Последовательный, Параллельный, Параллельный, CMS, G1, Молодой Генерал, Новый Генерал, Старый Генерал, Пермский Генерал, Иден, Аура, Пространства Выживших, Безопасные Точки и сотни флагов запуска JVM. Все ли это сбивает вас с толку, когда вы пытаетесь настроить сборщик мусора, пытаясь получить необходимую пропускную способность и задержку от вашего Java-приложения? Если это так, не волнуйтесь, вы не одиноки. Документация, описывающая сборку мусора, напоминает справочные страницы для самолета. Каждая ручка и циферблат детализированы и объяснены, но нигде вы не найдете руководства о том, как летать. В этой статье мы попытаемся объяснить компромиссы при выборе и настройке алгоритмов сборки мусора для конкретной рабочей нагрузки.
Основное внимание будет уделено сборщикам Oracle Hotspot JVM и OpenJDK, так как они наиболее часто используются. В конце будут обсуждены другие коммерческие JVM для иллюстрации альтернатив.
Компромиссы
Мудрый народ постоянно говорит нам: «Вы не получаете что-то даром» . Когда мы получаем что-то, мы обычно должны что-то бросить взамен. Когда дело доходит до сбора мусора, мы играем с 3 основными переменными, которые устанавливают цели для сборщиков:
- Пропускная способность: объем работы, выполненной приложением, как отношение времени, проведенного в GC. Целевая пропускная способность с ‑XX: GCTimeRatio = 99; 99 является значением по умолчанию, равным 1% времени GC.
- Задержка: время, затрачиваемое системами на реагирование на события, на которые влияют паузы, вносимые сборщиком мусора. Заданная задержка для пауз GC с ‑XX: MaxGCPauseMillis = <n>.
- Память: объем памяти, используемый нашими системами для хранения состояния, который часто копируется и перемещается при управлении. Набор активных объектов, сохраняемых приложением в любой момент времени, называется живым набором. Максимальный размер кучи –Xmx <n> — это параметр настройки для установки размера кучи, доступного для приложения.
Примечание: часто Hotspot не может достичь этих целей и молча продолжает без предупреждения, пропустив свою цель с большим отрывом.
Задержка — это распределение по событиям. Может быть приемлемым иметь увеличенную среднюю задержку, чтобы уменьшить задержку в худшем случае или сделать ее менее частой. Мы не должны интерпретировать термин «в режиме реального времени» как означающий минимально возможную задержку; скорее в реальном времени относится к наличию детерминированной задержки независимо от пропускной способности.
Для некоторых рабочих нагрузок приложения пропускная способность является наиболее важной целью. Примером может служить длительное задание на пакетную обработку; не имеет значения, если пакетное задание иногда приостанавливается на несколько секунд, пока происходит сборка мусора, если общее задание может быть выполнено раньше.
Практически для всех других рабочих нагрузок, от интерактивных приложений, ориентированных на человека, до систем финансовой торговли, если система в некоторых случаях перестает отвечать на запросы более чем на несколько секунд или даже миллисекунд, это может привести к катастрофе. В финансовых операциях часто стоит обменять некоторую пропускную способность на постоянную задержку. У нас также могут быть приложения, которые ограничены объемом доступной физической памяти и должны поддерживать занимаемую площадь, и в этом случае нам приходится отказываться от производительности как по задержкам, так и по пропускной способности.
Компромиссы часто разыгрываются следующим образом:
- В значительной степени затраты на сборку мусора, как амортизированную стоимость, можно снизить, предоставляя алгоритмам сборки мусора больше памяти.
- Наблюдаемые наихудшие паузы, вызывающие задержку из-за сбора мусора, могут быть уменьшены путем размещения живого набора и сохранения небольшого размера кучи.
- Частота возникновения пауз может быть уменьшена путем управления кучей и размерами генерации, а также путем управления скоростью выделения объектов приложения.
- Частота больших пауз может быть уменьшена путем одновременного запуска ГХ с приложением, иногда за счет пропускной способности.
Время жизни объекта
Алгоритмы сбора мусора часто оптимизируются с учетом того, что большинство объектов живут очень короткое время, а относительно немногие живут очень долго. В большинстве приложений объекты, которые живут в течение значительного периода времени, как правило, составляют очень небольшой процент объектов, распределенных с течением времени. В теории сбора мусора это наблюдаемое поведение часто называют « детской смертностью » или « слабой гипотезой поколений ». Например, итераторы цикла в основном недолговечны, тогда как статические строки фактически бессмертны.
Эксперименты показали, что сборщики мусора поколений обычно поддерживают на порядок большую пропускную способность, чем сборщики не поколений, и, таким образом, почти повсеместно используются в серверных JVM. Разделяя поколения объектов, мы знаем, что область вновь выделенных объектов, вероятно, будет очень разреженной для живых объектов. Поэтому коллектор, который очищает несколько живых объектов в этом новом регионе и копирует их в другой регион для более старых объектов, может быть очень эффективным. Сборщики мусора Hotspot записывают возраст объекта с точки зрения числа выживших циклов GC.
Примечание. Если ваше приложение последовательно генерирует множество объектов, которые живут довольно долго, ожидайте, что ваше приложение будет тратить значительную часть своего времени на сбор мусора, и ожидаете, что вы потратите значительную часть своего времени на настройку сборщиков мусора Hotspot , Это связано с пониженной эффективностью ГХ, которая возникает, когда «фильтр» поколений менее эффективен, и, как следствие, с более частыми затратами на сбор более продолжительных поколений. Старшие поколения менее редки, и в результате эффективность алгоритмов сбора старых поколений имеет тенденцию быть намного ниже. Сборщики мусора поколений, как правило, работают в двух разных циклах сбора: второстепенные сборы, когда собираются недолговечные объекты, и менее частые крупные сборки, когда собираются более старые регионы.
События Stop-The-World
Паузы, от которых страдают приложения во время сбора мусора, вызваны так называемыми событиями остановки мира. Для работы сборщиков мусора по практическим инженерным соображениям необходимо периодически останавливать работающее приложение, чтобы можно было управлять памятью. В зависимости от алгоритмов, различные сборщики будут останавливать мир в определенных точках выполнения в течение различных периодов времени. Для полной остановки приложения необходимо приостановить все запущенные потоки. Сборщики мусора делают это, сигнализируя потокам останавливаться, когда они достигают « безопасной точки », которая является точкой во время выполнения программы, когда все корни GC известны и все содержимое объектов кучи согласовано. В зависимости от того, что делает поток, для достижения безопасной точки может потребоваться некоторое время. Проверки Safepoint обычно выполняются для возвратов методов и обратных контуров, но в некоторых местах их можно оптимизировать, что делает их более динамически редкими. Например, если поток копирует большой массив, клонирует большой объект или выполняет цикл с монотонным счетом с конечной границей, может пройти много миллисекунд до достижения безопасной точки. Time To Safepoint (TTS) является важным фактором в приложениях с низкой задержкой. Это время можно узнать, включив флаг ‑XX: + PrintGCApplicationStoppedTime в дополнение к другим флагам GC.
Примечание. Для приложений с большим количеством работающих потоков, когда происходит событие остановки мира, система подвергнется значительному давлению планирования, так как потоки возобновляются после освобождения. Следовательно, алгоритмы с меньшей зависимостью от событий «останови мир» потенциально могут быть более эффективными.
Организация кучи в Hotspot
Чтобы понять, как работают различные сборщики, лучше всего изучить, как организована куча Java для поддержки сборщиков поколений.
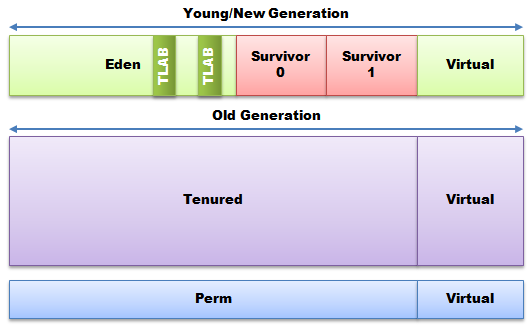
Эдем — это регион, в котором изначально размещено большинство объектов. Пространства выживших являются временным хранилищем для объектов, которые пережили коллекцию пространства Эдема. Использование оставшегося в живых пространства будет описано, когда будут обсуждаться второстепенные коллекции. В совокупности Эдем и пространства выживших известны как «молодое» или «новое» поколение.
Объекты, которые живут достаточно долго, в конечном итоге переводятся в арендованное пространство.
Пермская генерация — это место, где среда выполнения хранит объекты, которые она «знает», чтобы быть эффективно бессмертными, такие как классы и статические строки. К сожалению, общее использование загрузки классов на постоянной основе во многих приложениях делает неверным мотивирующее предположение, лежащее в основе создания perm, то есть, что классы бессмертны. В Java 7 встроенные строки были перенесены из permgen в арендованные , а из Java 8 поколения perm больше нет и не будет обсуждаться в этой статье. Большинство других коммерческих коллекционеров не используют отдельное пространство для перманента и склонны рассматривать все долгоживущие объекты как арендованные.
Примечание . Виртуальные пространства позволяют сборщикам регулировать размер областей в соответствии с целевыми показателями пропускной способности и задержки. Сборщики ведут статистику по каждому этапу сбора и соответственно корректируют размеры регионов, пытаясь достичь целей.
Распределение объектов
Чтобы избежать конфликта, каждому потоку назначается локальный буфер размещения потоков (TLAB), из которого он выделяет объекты. Использование TLAB позволяет масштабировать распределение объектов по количеству потоков, избегая конфликтов на одном ресурсе памяти. Распределение объектов через TLAB — очень дешевая операция; он просто увеличивает указатель на размер объекта, который занимает примерно 10 инструкций на большинстве платформ. Выделение кучи памяти для Java даже дешевле, чем использование malloc из среды выполнения C.
Примечание. Принимая во внимание, что выделение отдельных объектов очень дешево, скорость, с которой должны происходить второстепенные сборы, прямо пропорциональна скорости выделения объектов.
Когда TLAB исчерпан, поток просто запрашивает новый из пространства Eden. Когда Иден заполнен, начинается небольшая коллекция.
Крупные объекты (-XX: PretenureSizeThreshold = <n>) могут не вместиться в молодое поколение и, следовательно, должны быть выделены в старом поколении, например, большой массив. Если порог установлен ниже размера TLAB, то объекты, которые помещаются в TLAB, не будут созданы в старом поколении. Новый коллектор G1 по-разному обрабатывает большие объекты и будет обсуждаться позже в его собственном разделе.
Незначительные Коллекции
Незначительная коллекция запускается, когда Eden становится полным. Это делается путем копирования всех живых объектов в новом поколении либо в оставшееся место, либо в постоянное пространство, в зависимости от ситуации. Копирование в арендованное пространство называется продвижением или владением. Повышение происходит для объектов, которые являются достаточно старыми (- XX: MaxTenuringThreshold = <n>), или когда переполненное пространство переполнено.
Живые объекты — это объекты, доступные приложению; любые другие объекты не могут быть достигнуты и поэтому могут считаться мертвыми. В второстепенной коллекции копирование живых объектов выполняется, сначала следуя тому, что известно как GC Roots , и итеративно копируя все, что достижимо в пространство оставшихся в живых. Корни GC обычно включают ссылки из внутренних статических полей приложения и JVM, а также из стековых фреймов потоков, которые все эффективно указывают на достижимые графы объектов приложения.
В коллекции поколений корни GC для графа достижимых объектов нового поколения также включают любые ссылки старого поколения на новое поколение. Эти ссылки также должны быть обработаны, чтобы убедиться, что все достижимые объекты в новом поколении переживают второстепенную коллекцию. Выявление этих ссылок между поколениями достигается с помощью « карточного стола ». Таблица карт Hotspot представляет собой массив байтов, в котором каждый байт используется для отслеживания потенциального существования перекрестных ссылок в соответствующей 512-байтовой области старого поколения. Поскольку ссылки сохраняются в куче, код «барьер хранилища» помечает карточки, чтобы указать, что потенциальная ссылка от старого поколения к новому поколению может существовать в соответствующей области кучи 512 байт. Во время сбора данных карточный стол используется для сканирования таких ссылок между поколениями, которые эффективно представляют дополнительные корни GC в новом поколении. Поэтому значительная фиксированная стоимость небольших коллекций прямо пропорциональна размеру старого поколения.
В новом поколении Hotspot есть два пространства для выживших, чередующиеся в ролях « в космос » и « из космоса ». В начале вспомогательной коллекции пространство оставшегося в живых пространства всегда пусто и действует как область целевого копирования для вспомогательной коллекции. Пространство оставшихся в живых предыдущей второстепенной коллекции является частью дальнего космоса, который также включает в себя Эдем, где могут быть найдены живые объекты, которые необходимо скопировать.
В стоимости незначительной коллекции GC обычно преобладают затраты на копирование объектов оставшемуся в живых и арендуемым помещениям. Объекты, которые не переживают незначительную коллекцию, могут свободно обрабатываться. Работа, выполненная во время незначительной коллекции, прямо пропорциональна количеству найденных живых объектов, а не размеру нового поколения. Общее время, затрачиваемое на создание небольших коллекций, можно почти вдвое сократить каждый раз, когда размер Eden удваивается. Поэтому память можно обменять на пропускную способность. Удвоение размера Eden приведет к увеличению времени сбора на цикл сбора, но это относительно мало, если число продвигаемых объектов и размер старого поколения постоянны.
Примечание: в Hotspot второстепенные коллекции — это события «стоп мира». Это быстро становится главной проблемой, поскольку наши кучи становятся больше с большим количеством живых объектов. Мы уже начинаем осознавать необходимость одновременного сбора молодого поколения для достижения поставленных целей.
Основные Коллекции
Крупные коллекции собирают старое поколение, так что объекты можно продвигать с молодого поколения. В большинстве приложений подавляющее большинство программных состояний попадает в старое поколение. Наибольшее разнообразие алгоритмов GC существует для старого поколения. Некоторые будут сжимать все пространство, когда оно заполняется, тогда как другие будут собираться одновременно с приложением, чтобы предотвратить его заполнение.
Коллекционер старого поколения постарается предсказать, когда он должен собрать, чтобы избежать неудачи продвижения молодого поколения. Коллекторы отслеживают порог заполнения для старого поколения и начинают сбор, когда этот порог пройден. Если этот порог недостаточен для удовлетворения требований по продвижению, запускается « FullGC ». FullGC включает в себя продвижение всех живых объектов из молодого поколения с последующим сбором и уплотнением старого поколения. Ошибка продвижения является очень дорогой операцией, так как состояние и продвигаемые объекты из этого цикла должны быть размотаны, чтобы могло произойти событие FullGC.
Примечание. Чтобы избежать неудачи при продвижении по службе, вам необходимо настроить отступы, которые старое поколение позволяет размещать при продвижении (‑XX: PromotedPadding = <n>).
Примечание: когда куча должна расти, запускается FullGC. Этих FullGC с изменением размера кучи можно избежать, установив -Xms и -Xmx в одно и то же значение.
За исключением FullGC, сжатие старого поколения, вероятно, будет самой большой остановкой, которую испытает приложение. Время для этого уплотнения имеет тенденцию линейно расти с количеством живых объектов в арендованном пространстве.
Скорость, с которой занимаемое пространство заполняется, иногда может быть уменьшена путем увеличения размера оставшихся в живых пространств и возраста объектов, прежде чем они будут переведены в штатное поколение. Однако увеличение размера пространств оставшихся в живых и возраста объектов в второстепенных коллекциях (–XX: MaxTenuringThreshold = <n>) перед повышением может также увеличить стоимость и время приостановки в второстепенных коллекциях из-за увеличения стоимости копирования между пробелами оставшихся в живых в второстепенных коллекции.
Серийный коллектор
Последовательный коллектор (-XX: + UseSerialGC) — самый простой коллектор и является хорошим вариантом для однопроцессорных систем. Он также имеет наименьший след среди коллекционеров. Он использует одну нить для малых и крупных коллекций. Объекты размещаются в постоянном пространстве, используя простой алгоритм выделения указателя. Основные коллекции запускаются, когда арендованное пространство заполнено.
Параллельный коллектор
Параллельный коллектор поставляется в двух формах. Параллельный сборщик (‑XX: + UseParallelGC), который использует несколько потоков для выполнения второстепенных коллекций молодого поколения и один поток для основных коллекций старого поколения. Старый параллельный сборщик (‑XX: + UseParallelOldGC), используемый по умолчанию с Java 7u4, использует несколько потоков для второстепенных коллекций и несколько потоков для основных коллекций. Объекты размещаются в постоянном пространстве, используя простой алгоритм выделения указателя. Основные коллекции запускаются, когда арендованное пространство заполнено.
В многопроцессорных системах параллельный старый коллектор дает наибольшую пропускную способность среди всех коллекторов. Он не влияет на работающее приложение, пока не произойдет сбор, а затем будет собираться параллельно, используя несколько потоков, используя наиболее эффективный алгоритм. Это делает коллектор Parallel Old очень подходящим для пакетных приложений.
На стоимость сбора старых поколений влияет количество сохраняемых объектов в большей степени, чем на размер кучи. Следовательно, эффективность коллектора Parallel Old можно повысить для достижения большей пропускной способности, предоставляя больше памяти и принимая большие, но меньшие паузы сбора.
Ожидайте самые быстрые второстепенные коллекции с этим сборщиком, потому что продвижение в постоянное пространство является простым ударом указатель и операция копирования.
Для серверных приложений первый параллельный порт должен быть Parallel Old Collector. Однако, если основные паузы в сборе превышают допустимые для вашего приложения, вам следует рассмотреть возможность использования параллельного сборщика, который собирает постоянные объекты одновременно во время работы приложения.
Примечание. Ожидайте паузы порядка от одной до пяти секунд на ГБ оперативных данных на современном оборудовании, в то время как старое поколение сжато.
Примечание. Иногда параллельный сборщик может получить выигрыш в производительности от -XX: + UseNUMA в приложениях с несколькими сокетами на процессорных серверах, выделяя память Eden для потоков, локальных для сокета процессора. Обидно, эта функция недоступна другим коллекционерам.
Concurrent Mark Sweep (CMS) Collector
Сборщик CMS (-XX: + UseConcMarkSweepGC) работает в старом поколении, собирая постоянные объекты, которые более недоступны во время основной коллекции. Он работает одновременно с приложением с целью сохранения достаточного свободного места в старом поколении, чтобы не происходил сбой при продвижении по службе у молодого поколения.
Сбой продвижения активирует FullGC. CMS выполняет многоэтапный процесс:
- Начальная отметка : найти корни GC.
- Одновременная отметка : отметьте все достижимые объекты из корней GC.
- Параллельная предварительная очистка : проверьте наличие ссылок на объекты, которые были обновлены, и объектов, которые были продвинуты на этапе одновременной пометки путем пометки.
- Пометка : захват ссылок на объекты, которые были обновлены с этапа предварительной очистки.
- Concurrent Sweep : Обновите свободные списки, освободив память, занятую мертвыми объектами.
- Параллельный сброс : Сброс структур данных для следующего запуска.
По мере того как находящиеся в собственности объекты становятся недоступными, пространство освобождается CMS и помещается в свободные списки. Когда происходит продвижение, в свободных списках нужно искать подходящее по размеру отверстие для продвигаемого объекта. Это увеличивает стоимость продвижения и, следовательно, увеличивает стоимость незначительных коллекций по сравнению с параллельным сборщиком.
Примечание : CMS не является компактным сборщиком, который со временем может привести к фрагментации старого поколения. Продвижение объекта может закончиться неудачей, поскольку крупный объект может не вписаться в доступные дыры старого поколения. Когда это происходит, регистрируется сообщение о том, что продвижение не выполнено, и запускается FullGC, чтобы сжать живые арендованные объекты. Для таких FullGC, управляемых уплотнением, ожидайте, что паузы будут хуже, чем в основных коллекциях, использующих сборщик Parallel Old, потому что CMS использует только один поток для сжатия.
CMS в основном работает с приложением, что имеет ряд последствий. Во-первых, сборщик тратит время ЦП, тем самым уменьшая ЦП, доступный для приложения. Количество времени, требуемое CMS, растет линейно с количеством продвижения объекта в арендованное пространство. Во-вторых, для некоторых фаз параллельного цикла GC все потоки приложения должны быть приведены в безопасную точку для маркировки корней GC и выполнения параллельной перемаркировки для проверки на наличие мутаций.
Примечание . Если приложение видит значительную мутацию постоянных объектов, то фаза перемаркировки может быть значительной, в крайних случаях это может занять больше времени, чем полное уплотнение с помощью сборщика Parallel Old.
CMS делает FullGC менее частым событием за счет снижения пропускной способности, более дорогих второстепенных сборов и увеличения занимаемой площади. Снижение пропускной способности может составлять от 10% до 40% по сравнению с параллельным коллектором, в зависимости от уровня продвижения. CMS также требует увеличения занимаемой площади на 20% для размещения дополнительных структур данных и «плавающего мусора», который может быть пропущен во время одновременной маркировки, которая переносится на следующий цикл.
Высокие темпы продвижения и, как следствие, фрагментация иногда могут быть уменьшены за счет увеличения площадей как молодого, так и старого поколения.
Примечание : CMS может страдать от « одновременных сбоев режима », которые можно увидеть в журналах, когда он не может собрать с достаточной скоростью, чтобы не отставать от продвижения. Это может быть вызвано тем, что сбор начинается слишком поздно, что иногда можно устранить с помощью настройки. Но это также может произойти, когда скорость сбора не может соответствовать высокой скорости продвижения или высокой скорости мутации объектов в некоторых приложениях. Если уровень продвижения или мутации приложения слишком высок, тогда вашему приложению могут потребоваться некоторые изменения, чтобы уменьшить давление продвижения. Добавление большего объема памяти в такую систему может иногда усугубить ситуацию, так как тогда CMS будет иметь больше памяти для сканирования.
Сборщик мусора первый (G1)
G1 (-XX: + UseG1GC) — это новый сборщик, представленный в Java 6 и официально поддерживаемый начиная с Java 7u4. Это частично параллельный алгоритм сбора данных, который также пытается сжимать постоянное пространство в меньшие инкрементальные паузы остановки мира, чтобы попытаться минимизировать события FullGC, которые изводят CMS из-за фрагментации. G1 — это сборщик поколений, который организовывает кучу иначе, чем другие сборщики, разделяя ее на большое количество (~ 2000) областей фиксированного размера переменного назначения, а не смежных областей для той же цели.
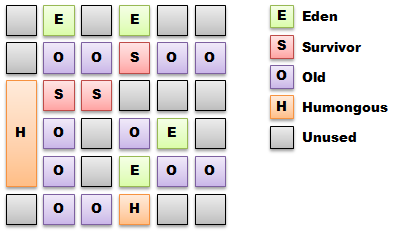
G1 использует подход одновременной маркировки регионов для отслеживания ссылок между регионами и сосредоточения сбора на регионах с наибольшим количеством свободного места. Затем эти регионы собираются с приращением «остановка мира» путем эвакуации живых объектов в пустую область, тем самым уплотняясь в процессе. Области, которые должны быть собраны в цикле, называются Набором сбора .
Объекты размером более 50% области расположены в огромных областях, которые кратны размеру области. Выделение и сбор огромных объектов может быть очень дорогостоящим в рамках G1, и на сегодняшний день усилия по оптимизации практически не применялись.
Задача любого компактного сборщика — не перемещение объектов, а обновление ссылок на эти объекты. Если на объект ссылаются из многих регионов, то обновление этих ссылок может занять значительно больше времени, чем перемещение объекта. G1 отслеживает, какие объекты в регионе имеют ссылки из других регионов через « Запомненные наборы ». Наборы «Помни» — это наборы карточек, помеченных для мутации. Если запомненные наборы становятся большими, G1 может значительно замедлиться. При эвакуации объектов из одного региона в другой, длина соответствующего события остановки мира имеет тенденцию быть пропорциональной количеству регионов со ссылками, которые необходимо отсканировать и потенциально исправить.
Поддержание запомненных наборов увеличивает стоимость небольших коллекций, в результате чего паузы становятся больше, чем те, которые наблюдаются при использовании сборщиков Parallel Old или CMS для небольших коллекций.
G1 является целевым объектом с задержкой –XX: MaxGCPauseMillis = <n>, значение по умолчанию = 200 мс. Цель будет влиять на объем работы, выполняемой в каждом цикле, только на основе наилучших усилий. Установка целей в десятки миллисекунд в основном бесполезна, и на момент написания этой статьи нацеливание на десятки миллисекунд не было целью G1.
G1 — хороший универсальный сборщик для больших куч, которые имеют тенденцию становиться фрагментированными, когда приложение может допускать паузы в диапазоне 0,5-1,0 секунды для инкрементных сжатий. G1 имеет тенденцию уменьшать частоту пауз наихудшего случая, наблюдаемых CMS, из-за фрагментации за счет расширенных незначительных сборов и дополнительных уплотнений старого поколения. Большинство пауз в конечном итоге ограничивается региональным, а не полным уплотнением кучи.
Как и CMS, G1 также может не поспевать за темпами продвижения по службе и откатится к «полной остановке мира». Подобно тому, как CMS имеет « сбой одновременного режима », G1 может страдать от сбоя при эвакуации, который в журналах рассматривается как « переполнение пространства ». Это происходит, когда нет свободных областей, в которые можно эвакуировать объекты, что аналогично неудаче продвижения. Если это происходит, попробуйте использовать большую кучу и большее количество потоков разметки, но в некоторых случаях могут потребоваться изменения в приложениях для снижения скорости выделения.
Сложной проблемой для G1 является работа с популярными объектами и регионами. Инкрементальное уплотнение «останови мир» работает хорошо, когда в регионах есть живые объекты, на которые нет сильных ссылок из других регионов. Если объект или область популярны, то Запомненный набор будет большим, и G1 попытается избежать сбора этих объектов. В конце концов, у него не может быть выбора, что приводит к очень частым паузам средней длины, когда куча уплотняется.
Альтернативные Параллельные Коллекторы
CMS и G1 часто называют в основном параллельными коллекторами. Когда вы смотрите на всю выполненную работу, становится ясно, что молодое поколение, продвижение по службе и даже большая часть работы старого поколения не совпадают вообще. CMS в основном работает одновременно для старого поколения; G1 — гораздо больше инкрементального инкрементального коллектора. Как CMS, так и G1 имеют значительные и регулярно происходящие события остановки мира, а также сценарии наихудшего случая, которые часто делают их непригодными для приложений со строгими задержками, таких как финансовые торговые или реагирующие пользовательские интерфейсы.
Доступны альтернативные сборщики, такие как Oracle JRockit Real Time, IBM Websphere Real Time и Azul Zing. Коллекторы JRockit и Websphere в большинстве случаев имеют преимущества по сравнению с CMS и G1, но часто сталкиваются с ограничениями пропускной способности и по-прежнему страдают от значительных событий остановки мира. Zing — единственный собиратель Java, известный этому автору, который может быть действительно параллельным для сбора и сжатия, поддерживая высокую пропускную способность для всех поколений. У Zing есть некоторые события остановки мира на доли миллисекунды, но они предназначены для фазовых сдвигов в цикле сбора, которые не связаны с размером набора живых объектов.
JRockit RT может достичь типичного времени паузы в десятки миллисекунд для высоких скоростей выделения при ограниченных размерах кучи, но иногда приходится возвращаться к паузам полного сжатия. Websphere RT может достигать времени паузы в одну цифру в миллисекундах благодаря ограниченным скоростям распределения и размеру реального набора. Zing может достигать паузы менее миллисекунды с высокой скоростью выделения, будучи параллельным для всех фаз, в том числе во время незначительных сборов. Zing может поддерживать это непротиворечивое поведение независимо от размера кучи, что позволяет пользователю применять большие размеры кучи по мере необходимости для соответствия требованиям к пропускной способности приложения или состоянию объектной модели, не опасаясь увеличения времени паузы.
Для всех одновременных сборщиков, нацеленных на задержку, вы должны отказаться от некоторой пропускной способности и увеличить площадь. В зависимости от эффективности параллельного коллектора вы можете отказаться от небольшой пропускной способности, но вы всегда добавляете значительную площадь. Если он действительно параллельный, с несколькими событиями остановки мира, тогда требуется больше ядер ЦП для обеспечения одновременной работы и поддержания пропускной способности.
Примечание. Все параллельные коллекторы, как правило, работают более эффективно при выделении достаточного пространства. В качестве начального практического правила для эффективной работы вы должны выделить как минимум в два-три раза кучу динамического набора. Однако требования к пространству для поддержки одновременной работы возрастают с увеличением пропускной способности приложений и связанных с ними скоростей выделения и продвижения. Таким образом, для приложений с более высокой пропускной способностью может быть оправдано более высокое отношение размера кучи к действующему набору. Учитывая наличие огромного пространства памяти, доступного современным системным системам, на стороне сервера редко возникает проблема.
Мониторинг и настройка сбора мусора
Чтобы понять, как работают ваше приложение и сборщик мусора, запустите JVM по крайней мере со следующими настройками:
|
1
2
3
4
5
6
7
|
-verbose:gc-Xloggc:-XX:+PrintGCDetails-XX:+PrintGCDateStamps-XX:+PrintTenuringDistribution-XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCApplicationStoppedTime |
Затем загрузите журналы в инструмент, такой как Chewiebug для анализа.
Чтобы увидеть динамическую природу GC, запустите JVisualVM и установите плагин Visual GC. Это позволит вам увидеть GC в действии для вашего приложения, как показано ниже.
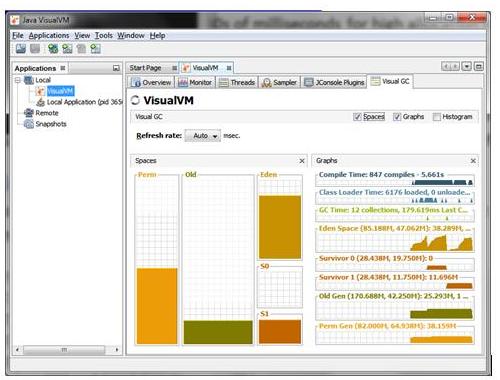
Чтобы понять потребности GC ваших приложений, вам нужны репрезентативные нагрузочные тесты, которые могут выполняться неоднократно. Когда вы поймете, как работает каждый из коллекторов, запустите нагрузочные тесты с различными конфигурациями в качестве экспериментов, пока не достигнете целевых показателей пропускной способности и задержки. Важно измерить задержку с точки зрения конечного пользователя. Это может быть достигнуто путем записи времени ответа каждого тестового запроса в гистограмме, и вы можете прочитать об этом здесь. Если у вас есть пики задержки, которые находятся за пределами допустимого диапазона, попробуйте соотнести их с журналами GC, чтобы определить, является ли GC проблемой. Возможно, другие проблемы могут быть причиной всплесков задержки. Еще один полезный инструмент для рассмотрения — это jHiccup, который можно использовать для отслеживания пауз в JVM и в системе в целом. С помощью jHiccup измерьте несколько часов бездействия, и вы часто будете очень удивлены.
Если пики задержки обусловлены GC, тогда инвестируйте в настройку CMS или G1, чтобы увидеть, могут ли ваши цели задержки быть достигнуты. Иногда это может оказаться невозможным из-за высоких показателей распределения и продвижения в сочетании с требованиями с низкой задержкой. Настройка ГХ может стать высококвалифицированным упражнением, которое часто требует изменений в приложениях для уменьшения скорости выделения объектов или времени жизни объектов. Если это так, то может потребоваться коммерческий компромисс между временем и ресурсами, затраченными на настройку ГХ, и изменениями приложения, например, покупка одной из коммерческих одновременных компактных JVM, таких как JRockit Real Time или Azul Zing.