Эта статья является частью нашего академического курса под названием Apache Lucene Fundamentals .
В этом курсе вы познакомитесь с Lucene. Вы поймете, почему такая библиотека важна, а затем узнаете, как работает поиск в Lucene. Кроме того, вы узнаете, как интегрировать Lucene Search в ваши собственные приложения, чтобы обеспечить надежные возможности поиска. Проверьте это здесь !
Содержание
1. Введение
Анализ в Lucene — это процесс преобразования текста поля в его наиболее фундаментальное индексированное представление — термины. В общем, токены называются анализаторами словами (мы обсуждаем эту тему только на английском языке). Однако для специальных анализаторов токен может содержать более одного слова, включая пробелы. Эти термины используются для определения того, какие документы соответствуют запросу во время поиска. Например, если вы проиндексировали это предложение в поле, термины могут начинаться с for и, например, и так далее, как отдельные термины в последовательности. Анализатор — это инкапсуляция процесса анализа. Анализатор выполняет токенизацию текста, выполняя любое количество операций над ним, которые могут включать в себя извлечение слов, удаление знаков препинания, удаление акцентов в символах, нижний регистр (также называемый нормализацией), удаление общих слов, приведение слов к корневой форме (основание) или изменение слова в основной форме (лемматизация). Этот процесс также называется токенизацией, а фрагменты текста, извлеченные из потока текста, называются токенами. Токены в сочетании с соответствующим именем поля являются терминами.
2. Использование анализаторов
Основная цель Lucene — облегчить поиск информации. Акцент на поиске важен. Вы хотите бросить кусочки текста в Lucene и сделать так, чтобы они были доступны для поиска по отдельным словам в этом тексте. Чтобы Lucene узнал, что такое «слова», он анализирует текст во время индексации, извлекая его в термины. Эти термины являются примитивными строительными блоками для поиска.
Выбор правильного анализатора является решающим решением для разработки с Lucene, и один размер определенно не подходит для всех. Язык является одним из факторов, потому что у каждого есть свои уникальные особенности. Другим фактором, который следует учитывать, является область анализируемого текста; различные отрасли имеют различную терминологию, аббревиатуры и сокращения, которые могут заслуживать внимания. Ни один анализатор не подойдет для всех ситуаций. Возможно, что ни один из встроенных вариантов анализа не будет соответствовать нашим потребностям, и нам придется инвестировать в создание специального решения для анализа; к счастью, строительные блоки Lucene делают это довольно легко.
В целом, анализаторы Lucene разработаны с использованием следующих шагов:
Фактический текст -> Основная подготовка токена -> фильтрация нижнего регистра -> фильтрация стоп-слов (отрицание не очень полезных слов, которые составляют 40-50% слов в содержании) -> Фильтрация по пользовательской логике -> Окончательная подготовка токена для индексации в lucene, на которую будут ссылаться при поиске lucene.
Разные анализаторы используют разные токенизаторы и на основании этого выходные потоки токенов — последовательности группы текста будут разными.
Стеммеры используются, чтобы получить корень рассматриваемого слова. Например, для слов «бег», «беги», «беги» и т. Д. Будет выполняться корневое слово. Эта функция используется в анализаторах для увеличения области поиска в контенте по API поиска. Если корневое слово упоминается в индексе, то может быть для точного слова, мы можем иметь более одного параметра в индексе для поиска, и вероятность совпадения фразы может быть выше. Таким образом, эта концепция, называемая стеммерами, часто используется в конструкции анализатора.
Стоп-слова являются частыми, менее полезными словами в письменном языке. Для английского языка это слова «а», «я» и т. Д.
В разных анализаторах потоки токенов очищаются от стоп-слов, чтобы сделать индекс более полезным для результатов поиска.
2.1. Рабочий процесс Lucene Analyzer
Процесс анализа состоит из трех частей. Чтобы проиллюстрировать процесс, мы будем использовать следующий необработанный текст в качестве примера. (Обработка документа HTML или PDF для получения заголовка, основного текста и других анализируемых полей называется синтаксическим анализом и выходит за рамки анализа. Предположим, анализатор уже извлек этот текст из документа большего размера.)
|
1
|
<h1>Building a <em>top-notch</em> search engine</h1> |
Во-первых, символьные фильтры предварительно обрабатывают необработанный текст для анализа. Например, символьный фильтр HTML Strip удаляет HTML. Теперь мы остались с этим текстом:
|
1
|
Building a top-notch search engine |
Затем токенизатор разбивает предварительно обработанный текст на токены. Токены обычно являются словами, но разные токенизаторы по-разному обрабатывают угловые регистры, такие как «первосортный». Некоторые токенизаторы, такие как стандартный токенизатор, рассматривают тире как границы слов, поэтому «первосортным» может быть два токена («верхний» и «меточный»). Другие токенайзеры, такие как токенайзер Whitespace, рассматривают только пробелы как границы слов, поэтому «первосортным» будет один токен. Есть также некоторые необычные токенизаторы, такие как токенайзер NGram, который генерирует токены, которые являются частичными словами.
Предполагая, что тире считается границей слова, теперь мы имеем:
Наконец, фильтры токенов выполняют дополнительную обработку токенов, например, удаляют суффиксы (называемые основанием) и преобразуют символы в нижний регистр. Окончательная последовательность токенов может выглядеть так:
Комбинация токенизатора и ноля или более фильтров составляет анализатор. Стандартный анализатор, который состоит из стандартного токенайзера и стандартных, строчных и стоп-фильтров, используется по умолчанию.
Анализаторы могут выполнять более сложные манипуляции для достижения лучших результатов. Например, анализатор может использовать токен-фильтр для проверки правописания слов или ввести синонимы, чтобы при поиске «saerch» или «find» возвращался документ, содержащий «Searching». Существуют также различные реализации похожих функций на выбор.
В дополнение к выбору между включенными анализаторами, мы можем создать собственный настраиваемый анализатор, связав воедино существующий токенизатор и ноль или более фильтров. В стандартном анализаторе стволовых данных нет, поэтому вы можете создать собственный анализатор, который включает в себя фильтр жетонов стволовых элементов.
Имея так много возможностей, мы можем протестировать различные комбинации и посмотреть, что лучше всего подходит для нашей ситуации.
3. Типы анализаторов
В Lucene есть несколько различных анализаторов:
а. Анализатор пробелов
Анализатор пробелов обрабатывает текст в токены на основе пробелов. Все символы между пробелами индексируются. Здесь, стоп-слова не используются для анализа, и регистры букв не изменяются. Анализатор пробелов строится с использованием токенайзера пробелов (токенайзер типа пробелов, который делит текст на пробелы).
б. SimpleAnalyser
SimpleAnalyser использует токенайзер букв и фильтрацию нижних регистров для извлечения токенов из содержимого и помещения их в индексирование lucene. Простой анализатор построен с использованием нижнего регистра Tokenizer. Токенайзер строчных букв выполняет функцию токенайзера букв и фильтра токенов строчных букв вместе. Он делит текст не на буквы и преобразует их в нижний регистр. Хотя это функционально эквивалентно комбинации Letter Tokenizer и Lower Case Token Filter, существует преимущество в производительности для выполнения двух задач одновременно, отсюда и эта (избыточная) реализация.
с. StopAnalyzer
StopAnalyser удаляет обычные английские слова, которые не очень полезны для индексации. Это достигается путем предоставления анализатору списка списков STOP_WORDS.
Анализатор останова построен с использованием токенайзера нижнего регистра с фильтром токенов остановки (фильтр токенов типа stop, который удаляет стоп-слова из потоков токенов)
Ниже приведены настройки, которые можно установить для типа анализатора остановки:
- stopwords -> список стоп-слов для инициализации фильтра stop. По умолчанию используются английские стоп-слова.
- stopwords_path -> Путь (относительно расположения конфигурации или абсолютный) к конфигурации файла стоп-слов.
д. StandardAnalyzer
StandardAnalyser — это анализатор общего назначения. Обычно он преобразует токены в строчные буквы, используя стандартные стоп-слова для анализа текстов, а также руководствуется другими правилами. StandardAnalyzer построен с использованием стандартного токенайзера со стандартным фильтром токенов (фильтр токенов стандартного типа, который нормализует токены, извлеченные с помощью стандартного токенизатора), строчный фильтр токенов и фильтр стоп-токенов.
е. ClassicAnalyzer
Анализатор, который фильтрует ClassicTokenizer с ClassicFilter, LowerCaseFilter и StopFilter, используя список английских стоп-слов.
е. UAX29URLEmailAnalyzer
Анализатор, который фильтрует UAX29URLEmailTokenizer с помощью StandardFilter, LowerCaseFilter и StopFilter, используя список английских стоп-слов.
грамм. Анализатор ключевых слов
Анализатор типа ключевого слова, который «токенизирует» весь поток как один токен. Это полезно для данных, таких как почтовые индексы, идентификаторы и так далее. Обратите внимание, что при использовании определений сопоставления может иметь смысл просто пометить поле как not_analyzed.
час Снежный ком анализатор
Анализатор типа «снежный ком», в котором используется стандартный токенизатор со стандартным фильтром, строчным фильтром, стоп-фильтром и фильтром снежного кома.
Snowball Analyzer — это анализатор стволов из Lucene, который изначально основан на проекте снежного кома из snowball.tartarus.org.
Пример использования:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
{ "index" : { "analysis" : { "analyzer" : { "my_analyzer" : { "type" : "snowball", "language" : "English" } } } }} |
я. Анализатор паттернов
Анализатор типа шаблона, который может гибко разделять текст на термины с помощью регулярного выражения. Принимает следующие настройки:
Пример анализатора паттернов:
Токенайзер пробельных символов:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
curl -XPUT 'localhost:9200/test' -d '{ "settings":{ "analysis": { "analyzer": { "whitespace":{ "type": "pattern", "pattern":"\\\\\\\\s+" } } } }} |
|
1
2
3
|
curl 'localhost:9200/test/_analyze?pretty=1&analyzer=whitespace' -d 'foo,bar baz' # "foo,bar", "baz" |
токенайзер несловесных символов:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
curl -XPUT 'localhost:9200/test' -d '{ "settings":{ "analysis": { "analyzer": { "nonword":{ "type": "pattern", "pattern":"[^\\\\\\\\w]+" } } } }} |
|
1
2
3
|
curl 'localhost:9200/test/_analyze?pretty=1&analyzer=nonword' -d 'foo,bar baz'</strong># "foo,bar baz" becomes "foo", "bar", "baz" |
|
1
2
3
|
curl 'localhost:9200/test/_analyze?pretty=1&analyzer=nonword' -d 'type_1-type_4'</strong># "type_1","type_4" |
жетон верблюд:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
curl -XPUT 'localhost:9200/test?pretty=1' -d '{ "settings":{ "analysis": { "analyzer": { "camel":{ "type": "pattern", "pattern":"([^\\\\\\\\p{L}\\\\\\\\d]+)|(?<=\\\\\\\\D)(?=\\\\\\\\d)|(?<=\\\\\\\\d)(?=\\\\\\\\D)|(?<=[\\\\\\\\p{L}&&[^\\\\\\\\p{Lu}]])(?=\\\\\\\\p{Lu})|(?<=\\\\\\\\p{Lu})(?=\\\\\\\\p{Lu}[\\\\\\\\p{L}&&[^\\\\\\\\p{Lu}]])" } } } }} |
|
1
2
3
4
5
6
7
|
curl 'localhost:9200/test/_analyze?pretty=1&analyzer=camel' -d ' MooseX::FTPClass2_beta'# "moose","x","ftp","class","2","beta" |
Выражение выше легче понять как:
| ([^ \\ р {L} \\ д] +) | # глотать не буквы и цифры, |
| | (? <= \\ D) (? = \\ г) | # или не номер, за которым следует номер, |
| | (? <= \\ г) (? = \\ D) | № или номер, за которым следует номер, |
| | (? <= [\\ p {L} && [^ \\ p {Lu}]]) | # или нижний регистр |
| (? = \\ р {Л}) | # сопровождается заглавными буквами, |
| | (? <= \\ р {Л}) | # или верхний регистр |
| (? = \\ р {Л} | # сопровождается заглавными буквами |
| [\\ р {Ь} && [^ \\ р {Лу}]] | # тогда строчные |
Таблица 1
к. Пользовательский анализатор
Анализатор пользовательского типа, позволяющий комбинировать токенизатор с нулем или несколькими фильтрами токенов и нулем или несколькими фильтрами символов. Пользовательский анализатор принимает логическое / зарегистрированное имя токенайзера для использования и список логических / зарегистрированных имен токен-фильтров.
Вот пример пользовательского анализатора:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
index : analysis : analyzer : myAnalyzer2 : type : custom tokenizer : myTokenizer1 filter : [myTokenFilter1, myTokenFilter2] char_filter : [my_html] tokenizer : myTokenizer1 : type : standard max_token_length : 900 filter : myTokenFilter1 : type : stop stopwords : [stop1, stop2, stop3, stop4] myTokenFilter2 : type : length min : 0 max : 2000 char_filter : my_html : type : html_strip escaped_tags : [xxx, yyy] read_ahead : 1024 |
Параметр language может иметь те же значения, что и фильтр снежного кома, и по умолчанию используется английский язык. Обратите внимание, что не во всех языковых анализаторах по умолчанию предоставляется набор стоп-слов.
Параметр stopwords может использоваться для предоставления стоп-слов для языков, которые не имеют значений по умолчанию, или просто для замены набора по умолчанию на ваш пользовательский список. Проверьте Stop Analyzer для более подробной информации. Набор стоп-слов по умолчанию для многих из этих языков доступен, например, здесь и здесь.
Пример конфигурации (в формате YAML) с указанием шведского языка со стоп-словами:
|
1
2
3
4
5
6
7
|
index : analysis : analyzer : my_analyzer: type: snowball language: Swedish stopwords: "och,det,att,i,en,jag,hon,som,han,på,den,med,var,sig,för,så,till,är,men,ett,om,hade,de,av,icke,mig,du,henne,då,sin,nu,har,inte,hans,honom,skulle,hennes,där,min,man,ej,vid,kunde,något,från,ut,när,efter,upp,vi,dem,vara,vad,över,än,dig,kan,sina,här,ha,mot,alla,under,någon,allt,mycket,sedan,ju,denna,själv,detta,åt,utan,varit,hur,ingen,mitt,ni,bli,blev,oss,din,dessa,några,deras,blir,mina,samma,vilken,er,sådan,vår,blivit,dess,inom,mellan,sådant,varför,varje,vilka,ditt,vem,vilket,sitta,sådana,vart,dina,vars,vårt,våra,ert,era,vilkas" |
Вот пример пользовательского анализатора строк, который построен путем расширения абстрактного класса Lucene Analyzer. В следующем листинге показан SampleStringAnalyzer, который реализует метод tokenStream(String,Reader) . SampleStringAnalyzer определяет набор стоп-слов, которые можно отбрасывать в процессе индексации, используя StopFilter, предоставленный Lucene. Метод tokenStream проверяет индексируемое поле. Если поле является комментарием, оно сначала вводит токены и вводит строчные буквы с использованием LowerCaseTokenizer, удаляет стоп-слова английского языка (ограниченный набор английских стоп-слов) с помощью StopFilter и использует PorterStemFilter для удаления общих морфологических и инфлексионных окончаний. Если индексируемое содержимое не является комментарием, анализатор использует токены и вводит строчные буквы с использованием LowerCaseTokenizer и удаляет ключевые слова Java с помощью StopFilter.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
public class SampleStringAnalyzer extends Analyzer { private Set specialStopSet; private Set englishStopSet; private static final String[] SPECIALWORD_STOP_WORDS = { "abstract","implements","extends","null""new", "switch","case", "default" ,"synchronized" , "do", "if", "else", "break","continue","this", "assert" ,"for", "transient", "final", "static","catch","try", "throws","throw","class", "finally","return", "const" , "native", "super","while", "import", "package" ,"true", "false" }; private static final String[] ENGLISH_STOP_WORDS ={ "a", "an", "and", "are","as","at","be" "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "s", "such", "that", "the", "their", "then", "there","these", "they", "this", "to", "was", "will", "with" }; public SourceCodeAnalyzer(){ super(); specialStopSet = StopFilter.makeStopSet(SPECIALWORD_STOP_WORDS); englishStopSet = StopFilter.makeStopSet(ENGLISH_STOP_WORDS); } public TokenStream tokenStream(String fieldName, Reader reader) { if (fieldName.equals("comment")) return new PorterStemFilter( new StopFilter( new LowerCaseTokenizer(reader),englishStopSet)); else return new StopFilter( new LowerCaseTokenizer(reader),specialStopSet); } }} |
Что внутри анализатора?
Анализаторы должны возвращать TokenStream
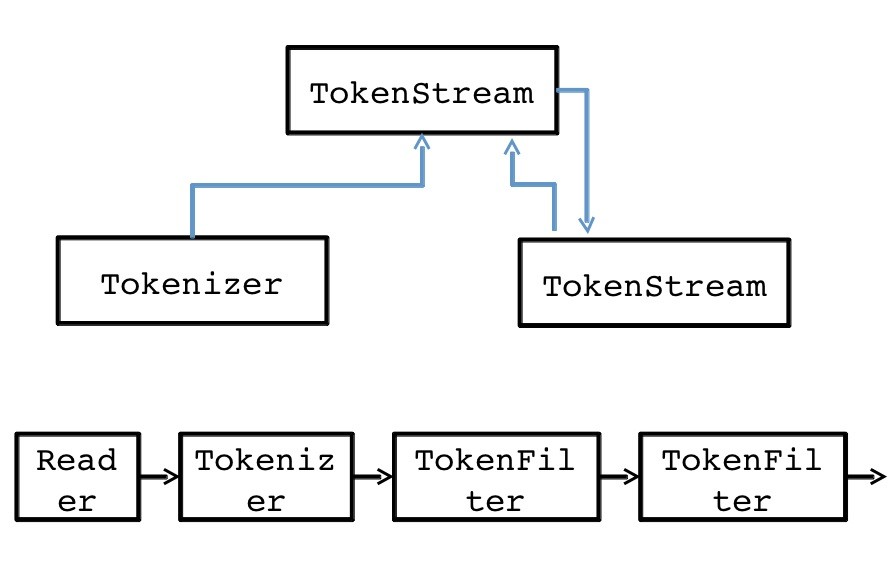
фигура 1
Анализ текста в токены:
Поиск и индексация по текстовым полям требует обработки текстовых данных в токены. Пакет oal.analysis содержит базовые классы для токенизации и индексации текста. Обработка может состоять из последовательности преобразований, например, токенизации пустого пространства, нормализации регистра, стоп-листинга и стволового кода.
Абстрактный класс oal.analysis.TokenStream разбивает входящий текст на последовательность токенов, которые извлекаются с использованием шаблона, подобного итератору. TokenStream имеет два подкласса: oal.analysis.Tokenizer и oal.analysis.TokenFilter . Tokenizer принимает java.io.Reader качестве входных данных, тогда как TokenFilter принимает другой oal.analysis.TokenStream в качестве входных данных. Это позволяет нам связывать вместе токенизаторы так, чтобы исходный токенизатор получал свой вход от считывателя, а другие работали с токенами из предыдущего TokenStream в цепочке.
oal.analysis.Analyzer предоставляет oal.analysis.Analyzer процессы индексирования и поиска для каждого поля отдельно. Он отображает имена полей на токенизаторы и может также предоставлять анализатор по умолчанию для неизвестных имен полей. Lucene включает в себя множество модулей анализа, которые обеспечивают конкретные реализации различных видов анализаторов. Начиная с Lucene 4, эти модули объединены в отдельные файлы jar. Существует несколько десятков пакетов анализа для конкретного языка, от oal.analysis.ar для арабского языка до oal.analysis.tr для турецкого. Пакет oal.analysis.core содержит несколько универсальных анализаторов, токенизаторов и классов фабрики токенизаторов.
Абстрактный класс oal.analysis.Analyzer содержит методы, используемые для извлечения терминов из входного текста. Конкретные подклассы Analyzer должны переопределить метод createComponents , который возвращает объект вложенного класса TokenStreamComponents который определяет процесс токенизации и обеспечивает доступ к начальным и файловым компонентам конвейера обработки. Начальным компонентом является Tokenizer, который обрабатывает входной источник. Последний компонент является экземпляром TokenFilter, и это TokenStream, возвращаемый методом Analyzer.tokenStream(String,Reader) . Ниже приведен пример пользовательского анализатора, который разбивает свои входные данные на отдельные слова со строчными буквами.
|
01
02
03
04
05
06
07
08
09
10
|
Analyzer analyzer = new Analyzer() { @Override protected TokenStreamComponents createComponents(String fieldName, Reader reader) { Tokenizer source = new StandardTokenizer(VERSION,reader); TokenStream filter = new LowerCaseFilter(VERSION,source); return new TokenStreamComponents(source, filter); }}; |
Конструкторам для объектов oal.analysis.standard.StandardTokenizer и oal.analysis.core.LowerCaseFilter требуется аргумент Version. Также обратите внимание, что пакет oal.analysis.standard распространяется в jarfile lucene-analyzers-common-4.xyjar, где x и y — младшая версия и номер выпуска.
Какой анализатор керна следует использовать?
Теперь мы увидели существенные различия в работе каждого из четырех основных анализаторов Lucene. Выбор правильного решения для нашего приложения удивляет нас: большинство приложений не используют встроенные анализаторы и предпочитают создавать собственную цепочку анализаторов. Для тех приложений, которые используют анализатор ядра, StandardAnalyzer, вероятно, является наиболее распространенным выбором. Остальные анализаторы ядра обычно слишком упрощены для большинства приложений, за исключением, возможно, конкретных случаев использования (например, поле, содержащее список номеров деталей, может использовать Whitespace-Analyzer). Но эти анализаторы отлично подходят для тестовых случаев и действительно активно используются в модульных тестах Lucene.
Как правило, у приложения есть особые потребности, такие как настройка списка стоп-слов, выполнение специальной токенизации для токенов, специфичных для приложения, таких как номера деталей или расширение синонимов, сохранение регистра для определенных токенов или выбор конкретного алгоритма стемминга.