Это будет еще одна история, рассказывающая о нашем недавнем опыте с проблемами памяти. Случай извлечен из недавнего случая поддержки клиентов, когда мы столкнулись с плохим поведением приложения, неоднократно умирающего с сообщениями OutOfMemoryError в производстве. После запуска приложения с подключенным Plumbr мы были уверены, что на этот раз мы не столкнулись с утечкой памяти. Но что-то было все еще ужасно неправильно.
Симптомы были обнаружены одной из наших экспериментальных функций, отслеживающих накладные расходы на определенные структуры данных. Это дало нам сигнал, указывающий на одно конкретное место в исходном коде. Чтобы защитить конфиденциальность клиента, мы воссоздали случай, используя синтетический образец, в то же время сохраняя его технически эквивалентным исходной проблеме. Не стесняйтесь загружать исходный код . 
Мы обнаружили, что уставились на набор объектов, загруженных из внешнего источника. Связь с внешней системой осуществлялась через интерфейс XML. Что само по себе неплохо. Но тот факт, что детали реализации интеграции были разбросаны по всей системе — полученные документы были преобразованы в экземпляры XMLBean и затем использованы по всей системе — не был, возможно, самым мудрым.
По сути, мы имели дело с лениво загруженным решением для кэширования. Кэшированные объекты были персоны:
|
1
2
3
4
5
6
7
|
// Imports and methods removed to improve readabilitypublic class Person {private String id;private Date dateOfBirth;private String forename;private String surname;} |
Можно подумать, не слишком много памяти. Но вещи начинают выглядеть немного более кислыми, когда мы раскрываем некоторые детали. А именно реализация этих данных была чем-то похожим на простое объявление класса выше. Вместо этого в реализации использовалась сгенерированная моделью структура данных. Используемая модель была похожа на следующий упрощенный фрагмент XSD :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
elementFormDefault="qualified"><xs:element name="person"><xs:complexType><xs:sequence><xs:element name="id" type="xs:string"/><xs:element name="dateOfBirth" type="xs:dateTime"/><xs:element name="forename" type="xs:string"/><xs:element name="surname" type="xs:string"/></xs:sequence></xs:complexType></xs:element></xs:schema> |
Используя XMLBeans , разработчик создал модель, используемую за кулисами. Теперь давайте добавим тот факт, что кэш должен был содержать до 1,3 млн. Экземпляров Persons, и мы создали прочную основу для отказа.
Запуск связанного тестового примера дал нам понять, что 1,3 млн. Экземпляров решения на основе XMLBean будут занимать примерно 1,5 ГБ кучи. Мы думали, что можем сделать лучше.
Первое решение очевидно. Детали интеграции не должны выходить за границы системы. Поэтому мы изменили решение для кэширования на простое решение java.util.HashMap <Long, Person> . ID в качестве ключа и объект Person в качестве значения. Сразу же мы увидели, что потребление памяти сократилось до 214 МБ . Но мы еще не были удовлетворены.
Поскольку ключ на карте был, по сути, числом, у нас были все причины использовать коллекции Trove для дальнейшего сокращения накладных расходов. Быстрое изменение в реализации, и мы заменили нашу HashMap на TLongObjectHashMap <Person> . Потребление кучи упало до 143 МБ .
Мы определенно могли бы остановиться там, но инженерное любопытство не позволило нам сделать это. Мы не могли не заметить, что используемые данные содержали избыточную часть информации. Дата рождения фактически была закодирована в идентификаторе, поэтому вместо дублирования в дополнительном поле мы могли легко рассчитать день рождения по данному идентификатору.
Поэтому мы изменили макет объекта Person, и теперь он содержит только следующие поля:
|
1
2
3
4
5
6
|
// Imports and methods removed to improve readabilitypublic class Person {private long id;private String forename;private String surname;} |
Повторный запуск испытаний подтвердил наши ожидания. Потребление кучи снизилось до 93 МБ . Но мы все еще не были удовлетворены.
Приложение работало на 64-битной машине со старой версией JDK6. Который по умолчанию не сжимал обычные указатели объектов . Переключение на -XX: + UseCompressedOops дало нам дополнительный выигрыш — теперь мы сократили потребление до 73 МБ .
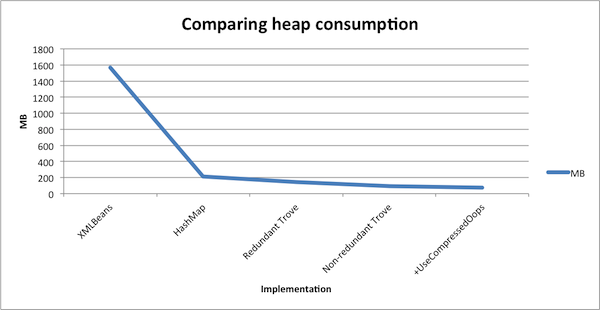
Мы могли бы пойти дальше и начать интернирование строк или построение b-дерева на основе ключей, но это уже начало бы влиять на читабельность кода, поэтому мы решили на этом остановиться. 21,5-кратное уменьшение кучи уже должно быть достаточно хорошим результатом.
Уроки выучены?
- Не позволяйте деталям интеграции пересекать границы системы
- Избыточные данные будут дорогостоящими. Удалите избыточность, когда вы можете.
- Примитивы твои друзья. Знай свои инструменты и изучай Trove, если ты еще не
- Будьте осведомлены о методах оптимизации, предоставляемых вашей JVM
Если вам интересно провести проведенный эксперимент, не стесняйтесь скачать код, используемый здесь. Утилита, используемая для измерений, описана и доступна в этом посте .