processor) { /* it handles bunches of 10 units */ return stepBuilderFactory.get("step1") . chunk(10).reader(reader) .processor(processor).writer(writer).build();} |
Репозитории вакансий
Репозитории заданий — это абстракции, отвечающие за хранение и обновление метаданных, относящихся к выполнению экземпляров заданий и контекстам заданий. Базовый интерфейс, который должен быть реализован для настройки репозитория заданий, является http://docs.spring.io/spring-batch/apidocs/org/springframework/batch/core/repository/JobRepository.html .
Spring хранит в качестве метаданных информацию об их выполнении, полученных результатах, их экземплярах, параметрах, используемых для выполненных заданий, и контексте, в котором выполняется обработка. Имена таблиц очень интуитивны и похожи на их аналоги классов доменов, в этой ссылке есть изображение с очень хорошим резюме этих таблиц: http://docs.spring.io/spring-batch/reference/html/images/ meta-data-erd.png .
{kind=link}
Для получения дополнительной информации о схеме метаданных Spring Batch посетите страницу http://docs.spring.io/spring-batch/reference/html/metaDataSchema.html .
Пункт Читатели
Читатели — это абстракции, отвечающие за поиск данных. Они обеспечивают приложения пакетной обработки необходимыми входными данными. В этом руководстве мы увидим, как создавать собственные программы чтения, и мы увидим, как использовать некоторые из наиболее важных предопределенных Spring Batch. Вот список некоторых читателей, предоставленных Spring Batch:
- AmqpItemReader
- AggregateItemReader
- FlatFileItemReader
- HibernateCursorItemReader
- HibernatePagingItemReader
- IbatisPagingItemReader
- ItemReaderAdapter
- JdbcCursorItemReader
- JdbcPagingItemReader
- JmsItemReader
- JpaPagingItemReader
- ListItemReader
- MongoItemReader
- Neo4jItemReader
- RepositoryItemReader
- StoredProcedureItemReader
- StaxEventItemReader
Мы видим, что Spring Batch уже предоставляет читателей для многих стандартов форматирования и поставщиков баз данных. Рекомендуется использовать абстракции, предоставляемые Spring Batch, в своих приложениях, а не создавать свои собственные.
Писатели
Писатели — это абстракции, отвечающие за запись данных в желаемую выходную базу данных или систему. То же самое, что мы объяснили для Readers, применимо к Writers: Spring Batch уже предоставляет классы и интерфейсы для работы со многими наиболее часто используемыми базами данных, их следует использовать. Вот список некоторых из этих предоставленных авторов:
- AbstractItemStreamItemWriter
- AmqpItemWriter
- CompositeItemWriter
- FlatFileItemWriter
- GemfireItemWriter
- HibernateItemWriter
- IbatisBatchItemWriter
- ItemWriterAdapter
- JdbcBatchItemWriter
- JmsItemWriter
- JpaItemWriter
- MimeMessageItemWriter
- MongoItemWriter
- Neo4jItemWriter
- StaxEventItemWriter
- RepositoryItemWriter
В этой статье мы покажем, как создавать собственные писатели и как использовать некоторые из перечисленных.
Процессоры предметов
Процессоры отвечают за изменение записей данных, преобразовывая их из входного формата в желаемый выходной. Основные интерфейсы, используемые для настройки обработчиков элементов: http://docs.spring.io/spring-batch/trunk/apidocs/org/springframework/batch/item/ItemProcessor.html .
В этой статье мы увидим, как создавать наши собственные процессоры элементов.
На следующем рисунке (из документации пакета Spring ) дается очень хорошее резюме всех этих концепций и того, как устроена базовая архитектура Spring Batch:
{kind=link}
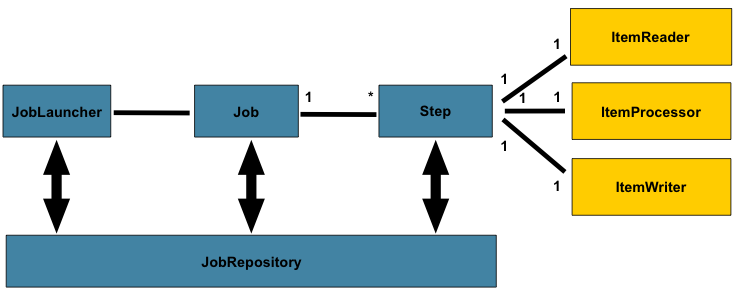
Эталонная модель Spring Batch
3. Используйте случаи
Хотя сложно классифицировать случаи использования, в которых пакетная обработка может применяться в реальном мире, я попытаюсь перечислить в этой главе наиболее важные из них:
- Приложения для преобразования. Это приложения, которые преобразуют входные записи в требуемую структуру или формат. Эти приложения могут использоваться на всех этапах пакетной обработки (чтение, обработка и запись).
- Фильтрация или проверка приложений: это программы с целью фильтрации действительных записей для дальнейшей обработки. Обычно проверка происходит на первых этапах пакетной обработки.
- Экстракторы базы данных: это приложения, которые считывают данные из базы данных или входных файлов и записывают требуемые отфильтрованные данные в выходной файл или в другую базу данных. Существуют также приложения, которые обновляют большие объемы данных в той же базе данных, откуда поступают входные записи. В качестве примера из реальной жизни мы можем представить систему, которая анализирует файлы журналов с различным поведением конечных пользователей и, используя эти данные, создает отчеты со статистикой о наиболее активных пользователях, наиболее активных периодах времени и т. Д.
- Отчетность: это приложения, которые считывают большие объемы данных из базы данных или входных файлов, обрабатывают эти данные и создают отформатированные документы на основе этих данных, которые подходят для печати или отправки через другие системы. Бухгалтерские и юридические банковские системы могут быть частью этой категории: в конце рабочего дня эти системы считывают информацию из баз данных, извлекают необходимые данные и записывают эти данные в юридические документы, которые могут быть отправлены в различные органы.
Spring Batch предоставляет механизмы для поддержки всех этих сценариев, с элементами и компонентами, перечисленными в предыдущей главе, программисты могут реализовывать пакетные приложения для преобразования данных, фильтрации записей, проверки, извлечения информации из баз данных или входных файлов и создания отчетов.
4. Контроль потока
Прежде чем начать говорить о конкретных заданиях и шагах, я собираюсь показать, как выглядит класс конфигурации Spring Batch. Следующий фрагмент содержит класс конфигурации со всеми компонентами, необходимыми для пакетной обработки с использованием Spring Batch. Он содержит читателей, писателей, процессоров, рабочие потоки, шаги и все другие необходимые компоненты.
В этом уроке мы покажем, как изменить этот класс конфигурации, чтобы использовать разные абстракции для наших разных целей. Класс ниже вставлен без комментариев и специального кода, для примера рабочего класса, пожалуйста, перейдите в раздел загрузки в этом руководстве, где вы можете скачать все источники:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
@Configuration@EnableBatchProcessingpublic class SpringBatchTutorialConfiguration {@Beanpublic ItemReader reader() { return new CustomItemReader();}@Beanpublic ItemProcessor processor() { return new CustomItemProcessor();}@Beanpublic ItemWriter writer(DataSource dataSource) { return new CustomItemItemWriter(dataSource);}@Beanpublic Job job1(JobBuilderFactory jobs, Step step1) { return jobs.get("job1").incrementer(new RunIdIncrementer()) .flow(step1).end().build();}@Beanpublic Step step1(StepBuilderFactory stepBuilderFactory, ItemReader reader, ItemWriter writer, ItemProcessor processor) { /* it handles bunches of 10 units */ return stepBuilderFactory.get("step1") . chunk(10).reader(reader) .processor(processor).writer(writer).build();}@Beanpublic JdbcTemplate jdbcTemplate(DataSource dataSource) { return new JdbcTemplate(dataSource);}@Beanpublic DataSource mysqlDataSource() throws SQLException {final DriverManagerDataSource dataSource = new DriverManagerDataSource(); dataSource.setDriverClassName("com.mysql.jdbc.Driver"); dataSource.setUrl("jdbc:mysql://localhost/spring_batch_annotations"); dataSource.setUsername("root"); dataSource.setPassword("root"); return dataSource;}... |
Чтобы запустить наш контекст Spring и выполнить настроенный пакет, показанный до того, как мы собираемся использовать Spring Boot. Вот пример программы, которая заботится о запуске нашего приложения и инициализации контекста Spring с правильной конфигурацией. Эта программа используется со всеми примерами, показанными в этом руководстве:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
@SpringBootApplicationpublic class SpringBatchTutorialMain implements CommandLineRunner { public static void main(String[] args) { SpringApplication.run(SpringBatchTutorialMain.class, args); } @Override public void run(String... strings) throws Exception { System.out.println("running..."); }} |
Я использую Maven для разрешения всех зависимостей и запуска приложения с помощью Spring boot. Вот используемый pom.xml :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <modelVersion>4.0.0</modelVersion> <groupId>com.danibuiza.javacodegeeks</groupId> <artifactId>Spring-Batch-Tutorial-Annotations</artifactId> <version>0.1.0</version> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.2.1.RELEASE</version> </parent> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-batch</artifactId> </dependency> <dependency> <groupId>org.hsqldb</groupId> <artifactId>hsqldb</artifactId> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build></project> |
И используемая цель:
mvn spring-boot: беги
Теперь пошагово рассмотрим файл конфигурации, показанный выше. Прежде всего, мы собираемся объяснить, как выполняются Jobs и Steps и каким правилам они следуют.
В приведенном выше примере приложения мы видим, как настроены задание и первый шаг. Здесь мы извлекаем связанный фрагмент кода:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
@Beanpublic Job job1(JobBuilderFactory jobs, Step step1) { return jobs.get("job1").incrementer(new RunIdIncrementer()) .flow(step1).end().build();}@Beanpublic Step step1(StepBuilderFactory stepBuilderFactory, ItemReader reader, ItemWriter writer, ItemProcessor processor) { /* it handles bunches of 10 units */ return stepBuilderFactory.get("step1") . chunk(10).reader(reader) .processor(processor).writer(writer).build();} |
Мы можем наблюдать, как Job с именем «job1» настраивается с помощью одного шага; в этом случае шаг называется «step1». Класс JobBuilderFactory создает компоновщик заданий и инициализирует репозиторий заданий. Метод flow() класса JobBuilder создает экземпляр класса JobFlowBuilder, используя показанный метод step1. Таким образом, весь контекст инициализируется и выполняется задание «job1».
Шаг обрабатывает (используя процессор) блоками по 10 единиц записи CustomPojo предоставленные читателем, и записывает их с использованием прошлого писателя. Все зависимости внедряются во время выполнения, Spring заботится об этом, так как класс, где все это происходит, помечается как класс конфигурации с использованием аннотации org.springframework.context.annotation.Configuration .
5. Пользовательские Писатели, Читатели и Процессоры
Как мы уже упоминали в этом руководстве, приложения Spring Batch в основном состоят из трех этапов: чтение данных, обработка данных и запись данных. Мы также объяснили, что для поддержки этих 3 операций Spring Batch предоставляет 3 абстракции в виде интерфейсов:
Программисты должны реализовать эти интерфейсы для чтения, обработки и записи данных в своих пакетных заданиях и шагах приложения. В этой главе мы собираемся объяснить, как создавать пользовательские реализации для этих абстракций.
Пользовательский Читатель
Абстракция, предоставляемая Spring Batch для чтения записей данных, представляет собой интерфейс ItemReader . Он имеет только один метод ( read() ) и должен выполняться несколько раз; это не должно быть потокобезопасным, этот факт очень важно знать приложениям, использующим эти методы.
Метод read() интерфейса ItemReader должен быть реализован. Этот метод не ожидает никаких входных параметров, он должен прочитать одну запись данных из нужной очереди и вернуть ее. Этот метод не должен выполнять какие-либо преобразования или обработку данных. Если возвращается ноль, дальнейшие данные не должны быть прочитаны или проанализированы.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
public class CustomItemReader implements ItemReader { private List pojos; private Iterator iterator; @Override public CustomPojo read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException { if (getIterator().hasNext()) { return getIterator().next(); } return null; }. . . |
Пользовательский читатель выше читает следующий элемент во внутреннем списке pojos , это возможно только в том случае, если итератор инициализируется или вводится при создании пользовательского читателя, если итератор создается каждый раз, когда вызывается метод read() , задание использование этого читателя никогда не закончится и не вызовет проблем.
Пользовательский процессор
Интерфейс, предоставляемый Spring Batch для обработки данных, ожидает один элемент ввода и создает один элемент вывода. Тип их обоих может быть разным, но не должен быть разным. Нулевое значение означает, что элемент больше не требуется для дальнейшей обработки в случае объединения.
Для реализации этого интерфейса необходимо только реализовать метод process() . Вот фиктивный пример:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
public class CustomItemProcessor implements ItemProcessor { @Override public CustomPojo process(final CustomPojo pojo) throws Exception { final String id = encode(pojo.getId()); final String desc = encode(pojo.getDescription()); final CustomPojo encodedPojo = new CustomPojo(id, desc); return encodedPojo; } private String encode(String word) { StringBuffer str = new StringBuffer(word); return str.reverse().toString(); }} |
Приведенный выше класс может оказаться бесполезным в любом сценарии реальной жизни, но показывает, как переопределить интерфейс ItemProcessor и выполнить любые действия (в данном случае реверсирование входных элементов pojo), необходимые в методе процесса.
Custom Writer
Для того, чтобы создать собственный писатель, программистам необходимо реализовать интерфейс ItemWriter . Этот интерфейс содержит только один метод write() который ожидает входной элемент и возвращает void . Метод write может выполнять любые необходимые действия: запись в базу данных, запись в файл csv, отправка электронного письма, создание отформатированного документа и т. Д. Реализация этого интерфейса отвечает за сброс данных и перевод структур в безопасное состояние. ,
Вот пример пользовательского модуля записи, в котором элемент ввода записывается в стандартной консоли:
|
1
2
3
4
5
6
7
8
|
public class CustomItemWriter implements ItemWriter { @Override public void write(List pojo) throws Exception { System.out.println("writing Pojo " + pojo); }} |
Также не очень полезно в реальной жизни, только в учебных целях.
Также важно упомянуть, что для почти всех реальных сценариев Spring Batch уже предоставляет конкретные абстракции, которые справляются с большинством проблем. Например, Spring Batch содержит классы для чтения данных из баз данных MySQL или для записи данных в базу данных HSQLDB, или для преобразования данных из XML в CSV с использованием JAXB; и много других. Кодекс чистый, полностью протестированный, стандартный и принятый в отрасли, поэтому я могу просто порекомендовать его использовать.
Эти классы также могут быть переопределены в наших приложениях для выполнения наших пожеланий без необходимости повторной реализации всей логики. Реализация предоставленных классов Spring также может быть полезна для целей тестирования, отладки, ведения журнала или отчетности. Поэтому, прежде чем снова и снова открывать колесо, стоит проверить документацию и руководства Spring Batch, потому что, вероятно, мы найдем лучший и более чистый способ решения наших конкретных проблем.
6. Пример плоского файла
Используя приведенный выше пример, мы собираемся изменить читателей и писателей, чтобы иметь возможность читать из файла CSV и записывать в плоский файл. Следующий фрагмент показывает, как мы должны настроить считыватель, чтобы обеспечить считыватель, который извлекает данные из плоского файла, в данном случае csv. Для этой цели Spring уже предоставляет класс FlatFileItemReader, которому необходимо свойство ресурса, из которого должны поступать данные, и средство отображения строк, чтобы иметь возможность анализировать данные, содержащиеся в этом ресурсе. Код довольно интуитивно понятен:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
@Beanpublic ItemReader reader() { if ("flat".equals(this.mode)) { // flat file item reader (using an csv extractor) FlatFileItemReader reader = new FlatFileItemReader(); //setting resource and line mapper reader.setResource(new ClassPathResource("input.csv")); reader.setLineMapper(new DefaultLineMapper() { { //default line mapper with a line tokenizer and a field mapper setLineTokenizer(new DelimitedLineTokenizer() { { setNames(new String[] { "id", "description" }); }}); setFieldSetMapper(new BeanWrapperFieldSetMapper() { { setTargetType(CustomPojo.class); }}); } }); return reader; } else { . . . |
В следующем фрагменте кода показаны изменения, которые необходимы в устройстве записи. В этом случае мы собираемся использовать модуль записи класса FlatFileItemWriter, которому нужен выходной файл для записи, и механизм извлечения. Экстрактор может быть настроен, как показано во фрагменте:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
@Beanpublic ItemWriter writer(DataSource dataSource) { ... else if ("flat".equals(this.mode)) { // FlatFileItemWriter writer FlatFileItemWriter writer = new FlatFileItemWriter (); writer.setResource(new ClassPathResource("output.csv")); BeanWrapperFieldExtractor fieldExtractor = new CustomFieldExtractor(); fieldExtractor.setNames(new String[] { "id", "description" }); DelimitedLineAggregator delLineAgg = new CustomDelimitedAggregator(); delLineAgg.setDelimiter(","); delLineAgg.setFieldExtractor(fieldExtractor); writer.setLineAggregator(delLineAgg); return writer; } else { . . . } |
7. Пример MySQL
В этой главе мы увидим, как изменить нашего писателя и наш источник данных, чтобы записывать обработанные записи в локальную БД MySQL.
Если мы хотим прочитать данные из БД MySQL, нам сначала нужно изменить конфигурацию компонента источника данных с необходимыми параметрами соединения:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
@Beanpublic DataSource dataSource() throws SQLException {. . .else if ("mysql".equals(this.mode)) { // mysql data source final DriverManagerDataSource dataSource = new DriverManagerDataSource(); dataSource.setDriverClassName("com.mysql.jdbc.Driver"); dataSource.setUrl("jdbc:mysql://localhost/spring_batch_annotations"); dataSource.setUsername("root"); dataSource.setPassword("root"); return dataSource;} else {. . . |
Вот как можно изменить средство записи с помощью оператора SQL и JdbcBatchItemWriter который инициализируется с помощью источника данных, показанного выше:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
@Beanpublic ItemWriter writer(DataSource dataSource) {... else if ("mysql".equals(this.mode)) { JdbcBatchItemWriter writer = new JdbcBatchItemWriter(); writer.setSql("INSERT INTO pojo (id, description) VALUES (:id, :description)"); writer.setDataSource(dataSource); writer.setItemSqlParameterSourceProvider( new BeanPropertyItemSqlParameterSourceProvider()); return writer;}.. . |
Здесь хорошо упомянуть, что есть проблема с необходимой библиотекой Jettison:
http://stackoverflow.com/questions/28627206/spring-batch-exception-cannot-construct-java-util-mapentry .
8. Пример в БД памяти (HSQLDB)
В качестве третьего примера мы собираемся показать, как создавать читателей и писателей для использования базы данных в памяти, это очень полезно для тестирования сценариев. По умолчанию, если ничего не указано, Spring Batch выбирает HSQLDB в качестве источника данных.
Используемый источник данных в этом случае тот же, что и для БД MySQL, но с другими параметрами (содержащими конфигурацию HSQLDB):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
@Beanpublic DataSource dataSource() throws SQLException { . . . } else { // hsqldb datasourcefinal DriverManagerDataSource dataSource = new DriverManagerDataSource(); dataSource.setDriverClassName("org.hsqldb.jdbcDriver"); dataSource.setUrl("jdbc:hsqldb:mem:test"); dataSource.setUsername("sa"); dataSource.setPassword(""); return dataSource; } } |
Автор не отличается (почти) от MySQL:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
@Beanpublic ItemWriter writer(DataSource dataSource) { if ("hsqldb".equals(this.mode)) { // hsqldb writer using JdbcBatchItemWriter (the difference is the // datasource) JdbcBatchItemWriter writer = new JdbcBatchItemWriter(); writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider()); writer.setSql("INSERT INTO pojo (id, description) VALUES (:id, :description)"); writer.setDataSource(dataSource); return writer; } else . . . |
Если мы хотим, чтобы Spring позаботился об инициализации БД, мы можем создать скрипт с именем schema-all.sql (для всех провайдеров, schema-hsqldb.sql для Hsqldb, schema-mysql.sql для MySQL, и т.д.) в ресурсном проекте нашего проекта:
|
1
2
3
4
5
6
|
DROP TABLE IF EXISTS POJO;CREATE TABLE POJO ( id VARCHAR(20), description VARCHAR(20)); |
Этот скрипт также предоставляется в разделе загрузки в конце учебника.
9. Модульное тестирование
В этой главе мы кратко рассмотрим, как тестировать пакетные приложения с использованием возможностей Spring Batch. В этой главе не объясняется, как тестировать Java-приложения вообще или Spring-приложения в частности. В нем рассматривается только то, как тестировать приложения Spring Batch от начала до конца, только тестирование заданий или этапов; именно поэтому модульное тестирование отдельных элементов, таких как процессоры элементов, читатели или устройства записи, исключено, поскольку оно не отличается от обычного модульного тестирования.
Проект Spring Batch Test Project содержит абстракции, которые облегчают модульное тестирование пакетных приложений.
Две аннотации являются основными при запуске модульных тестов (в данном случае с использованием Junit) в Spring:
- @RunWith (SpringJUnit4ClassRunner.class): аннотация Junit для выполнения всех методов, помеченных как тесты. С классом
SpringJunit4ClassRunnerпереданным в качестве параметра, мы указываем, что этот класс может использовать все возможности весеннего тестирования. - @ContextConfiguration (местоположения = {…}): Мы не будем использовать свойство «местоположения», потому что мы не используем файлы конфигурации xml, а непосредственно классы конфигурации.
Экземпляры класса http://docs.spring.io/spring-batch/trunk/apidocs/org/springframework/batch/test/JobLauncherTestUtils.html могут использоваться для запуска заданий и отдельных шагов внутри методов модульного теста (среди многих другие функции: его метод launchJob() выполняет Job, а его метод launchStep("name") выполняет шаг от конца к концу. В следующем примере вы можете увидеть, как использовать эти методы в реальных тестах jUnit:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
@RunWith(SpringJUnit4ClassRunner.class)@ContextConfiguration(classes=SpringBatchTutorialConfiguration.class, loader=AnnotationConfigContextLoader.class)public class SpringBatchUnitTest { @Autowired private JobLauncherTestUtils jobLauncherTestUtils; @Autowired JdbcTemplate jdbcTemplate; @Test public void testLaunchJob() throws Exception { // test a complete job JobExecution jobExecution = jobLauncherTestUtils.launchJob(); assertEquals(BatchStatus.COMPLETED, jobExecution.getStatus()); } @Test public void testLaunchStep() { // test a individual step JobExecution jobExecution = jobLauncherTestUtils.launchStep("step1"); assertEquals(BatchStatus.COMPLETED, jobExecution.getStatus()); }} |
Вы можете утверждать или проверять тесты, проверяя состояние выполнения задания для завершенных модульных тестов заданий или утверждая результаты записи для одношаговых тестов. В показанном примере мы не используем файл конфигурации xml, вместо этого мы используем уже упомянутый класс конфигурации. Чтобы указать модульный тест для загрузки этой конфигурации, используется аннотация ContextConfiguration со свойствами «classes» и «loader»:
|
1
2
|
@ContextConfiguration(classes=SpringBatchTutorialConfiguration.class, loader=AnnotationConfigContextLoader.class) |
Дополнительную информацию о модульном тестировании Spring Batch можно найти в следующем руководстве: http://docs.spring.io/spring-batch/trunk/reference/html/testing.html .
10. Обработка ошибок и повторная попытка работы
Spring предоставляет механизмы для повторного выполнения заданий, но, поскольку версия 2.2.0 больше не является частью среды Spring Batch, но включена в Spring Retry: http://docs.spring.io/spring-retry/docs/api/current/ , Очень хороший учебник можно найти здесь: http://docs.spring.io/spring-batch/trunk/reference/html/retry.html .
Политики повтора, обратные вызовы и механизм восстановления являются частью структуры.
11. Параллельная обработка
Spring Batch поддерживает параллельную обработку в двух возможных вариантах (один процесс и несколько процессов), которые мы можем разделить на следующие категории. В этой главе мы просто перечислим эти категории и кратко объясним, как Spring Batch предоставляет для них решения:
- Многопоточный шаг (однопроцессный): программисты могут реализовать свои считыватели и программы записи в поточно-ориентированном виде, поэтому можно использовать многопоточность и выполнять пошаговую обработку при различных угрозах. Spring batch предоставляет из коробки несколько реализаций
ItemWriterиItemReader. В их описании обычно указывается, являются ли они потокобезопасными или нет. Если эта информация не предоставлена или реализации четко заявляют, что они не являются поточно-ориентированными, программисты всегда могут синхронизировать вызов методаread(). Таким образом, несколько записей могут обрабатываться параллельно. - Параллельные шаги (одиночный процесс): если прикладные модули могут выполняться параллельно, поскольку их логика не разрушается, эти разные модули могут выполняться параллельно на разных этапах. Это отличается от сценария, описанного в последнем пункте, где каждый шаг выполнения обрабатывает разные записи параллельно; здесь разные шаги выполняются параллельно.
Spring Batch поддерживает этот сценарий сsplitэлементов. Вот пример конфигурации, которая может помочь лучше понять его:010203040506070809101112<jobid="havingLunchJob"><splitid="split1"task-executor="taskExecutor"next="cleanTableStep"><flow><stepid="step1"parent="s1"next="eatCakeStep"/><stepid=" eatCakeStep "parent="s2"/></flow><flow><stepid="drinkWineStep"parent="s3"/></flow></split><stepid=" cleanTableStep"parent="parentStep1"/>. . . - Удаленное разделение на этапы (один процесс): в этом режиме этапы разделяются в разных процессах, они сообщаются друг другу с использованием некоторой системы промежуточного программного обеспечения (например, JMX). В основном это главный компонент, работающий локально, и несколько удаленных процессов, называемых подчиненными. Главный компонент — это обычный Spring Batch Step, его автор знает, как отправлять куски элементов в виде сообщений, используя упомянутое ранее промежуточное программное обеспечение. Подчиненные устройства являются реализациями создателей элементов и процессоров элементов с возможностью обработки сообщений. Главный компонент не должен быть узким местом, стандартный способ реализации этого шаблона — оставить дорогие компоненты в процессорах и записывающих устройствах и легкие части в читателях.
- Разделение шага (один или несколько процессов): Spring Batch предлагает возможность разделить шаги и выполнять их удаленно. Удаленные экземпляры — Steps.
Это основные опции, которые Spring Batch предлагает программистам, чтобы они могли как-то параллельно обрабатывать свои пакетные приложения. Но параллелизм в целом и, в частности, параллелизм в пакетной обработке — это очень глубокая и сложная тема, которая выходит за рамки этого документа.
12. Повторение работы
Spring Batch предлагает возможность повторять задания и задачи программным и настраиваемым способом. Другими словами, наши пакетные приложения можно настроить так, чтобы они повторяли Задания или Шаги до тех пор, пока не будут выполнены определенные условия (или пока определенные условия еще не будут выполнены). Для этого доступно несколько абстракций:
- Операции повторения: интерфейс RepeatOperations является основой для всего механизма повторения в Spring Batch. Он содержит метод, который должен быть реализован при передаче обратного вызова. Этот обратный вызов выполняется в каждой итерации. Это выглядит следующим образом:
12345
publicinterfaceRepeatOperations {RepeatStatus iterate(RepeatCallback callback)throwsRepeatException;}Интерфейс RepeatCallback содержит функциональную логику, которая должна повторяться в Пакете:
12345publicinterfaceRepeatCallback {RepeatStatus doInIteration(RepeatContext context)throwsException;}RepeatStatusвозвращаемый в ихiterate()иdoInIteration()соответственно, должен иметь значениеRepeatStatus.CONTINUABLEв случае, если пакет должен продолжить итерацию, илиRepeatStatus.FINIHSEDв случае, если обработка пакета должна быть прекращена.Spring уже предоставляет некоторые базовые реализации для интерфейса
RepeatCallBack. - Шаблоны повторения: класс RepeatTemplate является очень полезной реализацией интерфейса
RepeatOperationsкоторый можно использовать в качестве отправной точки в наших пакетных приложениях. Он содержит основные функции и поведение по умолчанию для механизмов обработки ошибок и финализации. Приложения, которые не хотят использовать это поведение по умолчанию, должны реализовывать свои собственные политики завершения.
Вот пример того, как использовать шаблон повторения с фиксированной политикой завершения чанка и фиктивным методом итерации:010203040506070809101112RepeatTemplate template =newRepeatTemplate();template.setCompletionPolicy(newFixedChunkSizeCompletionPolicy(10));template.iterate(newRepeatCallback() {publicExitStatus doInIteration(RepeatContext context) {intx =10;x *=10;x /=10;returnExitStatus.CONTINUABLE;}});В этом случае пакет завершится после 10 итераций, поскольку метод iterate () всегда возвращает
CONTINUABLEи оставляет ответственность за завершение за политику завершения. - Статус повтора: Spring содержит перечисление с возможным статусом продолжения:
RepeatStatus .CONTINUABLE
RepeatStatus.FINISHEDчто обработка должна быть продолжена или завершена (может быть успешной или неудачной). http://docs.spring.io/spring-batch/trunk/apidocs/org/springframework/batch/repeat/RepeatStatus.html - Контекст повтора: можно сохранить временные данные в контексте повтора, этот контекст передается как параметр методу повторного обратного вызова
doInIteration(). Spring Batch предоставляет абстракцию RepeatContext для этой цели.
Послеiterate()методаiterate()контекст больше не существует. У повторяющегося контекста есть родительский контекст в случае, если итерации вложены, в этих случаях можно использовать родительский контекст для хранения информации, которая может быть разделена между различными итерациями, такими как счетчики или переменные решения. - Политика повторения: механизм завершения шаблона повторения определяется CompletionPolicy . Эта политика также отвечает за создание
RepeatContextи передачу егоRepeatContextвызову на каждой итерации. После завершения итерации шаблон вызывает политику завершения и обновляет свое состояние, которое будет сохранено в контексте повторения. После этого шаблон просит политику проверить, завершена ли обработка. Источник содержит несколько реализаций для этого интерфейса, одна из самых простых — SimpleCompletionPolicy ; который предлагает возможность выполнить Пакет только фиксированное количество итераций.
13. Пакетные приложения JSR 352 для платформы Java
Начиная с Java 7, пакетная обработка включена в платформу Java. JSR 352 ( пакетные приложения для платформы Java ) определяет модель для пакетных приложений и среду выполнения для планирования и выполнения заданий. На момент написания этого руководства реализация Spring Batch (3.0) полностью реализовала спецификацию JSR-352.
Модель предметной области и используемый словарь очень похожи на ту, что используется в Spring Batch.
JSR 352: пакетные приложения для платформы Java: ItemReaders , Steps , Chunks , Items , ItemReaders , ItemWriters , ItemProcessors и т. Д. Также присутствуют в модели Java-платформы JSR 352. Различия незначительны как для фреймворков, так и для файлов конфигурации.
Это хорошо как для программистов, так и для индустрии; поскольку отрасль извлекает выгоду из того факта, что стандарт был создан в платформе Java, используя в качестве основы очень хорошую библиотеку, такую как Spring Batch, которая широко используется и хорошо протестирована. Программисты выигрывают, потому что, если Spring Batch прекращается или не может использоваться по каким-либо причинам в их приложениях (совместимость, политики компании, ограничения по размеру…), они могут выбрать стандартную реализацию Java для пакетной обработки без особых изменений в своих системах.
Для получения дополнительной информации о том, как Spring Batch был адаптирован к JSR 352, перейдите по ссылке http://docs.spring.io/spring-batch/reference/html/jsr-352.html .
14. Резюме
Ну это все.Надеюсь, вам понравилось, и теперь вы можете настраивать и реализовывать пакетные приложения с помощью Spring Batch. Я собираюсь суммировать здесь наиболее важные моменты, объясненные в этой статье:
- Spring Batch — это среда пакетной обработки, построенная на основе Spring Framework.
- В основном (упрощенно!) Он состоит из <code <Jobs, содержащих
Steps, гдеReaders,ProcessorsиWritersи сконфигурированных и связанных для выполнения желаемых действий. - Spring Batch содержит механизм, который позволяет программистам работать с основными поставщиками, такими как MySQL, Mongo DB, и форматами, такими как SQL, CSV или XML, из коробки.
- Spring Batch содержит функции для обработки ошибок, повторения
Jobsи повторныхStepsпопытокJobsиSteps. - Это также предлагает возможности для параллельной обработки.
- Он содержит классы и интерфейсы для модульного тестирования пакетных приложений.
В этом уроке я не использовал XML-файл (за исключением некоторых примеров) для настройки контекста Spring, все было сделано с помощью аннотаций. Я сделал это таким образом для ясности, но я не рекомендую делать это в реальных приложениях, так как файлы конфигурации xml могут быть полезны в определенных сценариях. Как я уже сказал, это был учебник о Spring Batch, а не о Spring в целом.
15. Ресурсы
Следующие ссылки содержат много информации и теоретических примеров, где вы можете изучить все функции модуля Spring Batch:
- http://docs.spring.io/spring-batch/reference/html/index.html
- https://jcp.org/en/jsr/detail?id=352
- https://spring.io/guides/gs/batch-processing/
- https://kb.iu.edu/d/afrx
16. Загрузите исходный код Spring Batch Tutorial.
Вы можете скачать полный исходный код этого учебника Spring Batch здесь: spring_batch_tutorial .