На этом уроке Spring Apache Kafka мы узнаем, как начать работу с Apache Kafka в проекте Spring Boot, и начнем создавать и потреблять сообщения по выбранной нами теме. Помимо простого проекта, мы углубимся в терминологию Кафки и как работает концепция разделения в Кафке. Давайте начнем.
1. Введение
С появлением микросервисов необходимость асинхронной связи между задействованными сервисами стала основным требованием. Собственно, именно так Apache Kafka появился в LinkedIn . Основными требованиями новой асинхронной системы связи были постоянство сообщений и высокая пропускная способность . Как только LinkedIn смог создать проект в лице Kafka, они пожертвовали проект фонду Apache Software, где он стал называться Apache Kafka .
Содержание
- 1. Введение
- 2. Что такое Apache Kafka?
- 3. Терминология Apache Kafka
- 4. Установка Кафки и создание темы
- 5. Создание проекта Spring Boot с Maven
- 6. Добавление Maven-зависимостей
- 7. Структура проекта
- 8. Добавление конфигурации
- 9. Определение конфигурации производителя
- 10. Определение конфигурации потребителя
- 11. Определение класса Spring Boot
- 12. Запуск проекта
- 13. Кафка разделов
- 14. Вывод
- 15. Скачать исходный код
2. Что такое Apache Kafka?
Kafka была разработана в LinkedIn в 2010 году и была передана в дар Apache Software Foundation, где к 2012 году стала одним из лучших проектов. Apache Kafka имеет три основных компонента в своей экосистеме:
- Издатель-подписчик : этот компонент Kafka отвечает за отправку и использование данных через узлы Kafka (подробнее об узлах в следующих разделах) и пользовательских приложениях, которые могут масштабироваться с очень высокой пропускной способностью.
- Kafka Streams : с потоковым API Kafka можно обрабатывать входящие данные в kafka практически в реальном времени
- API Connect : с помощью API Connect можно интегрировать множество внешних источников данных и приемников данных с Kafka.
Для определения высокого уровня мы можем предоставить простое определение для Apache Kafka:
Apache Kafka — это распределенный, отказоустойчивый, горизонтально масштабируемый журнал фиксации.
Давайте уточним, что мы только что сказали:
- Распределенный : Kafka — это распределенная система, в которой все сообщения реплицируются на различные узлы, поэтому каждый сервер может отвечать клиенту за содержащиеся в нем сообщения. Кроме того, даже если один узел выходит из строя, другие узлы могут быстро вступить во владение без простоя
- Отказоустойчивость : поскольку у Kafka нет единой точки отказа , даже если один из узлов выйдет из строя, конечный пользователь вряд ли заметит это, так как другие части несут ответственность за сообщения, потерянные из-за неисправного узла
- Горизонтально масштабируемый : Kafka позволяет нам добавлять больше компьютеров в кластер с нулевым временем простоя. Это означает, что если мы начнем сталкиваться с задержкой в сообщениях из-за небольшого количества серверов в кластере, мы сможем быстро добавить больше серверов и поддерживать производительность системы
- Журнал фиксации. Журнал фиксации относится к структуре, аналогичной связанному списку. Порядок вставки сообщений сохраняется, и данные не могут быть удалены из этого журнала, пока не будет достигнуто пороговое время
Еще больше понятий об Apache Kafka станет понятным в следующих разделах, где мы поговорим об основных терминологиях, используемых в уроке Apache Kafka.
3. Терминология Apache Kafka
Прежде чем мы сможем продвинуться с концепциями Kafka и примером проекта, мы должны понять основные термины, связанные с Apache Kafka. Вот некоторые из них:
- Производитель : Этот компонент публикует сообщения в кластер Kafka.
- Потребитель : этот компонент потребляет сообщения из кластера Kafka.
- Сообщение : это данные, которые производитель отправляет в кластер.
- Соединение . Производителю необходимо установить соединение TCP для публикации сообщения. То же самое нужно в потребительском приложении, чтобы использовать данные из кластера Kafka.
- Тема : Тема — это логическая группа похожих сообщений. Приложение-производитель может публиковать сообщения в определенной теме и использовать из определенной темы
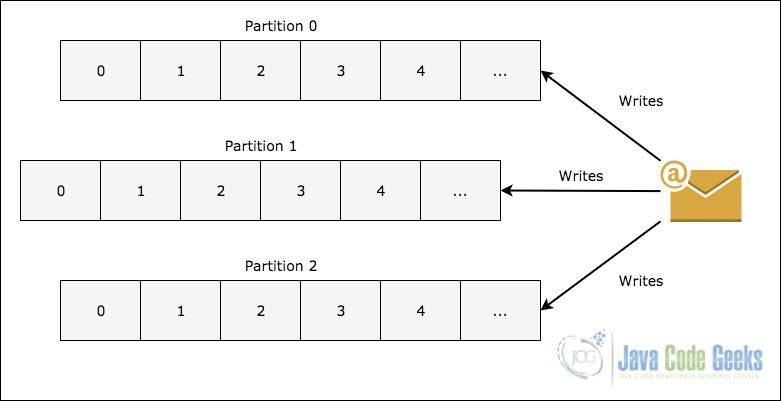
- Раздел темы : чтобы масштабировать память темы, так как она может содержать много сообщений, одна тема делится на разделы, и каждый раздел может жить на любом узле кластера, на следующем рисунке показано, как сообщение записывается в несколько разделов:

Разделение темы в Кафке
- Реплики : Как мы видели на рисунке выше о разделении темы, каждое сообщение реплицируется на различные узлы, чтобы поддерживать порядок и предотвращать потерю данных, когда один из узлов умирает
- Группы потребителей : несколько потребителей, которые заинтересованы в одной теме, могут быть сохранены в группе, называемой группами потребителей.
- Смещение : Кафка не хранит информацию о том, какой потребитель будет читать какие данные. Каждый потребитель хранит значение смещения о том, что было последним сообщением, которое он прочитал. Это означает, что разные потребители могут читать разные сообщения одновременно
- Узел : Узел — это всего лишь один сервер в кластере. Мы можем добавить практически любое количество узлов в кластере по своему усмотрению
- Кластер : группа узлов называется кластером.
4. Установка Кафки и создание темы
Чтобы загрузить и установить Kafka, мы можем обратиться к Официальному руководству Kafka, представленному здесь . Когда сервер Kafka запущен и работает, мы можем создать новую тему с именем javacodegeeks с помощью следующей команды:
Создание темы
|
1
2
3
4
|
bin/kafka-topics --create \ --zookeeper localhost:2181 \ --replication-factor 1 --partitions 1 \ --topic javacodegeeks |
Мы увидим следующий вывод после выполнения этой команды:
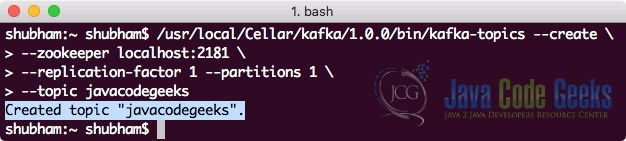
Кафка создать тему
5. Создание проекта Spring Boot с Maven
Мы будем использовать один из многих архетипов Maven для создания примера проекта для нашего примера. Чтобы создать проект, выполните следующую команду в каталоге, который вы будете использовать в качестве рабочей области:
Создание проекта
|
1
|
mvn archetype:generate -DgroupId=com.javacodegeeks.example -DartifactId=JCG-BootKafka-Example -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false |
Если вы запускаете maven в первый раз, выполнение команды генерации займет несколько секунд, поскольку maven должен загрузить все необходимые плагины и артефакты, чтобы выполнить задачу генерации. Как только мы запустим этот проект, мы увидим следующий результат и проект будет создан:
Создание проекта Kafka
6. Добавление Maven-зависимостей
Создав проект, не стесняйтесь открывать его в своей любимой среде IDE. Следующим шагом является добавление соответствующих зависимостей Maven в проект. Мы будем работать со следующими зависимостями в нашем проекте:
-
spring-boot-starter-web: эта зависимость помечает этот проект как веб-проект и добавляет зависимости для создания контроллеров и создания веб-связанных классов. -
spring-kafka: это зависимость, которая переносит все связанные с Kafka зависимости в путь к классам проекта -
spring-boot-starter-test: эта зависимость собирает все связанные с тестами JAR-файлы в проекте, такие как JUnit и Mockito .
Вот файл pom.xml с добавленными соответствующими зависимостями:
pom.xml
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
<groupId>com.javacodegeeks.example</groupId><artifactId>JCG-BootKafka-Example</artifactId><packaging>jar</packaging><version>1.0-SNAPSHOT</version><name>JCG-BootKafka-Example</name><parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.5.10.RELEASE</version> <relativePath/> <!-- lookup parent from repository --></parent><properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <java.version>1.8</java.version></properties><dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>1.1.3.RELEASE</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency></dependencies><build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins></build> |
Найти последние зависимости Maven от Maven Central .
Наконец, чтобы понять все JAR-файлы, которые добавляются в проект при добавлении этой зависимости, мы можем запустить простую команду Maven, которая позволяет нам видеть полное дерево зависимостей для проекта, когда мы добавляем в него некоторые зависимости. Вот команда, которую мы можем использовать:
Проверьте дерево зависимостей
|
1
|
mvn dependency:tree |
Когда мы запустим эту команду, она покажет нам следующее дерево зависимостей:
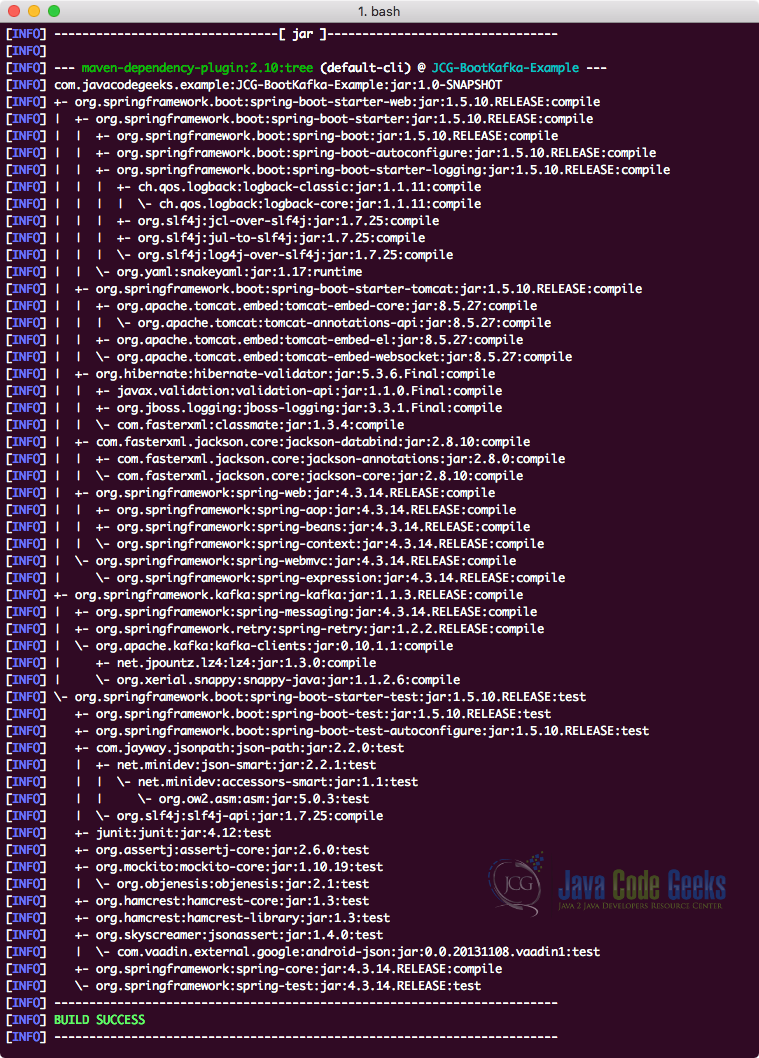
Проверка зависимости
Заметили что-то? Так много зависимостей было добавлено, просто добавив четыре зависимости в проект. Spring Boot сама собирает все связанные зависимости и ничего не оставляет для нас в этом вопросе. Самым большим преимуществом является то, что все эти зависимости гарантированно совместимы друг с другом .
7. Структура проекта
Прежде чем мы продолжим работу и начнем работать над кодом для проекта, давайте представим здесь структуру проекта, которая будет у нас после завершения добавления всего кода в проект:
Структура проекта
Мы разделили проект на несколько пакетов, чтобы следовать принципу разделения интересов, а код оставался модульным.
8. Добавление конфигурации
Прежде чем мы сможем начать писать код для нашего проекта, нам нужно предоставить некоторые свойства в файле application.properties нашего проекта Spring Boot:
application.properties
|
1
2
3
4
5
6
7
|
#Kafka Topicmessage.topic.name=javacodegeeksspring.kafka.bootstrap-servers=localhost:9092#Unique String which identifies which consumer group this consumer belongs tospring.kafka.consumer.group-id=jcg-group |
Это некоторые свойства, которые мы будем использовать в нашем проекте в качестве идентификатора темы и группы для сообщения, которое мы будем публиковать и потреблять. Кроме того, 9092 является портом по умолчанию для Apache Kafka. Обратите внимание, что мы могли бы также определить несколько тем с разными именами для ключей.
9. Определение конфигурации производителя
Мы начнем с определения конфигурации для производителя. Единственное свойство, которое нам нужно обязательно определить для производителя Kafka, — это адрес сервера Kafka с его портом.
KafkaProducerConfig.java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
package com.javacodegeeks.example.config;import org.apache.kafka.clients.producer.ProducerConfig;import org.apache.kafka.common.serialization.StringSerializer;import org.springframework.beans.factory.annotation.Value;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.kafka.core.DefaultKafkaProducerFactory;import org.springframework.kafka.core.KafkaTemplate;import org.springframework.kafka.core.ProducerFactory;import java.util.HashMap;import java.util.Map;@Configurationpublic class KafkaProducerConfig { @Value("${spring.kafka.bootstrap-servers}") private String bootstrapAddress; @Bean public ProducerFactory<String, String> producerFactory() { Map<String, Object> configProps = new HashMap<>(); configProps.put( ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress); configProps.put( ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); configProps.put( ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); return new DefaultKafkaProducerFactory<>(configProps); } @Bean public KafkaTemplate<String, String> kafkaTemplate() { return new KafkaTemplate<>(producerFactory()); }} |
Хотя приведенное выше определение класса довольно просто, у нас все же есть некоторые моменты, которые нам нужно понять:
-
@Configuration: этот класс определен как класс конфигурации, что означает, что Spring Boot автоматически подхватит этот класс, и все bean-компоненты, определенные внутри этого класса, будут автоматически управляться контейнером Spring. - Мы определили bean-компонент для
ProducerFactoryкоторый принимает входные данные как различные свойства, такие как адрес сервера Kafka и другие свойства сериализации, которые помогают кодировать и декодировать сообщение, отправляемое через bean-компонент Kafka. - Наконец, мы определили bean-компонент для
KafkaTemplateкоторый является фактическим объектом API, который будет использоваться для публикации сообщения по теме Kafka.
10. Определение конфигурации потребителя
Поскольку мы создаем производителя и потребителя Kafka в одном приложении для демонстрационных целей, мы также определим класс конфигурации потребителей, который будет просто содержать основные свойства для потребителя Kafka. Этот класс может быть помещен в любой проект, который не является производителем и потребителем Kafka, без каких-либо изменений. Давайте посмотрим на определение конфигурации:
KafkaConsumerConfig.java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
package com.javacodegeeks.example.config;import org.apache.kafka.clients.consumer.ConsumerConfig;import org.apache.kafka.common.serialization.StringDeserializer;import org.springframework.beans.factory.annotation.Value;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.kafka.annotation.EnableKafka;import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;import org.springframework.kafka.core.ConsumerFactory;import org.springframework.kafka.core.DefaultKafkaConsumerFactory;import java.util.HashMap;import java.util.Map;@EnableKafka@Configurationpublic class KafkaConsumerConfig { @Value("${spring.kafka.bootstrap-servers}") private String bootstrapAddress; @Value("${spring.kafka.consumer.group-id}") private String groupId; @Bean public ConsumerFactory<String, String> consumerFactory() { Map<String, Object> props = new HashMap<>(); props.put( ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress); props.put( ConsumerConfig.GROUP_ID_CONFIG, groupId); props.put( ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put( ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); return new DefaultKafkaConsumerFactory<>(props); } @Bean public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); return factory; }} |
Предоставленная нами конфигурация очень похожа на конфигурацию производителя. Единственное отличие, которое следует отметить здесь:
- Мы определили объектный компонент класса
ConsumerFactoryкоторый учитывает адрес сервера Kafka и идентификатор группы потребителей, к которому относится это приложение-потребитель Kafka. Мы предоставили потребителю уникальную строку, так как приемлема только уникальная строка - Наконец, мы определили
ConcurrentKafkaListenerContainerFactoryкоторый гарантирует, что это потребительское приложение может одновременно использовать сообщения Kafka и может обеспечить согласованную пропускную способность, даже если количество опубликованных сообщений велико.
11. Определение класса Spring Boot
На последнем этапе мы создадим класс Spring Boot, с помощью которого мы сможем опубликовать сообщение, и использовать его по той же теме. Вот определение класса для основного класса:
KafkaApp.java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
package com.javacodegeeks.example;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Value;import org.springframework.boot.CommandLineRunner;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import org.springframework.kafka.annotation.KafkaListener;import org.springframework.kafka.core.KafkaTemplate;@SpringBootApplicationpublic class KafkaApp implements CommandLineRunner { private static final Logger LOG = LoggerFactory.getLogger("KafkaApp"); @Value("${message.topic.name}") private String topicName; private final KafkaTemplate<String, String> kafkaTemplate; @Autowired public KafkaApp(KafkaTemplate<String, String> kafkaTemplate) { this.kafkaTemplate = kafkaTemplate; } public static void main(String[] args) { SpringApplication.run(KafkaApp.class, args); } @Override public void run(String... strings) { kafkaTemplate.send(topicName, "Hello Geek!"); LOG.info("Published message to topic: {}.", topicName); } @KafkaListener(topics = "javacodegeeks", group = "jcg-group") public void listen(String message) { LOG.info("Received message in JCG group: {}", message); }} |
Мы использовали интерфейс CommandLineRunner чтобы заставить этот класс выполнять код, с помощью которого мы можем тестировать код класса производителя и конфигурации, который мы написали. В этом классе мы публикуем сообщение в указанной теме и прослушиваем его в методе слушателя, который мы определили в том же классе.
В следующем разделе мы запустим наш проект с помощью простой команды Maven.
12. Запуск проекта
Теперь, когда определение основного класса сделано, мы можем запустить наш проект. С приложением maven легко запустить приложение, просто используйте следующую команду:
Запуск проекта
|
1
|
mvn spring-boot:run |
Как только мы выполним указанную выше команду, мы увидим, что сообщение было опубликовано в указанной теме, и это же приложение также использовало сообщение:
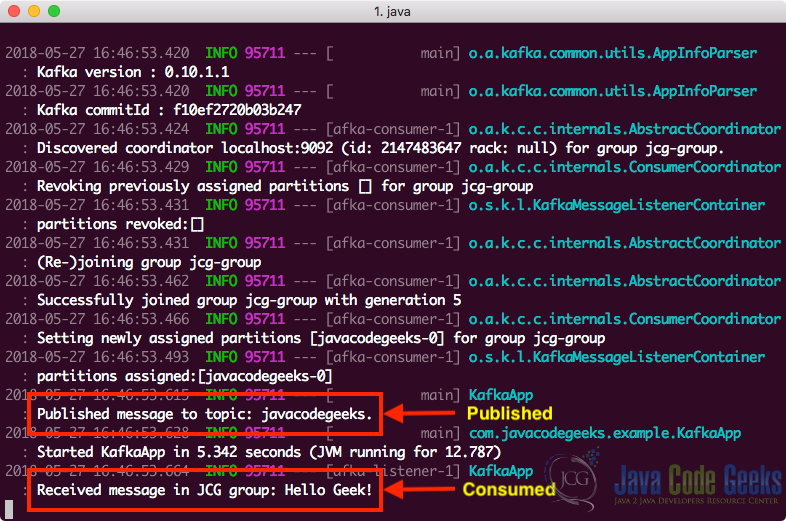
Запуск проекта Spring Boot Kafka
13. Кафка разделов
В качестве окончательной концепции мы коснемся того, как разделение разделов выполняется в Apache Kafka. Мы начнем с очень простого иллюстративного изображения, которое показывает, как существуют лидеры в разделе Темы:
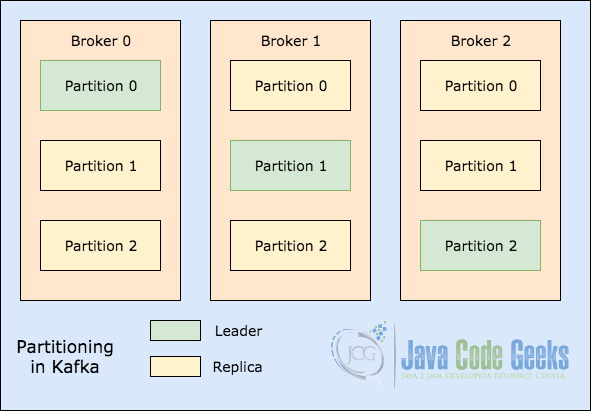
Разделение темы
Когда происходит запись для темы в позиции, для которой раздел 0 в посреднике 0 является лидером, эти данные реплицируются по узлам, так что сообщение остается безопасным. Это означает, что сообщение будет реплицировано через Раздел 0 для всех трех посредников, показанных на рисунке выше.
Процесс репликации в Kafka выполняется параллельно, когда узел открывает несколько потоков. Поскольку потоки открываются для максимально возможного параллелизма, в Kafka достигается очень высокая пропускная способность. После того, как сообщение реплицируется определенное количество раз, запись вызывается для принятия, но репликация сообщения продолжается до тех пор, пока не будет достигнут коэффициент репликации для данных.
14. Вывод
В этом уроке мы рассмотрели, как легко и быстро создать приложение Spring Boot с интегрированным в него Apache Kafka. Apache Kafka превратился из простого проекта Apache в проект промышленного уровня, который может обрабатывать миллионы запросов каждую секунду при развертывании с правильным числом узлов в своем кластере, назначении надлежащей памяти и правильном управлении через Zookeeper. Apache Kafka — один из самых многообещающих навыков работы с программным инженером, который может охватывать множество случаев использования, таких как отслеживание веб-сайтов, приложения для обмена сообщениями в реальном времени и многое другое.
Масштаб, в котором Apache Kafka может управлять сообщениями по своим темам и разделам, действительно огромен, и маршрут архитектуры, который требуется, чтобы стать настолько масштабируемым, вдохновляет многие другие проекты. Обещаемая им масштабируемость и скорость обработки в реальном времени гарантируют, что она решит многие ваши проблемы в проектах, которые необходимо масштабировать очень сильно.
15. Скачать исходный код
Это был пример интеграции Apache Kafka со Spring Framework.