В качестве продолжения поста об анатомии apache-spark-job я поделюсь с вами тем, как вы можете использовать Spark UI для настройки работы. Я продолжу с тем же примером, который использовался в предыдущем посте, новое приложение spark будет делать ниже вещей
— Прочтите парковочный билет Нью-Йорка
— Агрегирование по «Идентификационному номеру» и подсчет дат нарушения
— Сохранить результат
DAG для этого кода выглядит следующим образом
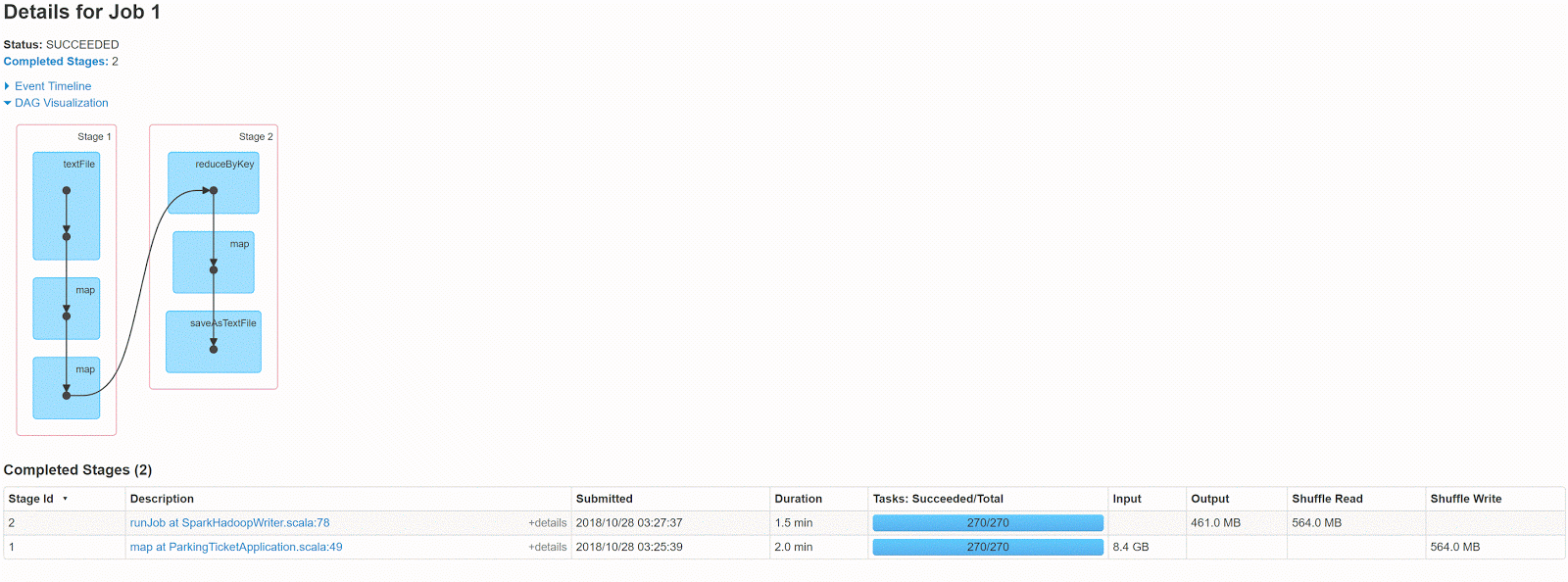
Это многоэтапное задание, поэтому требуется некоторая перестановка данных, для этого примера записи в произвольном порядке — 564 МБ, а выходной — 461 МБ.
Давайте посмотрим, что мы можем сделать, чтобы уменьшить это?
давайте возьмем подход сверху вниз от «Stage2». Первое, что приходит на ум, это изучить сжатие.
Текущий код
|
1
2
3
|
aggValue.map { case (key, value) => Array(key, value._1, value._2.mkString(",")).mkString("\t") }.saveAsTextFile(s"/data/output/${now}") |
Новый код
|
1
2
3
|
aggValue.map { case (key, value) => Array(key, value._1, value._2.mkString(",")).mkString("\t") }.saveAsTextFile(s"/data/output/${now}", classOf[GzipCodec]) |
Новый код позволяет только gzip при записи, давайте посмотрим, что мы видим в spark UI

Сохранить с помощью Gzip
При только записи энкодера запись сократилась на 70%. Теперь он 135Mb, и это ускоряет работу.
Давайте посмотрим, что еще возможно, прежде чем мы погрузимся в настройку внутреннего
Окончательный вывод выглядит примерно так, как показано ниже
|
1
2
3
4
5
|
1RA32 1 05/07/201492062KA 2 07/29/2013,07/18/2013GJJ1410 3 12/07/2016,03/04/2017,04/25/2015FJZ3486 3 10/21/2013,01/25/2014FDV7798 7 03/09/2014,01/14/2014,07/25/2014,11/21/2015,12/04/2015,01/16/2015 |
Дата нарушения хранится в необработанном формате, к этому можно применить небольшую кодировку, чтобы увеличить скорость.
Java 8 добавила LocalDate, чтобы упростить манипулирование датами, и этот класс поставляется с некоторыми удобными функциями, одной из которых является toEpocDay.
Эта функция преобразовывает дату в день с 1970 года, и это означает, что в 4 байтах (Int) мы можем хранить до 5 тысяч лет, это кажется большой экономией по сравнению с текущим форматом, который занимает 10 байтов.
Фрагмент кода с epocDay
|
1
2
3
4
|
val issueDate = LocalDate.parse(row(aggFieldsOffset.get("issue date").get), ISSUE_DATE_FORMAT) val issueDateValues = mutable.Set[Int]() issueDateValues.add(issueDate.toEpochDay.toInt) result = (fieldOffset.map(fieldInfo => row(fieldInfo._2)).mkString(","), (1, issueDateValues)) |
Пользовательский интерфейс Spark после этого изменения. Я также сделал еще одно изменение, чтобы использовать KryoSerializer

Это огромное улучшение, запись в случайном порядке изменилась с 564 МБ до 409 МБ (на 27% лучше), а объем вывода с 134 МБ до 124 МБ (на 8% лучше)
Теперь давайте перейдем к другому разделу в Spark UI, который показывает журналы со стороны исполнителя.
Журналы GC для показа выше показа
|
01
02
03
04
05
06
07
08
09
10
11
|
<i>2018-10-28T17:13:35.332+0800: 130.281: [GC (Allocation Failure) [PSYoungGen: 306176K->20608K(327168K)] 456383K->170815K(992768K), 0.0222440 secs] [Times: user=0.09 sys=0.00, real=0.03 secs]</i><i>2018-10-28T17:13:35.941+0800: 130.889: [GC (Allocation Failure) [PSYoungGen: 326784K->19408K(327168K)] 476991K->186180K(992768K), 0.0152300 secs] [Times: user=0.09 sys=0.00, real=0.02 secs]</i><i>2018-10-28T17:13:36.367+0800: 131.315: [GC (GCLocker Initiated GC) [PSYoungGen: 324560K->18592K(324096K)] 491332K->199904K(989696K), 0.0130390 secs] [Times: user=0.11 sys=0.00, real=0.01 secs]</i><i>2018-10-28T17:13:36.771+0800: 131.720: [GC (GCLocker Initiated GC) [PSYoungGen: 323744K->18304K(326656K)] 505058K->215325K(992256K), 0.0152620 secs] [Times: user=0.09 sys=0.00, real=0.02 secs]</i><i>2018-10-28T17:13:37.201+0800: 132.149: [GC (Allocation Failure) [PSYoungGen: 323456K->20864K(326656K)] 520481K->233017K(992256K), 0.0199460 secs] [Times: user=0.12 sys=0.00, real=0.02 secs]</i><i>2018-10-28T17:13:37.672+0800: 132.620: [GC (Allocation Failure) [PSYoungGen: 326016K->18864K(327168K)] 538169K->245181K(992768K), 0.0237590 secs] [Times: user=0.17 sys=0.00, real=0.03 secs]</i><i>2018-10-28T17:13:38.057+0800: 133.005: [GC (GCLocker Initiated GC) [PSYoungGen: 324016K->17728K(327168K)] 550336K->259147K(992768K), 0.0153710 secs] [Times: user=0.09 sys=0.00, real=0.01 secs]</i><i>2018-10-28T17:13:38.478+0800: 133.426: [GC (Allocation Failure) [PSYoungGen: 322880K->18656K(326144K)] 564301K->277690K(991744K), 0.0156780 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]</i><i>2018-10-28T17:13:38.951+0800: 133.899: [GC (Allocation Failure) [PSYoungGen: 323808K->21472K(326656K)] 582842K->294338K(992256K), 0.0157690 secs] [Times: user=0.09 sys=0.00, real=0.02 secs]</i><i>2018-10-28T17:13:39.384+0800: 134.332: [GC (Allocation Failure) [PSYoungGen: 326624K->18912K(317440K)] 599490K->305610K(983040K), 0.0126610 secs] [Times: user=0.11 sys=0.00, real=0.02 secs]</i><i>2018-10-28T17:13:39.993+0800: 134.941: [GC (Allocation Failure) [PSYoungGen: 313824K->17664K(322048K)] 600522K->320486K(987648K), 0.0111380 secs] [Times: user=0.00 sys=0.00, real=0.02 secs]</i> |
Давайте сосредоточимся на одной строке
|
1
|
<i>2018-10-28T17:13:39.993+0800: 134.941: [GC (Allocation Failure) [PSYoungGen: 313824K->17664K(322048K)] <b>600522K->320486K(987648K)</b>, 0.0111380 secs] [Times: user=0.00 sys=0.00, real=0.02 secs]</i> |
Куча до младшего GC составляла 600 МБ, а после этого — 320 МБ, а общий размер кучи — 987 МБ.
Исполнителю выделяется 2 ГБ, и это приложение Spark не использует всю память, мы можем увеличить нагрузку на исполнителя, отправив больше задач или задач больше.
Я уменьшу входной раздел с 270 до 100

С 270 входным разделом

С 100 входными разделами
100 входных разделов выглядит лучше примерно на 10 +% меньше данных для перемешивания.
Другие хитрости
Теперь я поделюсь некоторыми вещами, которые будут иметь большое значение в GC!
Код перед оптимизацией
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
private def mergeValues(value1: (Int, mutable.Set[Int]), value2: (Int, mutable.Set[Int])): (Int, mutable.Set[Int]) = { val newCount = value1._1 + value2._1 val dates = value1._2 dates.foreach(d => value2._2.add(d)) (newCount, value2._2) } private def saveData(aggValue: RDD[(String, (Int, mutable.Set[Int]))], now: String) = { aggValue .map { case (key, value) => Array(key, value._1, value._2.mkString(",")).mkString("\t") }.coalesce(100) .saveAsTextFile(s"/data/output/${now}", classOf[GzipCodec]) } |
Код после оптимизации
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
private def mergeValues(value1: GroupByValue, value2: GroupByValue): GroupByValue = { if (value2.days.size > value1.days.size) { value2.count = value1.count + value2.count value1.days.foreach(d => value2.days.add(d)) value2 } else { value1.count = value1.count + value2.count value2.days.foreach(d => value1.days.add(d)) value1 } } private def saveData(aggValue: RDD[(String, GroupByValue)], now: String) = { aggValue.mapPartitions(rows => { val buffer = new StringBuffer() rows.map { case (key, value) => buffer.setLength(0) buffer .append(key).append("\t") .append(value.count).append("\t") .append(value.days.mkString(",")) buffer.toString } }) .coalesce(100) .saveAsTextFile(s"/data/output/${now}", classOf[GzipCodec]) } |
Новый код выполняет оптимизированное слияние наборов, добавляет маленький набор к большому и также вводит класс Case.
Другая оптимизация заключается в функции сохранения, где она использует mapPartitions для уменьшения выделения объектов с помощью StringBuffer.
Я использовал http://gceasy.io для получения статистики GC.

До изменения кода
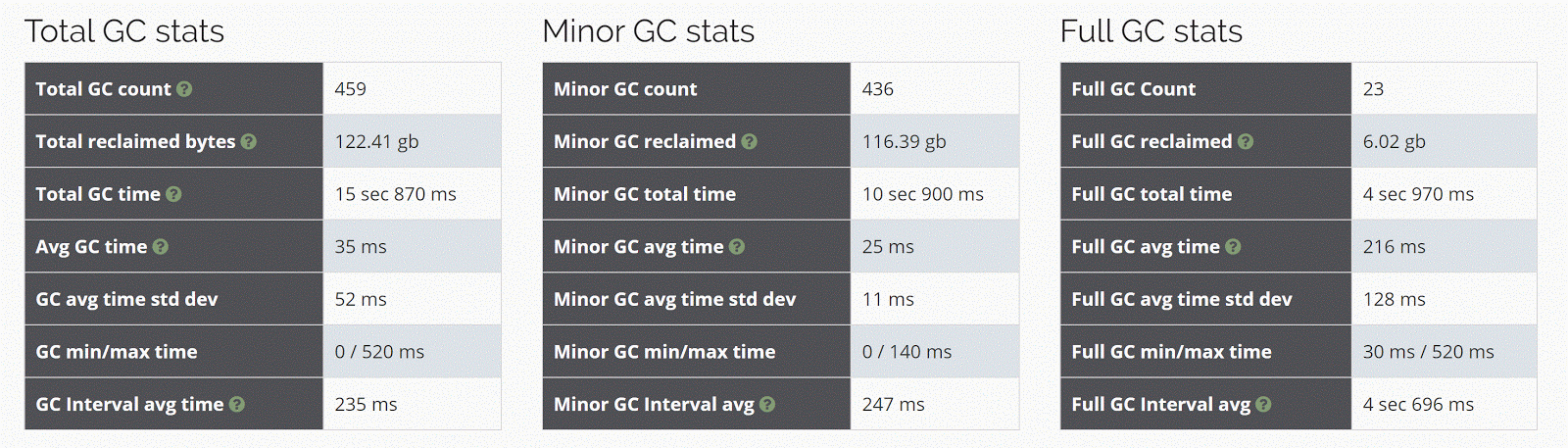
После изменения кода
Новый код производит меньше мусора, например.
Всего GC 126 ГБ против 122 ГБ (примерно на 4% лучше)
Максимальное время GC 720 мс против 520 мс (примерно на 25% лучше)
Оптимизация выглядит многообещающе.
Весь код, используемый в этом блоге, доступен на github repo sparkperformance.
Оставайтесь с нами, чтобы узнать больше об этом.
| Смотрите оригинальную статью здесь: Insights от Spark UI
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |