Около года назад Ян указал мне на набор данных по преступности в Чикаго, который показался мне подходящим для Neo4j, и после долгих проволочек я наконец-то нашел способ импортировать его.
Набор данных охватывает преступления, совершенные с 2001 года по настоящее время. Он содержит около 4 миллионов преступлений и метаданных о таких преступлениях, как местонахождение, тип преступления и год, чтобы назвать несколько.
Содержимое файла имеет следующую структуру:
|
01
02
03
04
05
06
07
08
09
10
11
|
$ head -n 10 ~/Downloads/Crimes_-_2001_to_present.csvID,Case Number,Date,Block,IUCR,Primary Type,Description,Location Description,Arrest,Domestic,Beat,District,Ward,Community Area,FBI Code,X Coordinate,Y Coordinate,Year,Updated On,Latitude,Longitude,Location9464711,HX114160,01/14/2014 05:00:00 AM,028XX E 80TH ST,0560,ASSAULT,SIMPLE,APARTMENT,false,true,0422,004,7,46,08A,1196652,1852516,2014,01/20/2014 12:40:05 AM,41.75017626412204,-87.55494559131228,"(41.75017626412204, -87.55494559131228)"9460704,HX113741,01/14/2014 04:55:00 AM,091XX S JEFFERY AVE,031A,ROBBERY,ARMED: HANDGUN,SIDEWALK,false,false,0413,004,8,48,03,1191060,1844959,2014,01/18/2014 12:39:56 AM,41.729576153145636,-87.57568059471686,"(41.729576153145636, -87.57568059471686)"9460339,HX113740,01/14/2014 04:44:00 AM,040XX W MAYPOLE AVE,1310,CRIMINAL DAMAGE,TO PROPERTY,RESIDENCE,false,true,1114,011,28,26,14,1149075,1901099,2014,01/16/2014 12:40:00 AM,41.884543798701515,-87.72803579358926,"(41.884543798701515, -87.72803579358926)"9461467,HX114463,01/14/2014 04:43:00 AM,059XX S CICERO AVE,0820,THEFT,$500 AND UNDER,PARKING LOT/GARAGE(NON.RESID.),false,false,0813,008,13,64,06,1145661,1865031,2014,01/16/2014 12:40:00 AM,41.785633535413176,-87.74148516669783,"(41.785633535413176, -87.74148516669783)"9460355,HX113738,01/14/2014 04:21:00 AM,070XX S PEORIA ST,0820,THEFT,$500 AND UNDER,STREET,true,false,0733,007,17,68,06,1171480,1858195,2014,01/16/2014 12:40:00 AM,41.766348042591375,-87.64702037047671,"(41.766348042591375, -87.64702037047671)"9461140,HX113909,01/14/2014 03:17:00 AM,016XX W HUBBARD ST,0610,BURGLARY,FORCIBLE ENTRY,COMMERCIAL / BUSINESS OFFICE,false,false,1215,012,27,24,05,1165029,1903111,2014,01/16/2014 12:40:00 AM,41.889741146006095,-87.66939334853973,"(41.889741146006095, -87.66939334853973)"9460361,HX113731,01/14/2014 03:12:00 AM,022XX S WENTWORTH AVE,0820,THEFT,$500 AND UNDER,CTA TRAIN,false,false,0914,009,25,34,06,1175363,1889525,2014,01/20/2014 12:40:05 AM,41.85223460427207,-87.63185047834335,"(41.85223460427207, -87.63185047834335)"9461691,HX114506,01/14/2014 03:00:00 AM,087XX S COLFAX AVE,0650,BURGLARY,HOME INVASION,RESIDENCE,false,false,0423,004,7,46,05,1195052,1847362,2014,01/17/2014 12:40:17 AM,41.73607283858007,-87.56097809501115,"(41.73607283858007, -87.56097809501115)"9461792,HX114824,01/14/2014 03:00:00 AM,012XX S CALIFORNIA BLVD,0810,THEFT,OVER $500,STREET,false,false,1023,010,28,29,06,1157929,1894034,2014,01/17/2014 12:40:17 AM,41.86498077118534,-87.69571529596696,"(41.86498077118534, -87.69571529596696)" |
Поскольку я хотел импортировать это в Neo4j, мне нужно было выполнить некоторую обработку данных, поскольку инструмент neo4j-import ожидает получить файлы CSV, содержащие узлы и связи, которые мы хотим создать.
Я смотрел на Spark в конце прошлого года, и предварительная обработка большого исходного файла в меньшие CSV-файлы, содержащие узлы и взаимосвязи, казалась подходящей.
Поэтому мне нужно было создать работу Spark, чтобы сделать это. Затем мы передадим это задание исполнителю Spark, работающему локально, и он выплюнет файлы CSV.
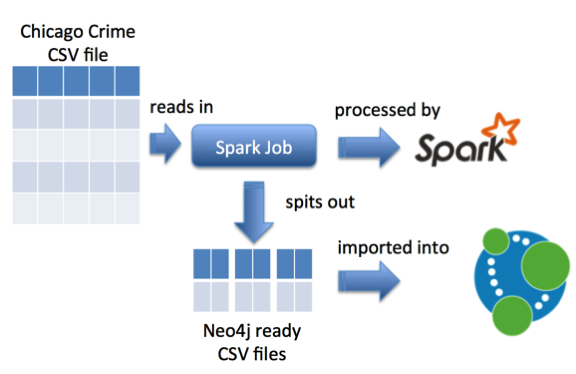
Мы начнем с создания объекта Scala с методом main, который будет содержать наш код обработки. Внутри этого основного метода мы создадим контекст Spark:
|
1
2
3
4
5
6
7
8
|
import org.apache.spark.{SparkConf, SparkContext} object GenerateCSVFiles { def main(args: Array[String]) { val conf = new SparkConf().setAppName("Chicago Crime Dataset") val sc = new SparkContext(conf) }} |
Достаточно просто. Далее мы будем читать в файле CSV. Я нашел самый простой способ сослаться на это с помощью переменной среды, но, возможно, есть более идиоматический способ:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
import java.io.Fileimport org.apache.spark.{SparkConf, SparkContext} object GenerateCSVFiles { def main(args: Array[String]) { var crimeFile = System.getenv("CSV_FILE") if(crimeFile == null || !new File(crimeFile).exists()) { throw new RuntimeException("Cannot find CSV file [" + crimeFile + "]") } println("Using %s".format(crimeFile)) val conf = new SparkConf().setAppName("Chicago Crime Dataset") val sc = new SparkContext(conf) val crimeData = sc.textFile(crimeFile).cache()} |
Тип crimeData — это RDD [String] — способ Spark для представления (лениво оцененных) строк файла CSV. Это также включает заголовок файла, поэтому давайте напишем функцию, чтобы избавиться от этого, так как мы будем генерировать наши собственные заголовки для разных файлов:
|
01
02
03
04
05
06
07
08
09
10
11
|
import org.apache.spark.rdd.RDD def dropHeader(data: RDD[String]): RDD[String] = { data.mapPartitionsWithIndex((idx, lines) => { if (idx == 0) { lines.drop(1) } lines })} |
Теперь мы готовы начать генерировать наши новые файлы CSV, поэтому мы напишем функцию, которая анализирует каждую строку и извлекает соответствующие столбцы. Я использую Open CSV для этого:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
import au.com.bytecode.opencsv.CSVParser def generateFile(file: String, withoutHeader: RDD[String], fn: Array[String] => Array[String], header: String , distinct:Boolean = true, separator: String = ",") = { FileUtil.fullyDelete(new File(file)) val tmpFile = "/tmp/" + System.currentTimeMillis() + "-" + file val rows: RDD[String] = withoutHeader.mapPartitions(lines => { val parser = new CSVParser(',') lines.map(line => { val columns = parser.parseLine(line) fn(columns).mkString(separator) }) }) if (distinct) rows.distinct() saveAsTextFile tmpFile else rows.saveAsTextFile(tmpFile)} |
Затем мы вызываем эту функцию так:
|
1
|
generateFile("/tmp/crimes.csv", withoutHeader, columns => Array(columns(0),"Crime", columns(2), columns(6)), "id:ID(Crime),:LABEL,date,description", false) |
Вывод в ‘tmpFile’ на самом деле представляет собой 32 ‘файла детали’, но я хотел иметь возможность объединить их вместе в отдельные файлы CSV, с которыми было бы легче работать.
Полная работа выглядит так:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
import java.io.File import au.com.bytecode.opencsv.CSVParserimport org.apache.hadoop.conf.Configurationimport org.apache.hadoop.fs._import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext} object GenerateCSVFiles { def merge(srcPath: String, dstPath: String, header: String): Unit = { val hadoopConfig = new Configuration() val hdfs = FileSystem.get(hadoopConfig) MyFileUtil.copyMergeWithHeader(hdfs, new Path(srcPath), hdfs, new Path(dstPath), false, hadoopConfig, header) } def main(args: Array[String]) { var crimeFile = System.getenv("CSV_FILE") if(crimeFile == null || !new File(crimeFile).exists()) { throw new RuntimeException("Cannot find CSV file [" + crimeFile + "]") } println("Using %s".format(crimeFile)) val conf = new SparkConf().setAppName("Chicago Crime Dataset") val sc = new SparkContext(conf) val crimeData = sc.textFile(crimeFile).cache() val withoutHeader: RDD[String] = dropHeader(crimeData) generateFile("/tmp/primaryTypes.csv", withoutHeader, columns => Array(columns(5).trim(), "CrimeType"), "crimeType:ID(CrimeType),:LABEL") generateFile("/tmp/beats.csv", withoutHeader, columns => Array(columns(10), "Beat"), "id:ID(Beat),:LABEL") generateFile("/tmp/crimes.csv", withoutHeader, columns => Array(columns(0),"Crime", columns(2), columns(6)), "id:ID(Crime),:LABEL,date,description", false) generateFile("/tmp/crimesPrimaryTypes.csv", withoutHeader, columns => Array(columns(0),columns(5).trim(), "CRIME_TYPE"), ":START_ID(Crime),:END_ID(CrimeType),:TYPE") generateFile("/tmp/crimesBeats.csv", withoutHeader, columns => Array(columns(0),columns(10), "ON_BEAT"), ":START_ID(Crime),:END_ID(Beat),:TYPE") } def generateFile(file: String, withoutHeader: RDD[String], fn: Array[String] => Array[String], header: String , distinct:Boolean = true, separator: String = ",") = { FileUtil.fullyDelete(new File(file)) val tmpFile = "/tmp/" + System.currentTimeMillis() + "-" + file val rows: RDD[String] = withoutHeader.mapPartitions(lines => { val parser = new CSVParser(',') lines.map(line => { val columns = parser.parseLine(line) fn(columns).mkString(separator) }) }) if (distinct) rows.distinct() saveAsTextFile tmpFile else rows.saveAsTextFile(tmpFile) merge(tmpFile, file, header) } def dropHeader(data: RDD[String]): RDD[String] = { data.mapPartitionsWithIndex((idx, lines) => { if (idx == 0) { lines.drop(1) } lines }) }} |
Теперь нам нужно отправить работу в Spark. Я обернул это в сценарий, если вы хотите следовать, но это содержание:
|
1
2
3
4
5
6
|
./spark-1.1.0-bin-hadoop1/bin/spark-submit \--driver-memory 5g \--class GenerateCSVFiles \--master local[8] \ target/scala-2.10/playground_2.10-1.0.jar \$@ |
Если мы выполним это, мы получим следующие CSV-файлы:
|
1
2
3
4
5
6
|
$ ls -alh /tmp/*.csv-rwxrwxrwx 1 markneedham wheel 3.0K 14 Apr 07:37 /tmp/beats.csv-rwxrwxrwx 1 markneedham wheel 217M 14 Apr 07:37 /tmp/crimes.csv-rwxrwxrwx 1 markneedham wheel 84M 14 Apr 07:37 /tmp/crimesBeats.csv-rwxrwxrwx 1 markneedham wheel 120M 14 Apr 07:37 /tmp/crimesPrimaryTypes.csv-rwxrwxrwx 1 markneedham wheel 912B 14 Apr 07:37 /tmp/primaryTypes.csv |
Давайте быстро проверим, что они содержат:
|
01
02
03
04
05
06
07
08
09
10
11
|
$ head -n 10 /tmp/beats.csvid:ID(Beat),:LABEL1135,Beat1421,Beat2312,Beat1113,Beat1014,Beat2411,Beat1333,Beat2521,Beat1652,Beat |
|
01
02
03
04
05
06
07
08
09
10
11
|
$ head -n 10 /tmp/crimes.csvid:ID(Crime),:LABEL,date,description9464711,Crime,01/14/2014 05:00:00 AM,SIMPLE9460704,Crime,01/14/2014 04:55:00 AM,ARMED: HANDGUN9460339,Crime,01/14/2014 04:44:00 AM,TO PROPERTY9461467,Crime,01/14/2014 04:43:00 AM,$500 AND UNDER9460355,Crime,01/14/2014 04:21:00 AM,$500 AND UNDER9461140,Crime,01/14/2014 03:17:00 AM,FORCIBLE ENTRY9460361,Crime,01/14/2014 03:12:00 AM,$500 AND UNDER9461691,Crime,01/14/2014 03:00:00 AM,HOME INVASION9461792,Crime,01/14/2014 03:00:00 AM,OVER $500 |
|
01
02
03
04
05
06
07
08
09
10
11
|
$ head -n 10 /tmp/crimesBeats.csv:START_ID(Crime),:END_ID(Beat),:TYPE5896915,0733,ON_BEAT9208776,2232,ON_BEAT8237555,0111,ON_BEAT6464775,0322,ON_BEAT6468868,0411,ON_BEAT4189649,0524,ON_BEAT7620897,0421,ON_BEAT7720402,0321,ON_BEAT5053025,1115,ON_BEAT |
Хорошо смотритесь. Давайте импортируем их в Neo4j:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
$ ./neo4j-community-2.2.0/bin/neo4j-import --into /tmp/my-neo --nodes /tmp/crimes.csv --nodes /tmp/beats.csv --nodes /tmp/primaryTypes.csv --relationships /tmp/crimesBeats.csv --relationships /tmp/crimesPrimaryTypes.csvNodes[*>:45.76 MB/s----------------------------------|PROPERTIES(2)=============|NODE:3|v:118.05 MB/] 4MDone in 5s 605msPrepare node index[*RESOLVE:64.85 MB-----------------------------------------------------------------------------] 4MDone in 4s 930msCalculate dense nodes[>:42.33 MB/s-------------------|*PREPARE(7)===================================|CALCULATOR-----] 8MDone in 5s 417msRelationships[>:42.33 MB/s-------------|*PREPARE(7)==========================|RELATIONSHIP------------|v:44.] 8MDone in 6s 62msNode --> Relationship[*>:??-----------------------------------------------------------------------------------------] 4MDone in 324msRelationship --> Relationship[*LINK-----------------------------------------------------------------------------------------] 8MDone in 1s 984msNode counts[*>:??-----------------------------------------------------------------------------------------] 4MDone in 360msRelationship counts[*>:??-----------------------------------------------------------------------------------------] 8MDone in 653ms IMPORT DONE in 26s 517ms |
Затем я обновил conf / neo4j-server.properties, чтобы он указывал на мою новую базу данных:
|
1
2
3
4
5
6
7
|
#***************************************************************# Server configuration#*************************************************************** # location of the database directory#org.neo4j.server.database.location=data/graph.dborg.neo4j.server.database.location=/tmp/my-neo |
Теперь я могу запустить Neo и начать изучать данные:
|
1
|
$ ./neo4j-community-2.2.0/bin/neo4j start |
|
1
2
3
|
MATCH (:Crime)-[r:CRIME_TYPE]->() RETURN r LIMIT 10 |
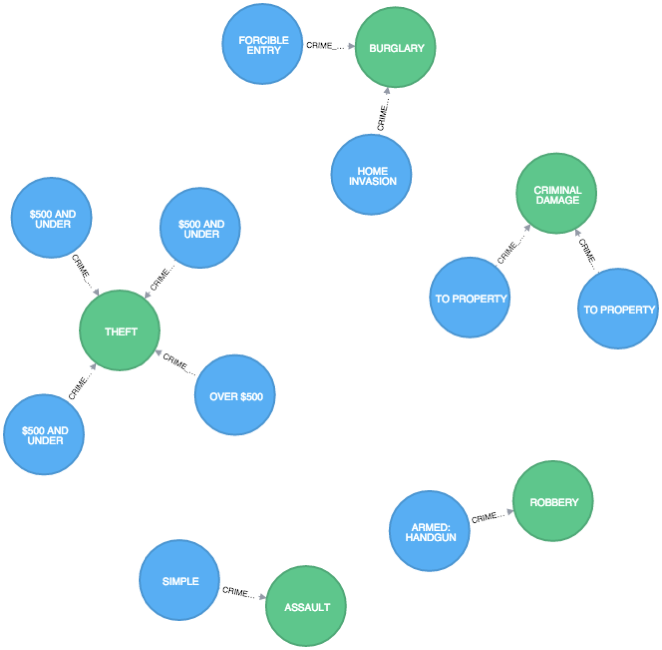
Есть намного больше связей и сущностей, которые мы могли бы извлечь из этого набора данных — то, что я сделал, это только начало. Так что, если вы хотите больше узнать о преступлениях в Чикаго, код и инструкции, объясняющие, как его использовать, находятся на github .
| Ссылка: | Spark: создание CSV-файлов для импорта в Neo4j от нашего партнера по JCG Марка Нидхэма в блоге Марка Нидхэма . |