Построение системы рекомендаций с помощью Spark — простая задача. Библиотека машинного обучения Spark уже выполняет всю тяжелую работу за нас.
В этом исследовании я покажу вам, как создать масштабируемое приложение для больших данных, используя следующие технологии:
- Scala Language
- Искра с машинным обучением
- Акка с актерами
- Cassandra
Система рекомендаций — это механизм фильтрации информации, который пытается предсказать рейтинг, который пользователь даст конкретному продукту. Есть несколько алгоритмов для создания системы рекомендаций.
В Apache Spark ML реализованы чередующиеся наименьшие квадраты (ALS) для совместной фильтрации, очень популярный алгоритм для выработки рекомендаций.
ALS Recommender — это алгоритм матричной факторизации, который использует чередующиеся наименьшие квадраты с взвешенной лямда-регуляризацией (ALS-WR). Он подразделяет пользователя на матрицу A элементов в матрицу U пользовательских элементов и матрицу M элементов на элемент: он выполняет алгоритм ALS параллельно. Алгоритм ALS должен выявлять скрытые факторы, которые объясняют наблюдаемого пользователя для рейтингов предметов, и пытается найти оптимальные веса факторов, чтобы минимизировать наименьшие квадраты между прогнозируемыми и фактическими рейтингами.
Пример:
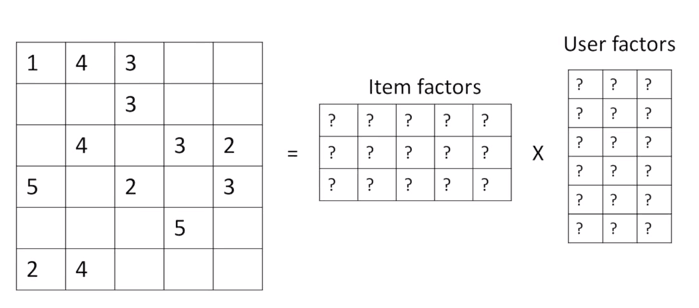
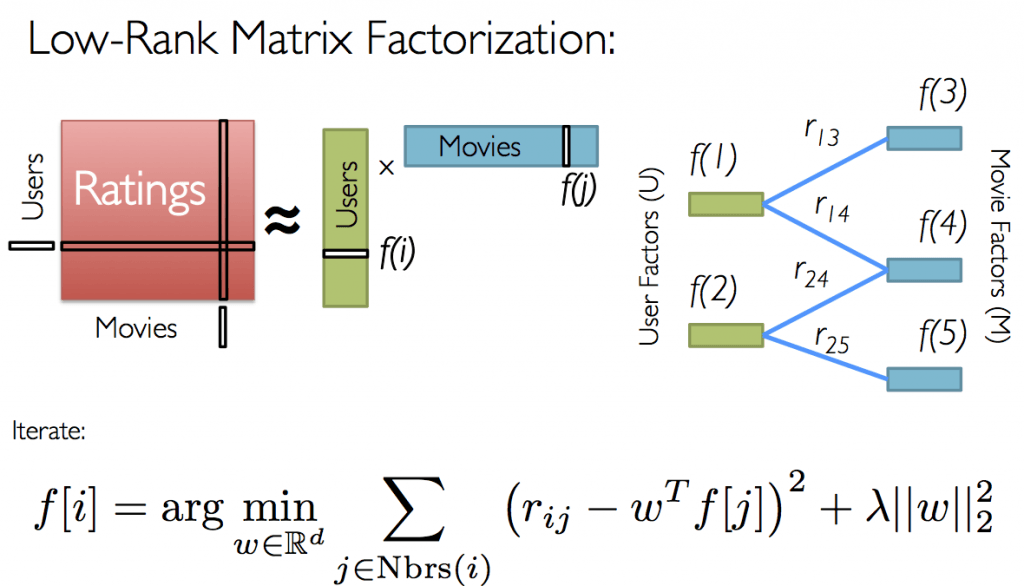
Мы также знаем, что не все пользователи оценивают продукты (фильмы), или мы еще не знаем все записи в матрице. С помощью совместной фильтрации идея состоит в том, чтобы приблизить матрицу рейтингов, разложив ее как произведение двух матриц: одна, которая описывает свойства каждого пользователя (показана зеленым цветом), и другая, которая описывает свойства каждого фильма (показана синим цветом).
Пример:
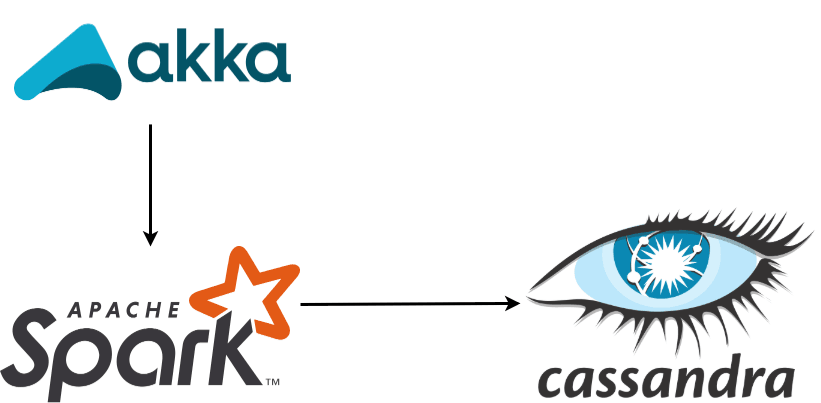
1. Архитектура проекта
Архитектура, используемая в проекте:
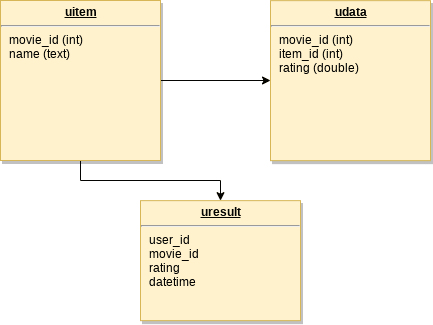
2. Набор данных
Наборы данных с информацией о фильме и рейтингом пользователей были взяты с сайта Movie Lens . Затем данные были настроены и загружены в Apache Cassandra. Докер также использовался для Кассандры.
Пространство клавиш называется фильмы. Данные в Кассандре моделируются следующим образом:
3. Код
Код доступен в: https://github.com/edersoncorbari/movie-rec
4. Организация и конечные точки
Коллекции:
| Коллекция | Комментарии |
|---|---|
| movies.uitem | Содержит доступные фильмы, общий набор данных составляет 1682. |
| movies.udata | Содержит фильмы, оцененные каждым пользователем, общий набор данных составляет 100000. |
| movies.uresult | Где данные, рассчитанные моделью, сохраняются, по умолчанию они пусты. |
Конечные точки:
| метод | End-Point | Комментарии |
|---|---|---|
| ПОЧТА | / Фильм-модель поезд | Сделайте обучение модели. |
| ПОЛУЧИТЬ | / Фильм-Get-рекомендация / {ID} | Списки рекомендованных пользователем фильмов. |
5. Практическая стыковка и настройка Cassandra
Выполните команды ниже, чтобы загрузить и настроить cassandra:
|
1
2
|
$ docker pull cassandra:3.11.4$ docker run --name cassandra-movie-rec -p 127.0.0.1:9042:9042 -p 127.0.0.1:9160:9160 -d cassandra:3.11.4 |
В каталоге проекта (movie-rec) есть наборы данных, уже подготовленные для помещения в Cassandra.
|
1
2
3
|
$ cd movie-rec$ cat dataset/ml-100k.tar.gz | docker exec -i cassandra-movie-rec tar zxvf - -C /tmp$ docker exec -it cassandra-movie-rec cqlsh -f /tmp/ml-100k/schema.cql |
6. Практический Бег и тестирование
Войдите в корневую папку проекта и выполните команды, если SBT впервые загрузит необходимые зависимости.
|
1
|
$ sbt run |
Теперь! В другом терминале выполните команду для обучения модели:
|
1
|
$ curl -XPOST http://localhost:8080/movie-model-train |
Это начнет модель обучения. Затем вы можете запустить команду, чтобы увидеть результаты с рекомендациями. Пример:
|
1
|
$ curl -XGET http://localhost:8080/movie-get-recommendation/1 |
Ответ должен быть:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
{ "items": [ { "datetime": "Thu Oct 03 15:37:34 BRT 2019", "movieId": 613, "name": "My Man Godfrey (1936)", "rating": 6.485164882121823, "userId": 1 }, { "datetime": "Thu Oct 03 15:37:34 BRT 2019", "movieId": 718, "name": "In the Bleak Midwinter (1995)", "rating": 5.728434247420009, "userId": 1 }, ...} |
Это глазурь на торте! Помните, что настройка настроена на показ 10 рекомендаций по фильмам на пользователя.
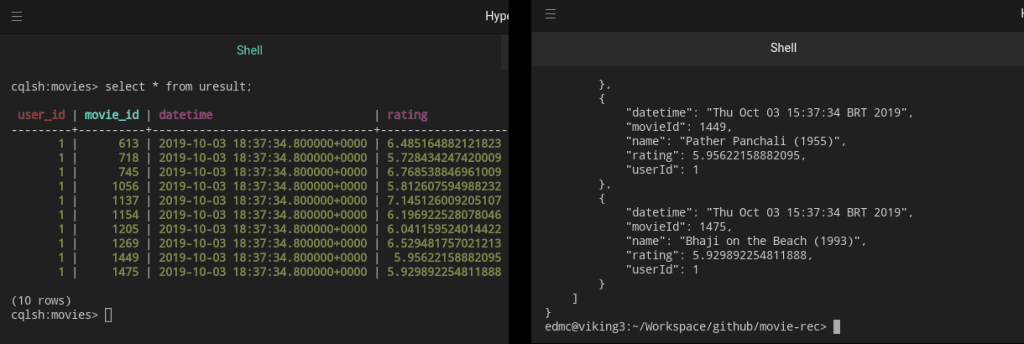
Вы также можете проверить результат в коллекции uresult:
7. Модель Предсказания
Настройки обучения модели и приложения находятся в: ( src / main / resources / application.conf )
|
1
2
3
4
5
|
model { rank = 10 iterations = 10 lambda = 0.01} |
Этот параметр контролирует прогнозы и связан с тем, сколько и какие данные у нас есть. Для получения более подробной информации о проекте, пожалуйста, перейдите по ссылке:
8. Ссылки
Для разработки этого демонстрационного проекта были использованы книги:
- Проекты машинного обучения Scala
- Реактивное программирование с Scala и Akka
И Документация Spark ML:
- https://spark.apache.org/docs/2.2.0/ml-collaborative-filtering.html
- https://spark.apache.org/docs/latest/ml-guide.html
Спасибо!
|
Смотреть оригинальную статью здесь: Система рекомендаций с использованием Spark ML Akka и Cassandra Мнения, высказанные участниками Java Code Geeks, являются их собственными. |