Эта статья является частью нашего курса Academy под названием Redis — хранилище ключей NoSQL .
Это ускоренный курс по Redis. Вы узнаете, как установить Redis и запустить сервер. Кроме того, вы будете возиться с командной строкой Redis. Далее следуют более сложные темы, такие как репликация, сегментирование и кластеризация, а также объясняется интеграция Redis с Spring Data. Проверьте это здесь !
Содержание
1. Введение
Количество данных, с которыми мы имеем дело, растет экспоненциально с каждым днем. Очень часто мы сталкиваемся с аппаратными ограничениями для одного блока, когда необходимые данные не помещаются в памяти, и даже физической памяти больше не достаточно. С годами эти проблемы побудили индустрию разработать решения для разделения данных (или разделения данных), которые позволяют преодолеть такие ограничения.
В Redis разбиение данных (разбиение) — это метод разделения всех данных на несколько экземпляров Redis, чтобы каждый экземпляр содержал только подмножество ключей. Такой процесс позволяет уменьшить объем данных, добавляя все больше экземпляров и разделяя данные на более мелкие части (сегменты или разделы). Мало того, это также означает, что все больше вычислительных мощностей доступно для обработки ваших данных, эффективно поддерживая горизонтальное масштабирование.
Несмотря на то, что не все является беспроигрышным решением, необходимо учитывать компромиссы: при разделении данных на множество экземпляров возникает проблема поиска определенного ключа (или ключей). Вот здесь и возникает схема разделения (разбиения): данные должны быть разделены (разделены) в соответствии с некоторыми согласованными или фиксированными правилами, поэтому операции записи и чтения для одного и того же ключа должны передаваться экземпляру Redis, который содержит (владеет) этим ключом.
Материал этого руководства основан на превосходной документации Redis, связанной с разделением и разделением: http://redis.io/topics/partitioning.
2. Когда использовать шардинг (разбиение)
В соответствии с документацией Redis ( http://redis.io/topics/partitioning ) вы должны рассмотреть вопрос о разбиении (разбиении) ваших данных, если вы хотите:
- управлять гораздо большими базами данных, используя память многих компьютеров (иначе вы ограничены объемом памяти, который может поддерживать один компьютер)
- масштабировать вычислительную мощность между несколькими процессорами, несколькими компьютерами и использовать их пропускную способность сети
Если вы считаете, что у вас нет проблемы с масштабированием данных сейчас, возможно, она возникнет в самом ближайшем будущем, поэтому лучше подготовиться и подумать об этом заранее (см. « Планирование разбиения (разбиение)» ). Но перед этим, пожалуйста, примите во внимание сложности и недостатки, которые шардинг (разбиение) ставит на стол:
- Операции с несколькими ключами обычно не поддерживаются. Например, невозможно напрямую выполнить пересечение между двумя наборами (
SINTER), если они хранятся в ключах, которые сопоставлены с различными экземплярами Redis. - Транзакции с участием нескольких ключей, сопоставленных с различными экземплярами Redis, невозможны.
- Разделение основано на ключах, поэтому невозможно разделить (разделить) набор данных на один огромный ключ (очень большой отсортированный набор или список).
- Резервное копирование и постоянное управление намного сложнее: вам приходится иметь дело с несколькими файлами RDB / AOF, резервное копирование включает в себя объединение (слияние) файлов RDB из многих экземпляров.
- Добавление и удаление экземпляров во время выполнения может привести к дисбалансу данных, если вы не запланировали это (см. Раздел «Планирование разделения (разбиение)» ).
3. Схемы разбиения (разбиения)
Существует несколько проверенных схем разделения (разбиения), которые можно использовать с Redis, в зависимости от ваших шаблонов данных.
- разделение диапазона
Это достигается путем сопоставления диапазонов объектов в конкретные экземпляры Redis. Например, предположим, что мы храним некоторые пользовательские данные, и у каждого пользователя есть свой уникальный идентификатор (ID). В нашей схеме секционирования мы могли бы определить, что пользователи с идентификатором от 0 до 10000 перейдут в экземпляр Redis 1, а пользователи с идентификатором от 10001 до 20000 — в экземпляр Redis 2 и т. Д. Недостаток этой схемы заключается в том, что необходимо поддерживать отображение между диапазонами и экземплярами, и таких сопоставлений должно быть столько же, сколько видов объектов (пользователей, продуктов,…), которые хранятся в Redis. - разбиение хэша
Эта схема работает для любого ключа, но включает хеш-функцию : эта функция должна сопоставить имя ключа с некоторым числом. Предполагая, что у нас есть такая функция (назовем ееhash_func), такая схема работает так:- взять имя ключа и сопоставить его с числом, используя
hash_func - отобразить полученный номер в экземпляр Redis (например, используя операцию деления на модуль)
Выбор хеш-функции очень важен. Хорошая хеш-функция гарантирует, что ключи распределены равномерно по всем экземплярам Redis, поэтому она не создает слишком много на любом отдельном экземпляре.
- взять имя ключа и сопоставить его с числом, используя
- последовательное хеширование
Это расширенная формаhash partitioning, широко используемая многими решениями для разделения данных (разбиения).
4. Разделение (разбиение) реализаций
С точки зрения реализации существует несколько возможных реализаций для разделения (разбиения) данных в зависимости от архитектуры приложения:
- разделение на стороне клиента
Клиенты напрямую выбирают правильный экземпляр для записи или чтения заданного ключа. - разделение с помощью прокси
Клиенты отправляют запросы на прокси-сервер, поддерживающий протокол Redis, вместо того, чтобы отправлять запросы прямо в нужные экземпляры Redis. Прокси-сервер обязательно перенаправит запросы нужным экземплярам Redis в соответствии с настроенной схемой разделения и отправит ответы обратно клиентам (наиболее известная реализация —Twemproxyиз Twitter, https://github.com/twitter/ twemproxy ). - маршрутизация запросов
Клиенты отправляют запрос случайному экземпляру Redis, и этот экземпляр обязательно перенаправит запрос нужному экземпляру. Гибридная форма маршрутизации запросов предполагает, что клиент перенаправляется на нужный экземпляр (но запрос не перенаправляется напрямую из одного экземпляра Redis в другой) и будет описан в части 5 руководства Redis Clustering .
5. Планирование шардинга (разбиения)
Как мы упоминали ранее, после того, как вы начнете использовать разбиение данных (разбиение) во многих экземплярах Redis, добавление и удаление экземпляров во время выполнения может быть затруднено. Один метод, который вы часто можете использовать с Redis, называется Presharding ( http://redis.io/topics/partitioning ).
Идея предварительной защиты состоит в том, чтобы начать с большого количества экземпляров с самого начала (но иметь одно или очень небольшое количество реальных узлов / серверов). Количество экземпляров может варьироваться и может быть довольно большим с самого начала (32 или 64 экземпляра может быть достаточно для большинства случаев использования). Вполне возможно иметь 64 экземпляра Redis, работающих на одном сервере, так как Redis чрезвычайно легок.
Таким образом, по мере роста потребности в хранилище данных и необходимости в большем количестве узлов / серверов Redis, можно просто перемещать экземпляры с одного сервера на другой. Например, если у вас есть один сервер и вы добавили дополнительный, половина экземпляров Redis с первого сервера должна быть перемещена на второй. Этот прием может продолжаться вплоть до того момента, когда у вас будет один экземпляр Redis на сервер / узел.
Однако следует помнить одну вещь: если вы используете Redis как кэш-память для своих данных (а не как постоянное хранилище данных), вам может не потребоваться предварительная защита. Согласованные реализации хеширования часто могут обрабатывать новые или удаленные экземпляры во время выполнения. Например, если предпочтительный экземпляр для данного ключа недоступен, ключ будет выбран другими экземплярами. Или, если вы добавите новый экземпляр, часть новых ключей будет сохранена в этом новом экземпляре.
6. Осколок (разбиение) и репликация
Разделение (разделение) данных на несколько экземпляров не решает проблему безопасности и избыточности данных. Если один из сегментов (разделов) умирает из-за аппаратного сбоя, и у вас нет резервной копии для восстановления данных, это означает, что вы потеряли свои данные навсегда.
Вот почему сегментирование (разбиение) идет параллельно с репликацией. Если вы используете Redis в качестве постоянного хранилища данных, рекомендуется создать хотя бы одну реплику для каждого сегмента (раздела) на другом сервере / узле. Это может удвоить ваши требования к емкости, но гораздо важнее обеспечить безопасность ваших данных.
Конфигурация для репликации ничем не отличается от того, что мы рассмотрели в части 3 руководства Redis Replication .
7. Раздробление (разбиение) с помощью Twemproxy
Twemproxy (также известный как « nutcracker ), разработанный и открытый исходным кодом Twitter ( https://github.com/twitter/twemproxy ), широко используется, очень быстрый и легкий прокси для Redis. Несмотря на то, что он имеет много функций, те, на которые мы собираемся взглянуть, связаны с его возможностью добавлять в Redis шардинг (разбиение):
- данные шарда автоматически на нескольких серверах
- поддерживает несколько режимов хеширования, включая согласованное хеширование и распределение
Twemproxy ( nutcracker ) довольно прост в установке и настройке. Последняя версия этого руководства — 0.3.0, которую можно загрузить с http://code.google.com/p/twemproxy/downloads/list . Установка довольно проста.
- Скачать
1
wget http://twemproxy.googlecode.com/files/nutcracker-0.3.0.tar.gz - Распакуйте архив
1
tarxfz nutcracker-0.3.0.tar.gz - Build (единственные предустановленные пакеты, которые вам нужны — это
gccиmake).123cdnutcracker-0.3.0./configuremake - устанавливать
1
sudomakeinstall
По умолчанию twemproxy ( nutcracker ) будет расположен в /usr/local/sbin/nutcracker . После его установки наиболее важной (но довольно простой) частью является ее конфигурация.
Twemproxy ( nutcracker ) использует YAML в качестве формата файла конфигурации ( http://www.yaml.org/ ). Среди множества настроек, поддерживаемых twemproxy ( nutcracker ), мы выберем те, которые относятся к шардингу (разбиению).
| настройка | слушай: имя: порт | IP: порт |
| Описание | Адрес прослушивания и порт ( name:port или ip:port ) для этого пула серверов. |
| пример | прослушать: 127.0.0.1:22121 |
Таблица 1
| настройка | хеш: <функция> |
| Описание | Имя хеш-функции. Возможные значения:
— один за раз — md5 ( http://en.wikipedia.org/wiki/MD5 ) — crc16 ( http://en.wikipedia.org/wiki/Cyclic_redundancy_check ) — crc32 (реализация crc32 совместима с libmemcached) — crc32a (правильная реализация crc32 согласно спецификации) — fnv1_64 ( http://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function ) — fnv1a_64 ( http://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function ) — fnv1_32 ( http://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function ) — fnv1a_32 ( http://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function ) — hsieh ( http://www.azillionmonkeys.com/qed/hash.html ) — ропот ( http://en.wikipedia.org/wiki/MurmurHash ) — Дженкинс ( http://en.wikipedia.org/wiki/Jenkins_hash_function ) |
| пример | hash: fnv1a_64 |
Таблица 2
| настройка | распространение: <режим> |
| Описание | Режим распространения ключей (см., Пожалуйста, http://en.wikipedia.org/wiki/Consistent_hashing ). Возможные значения:
— кетама — по модулю — случайный |
| пример | Распределение: кетама |
Таблица 3
| настройка | redis: true | false |
| Описание | Логическое значение, определяющее, говорит ли пул серверов протокол Redis или Memcached. Поскольку мы будем использовать только Redis, для этого параметра должно быть установлено значение true . По умолчанию false . |
| пример | Redis: правда |
Таблица 4
| настройка | auto_eject_hosts: true | ложный |
| Описание | Логическое значение, которое контролирует, должен ли сервер быть временно извлечен при последовательном сбое в работе server_failure_limit . По умолчанию false . |
| пример | auto_eject_hosts: false |
Таблица 5
| настройка | server_retry_timeout: <миллисекунды> |
| Описание | Значение времени ожидания в миллисекундах для ожидания перед повторной попыткой на временно auto_eject_host сервере, когда для auto_eject_host установлено значение true . По умолчанию 30000 миллисекунд. |
| пример | server_retry_timeout: 30000 |
Таблица 6
| настройка | server_failure_limit: <число> |
| Описание | Количество последовательных сбоев на сервере, которые могут привести к его временному auto_eject_host если для auto_eject_host установлено значение true . По умолчанию 2 . |
| пример | server_failure_limit: 2 |
Таблица 7
| настройка | серверы:
— имя: порт: вес | IP: порт: вес — имя: порт: вес | IP: порт: вес |
| Описание | Список адресов сервера, порта и веса ( name:port:weight или ip:port:weight) для определенного пула серверов. |
| пример | серверы:
— 127.0.0.1:6379:1 — 127.0.0.1:6380:1 |
Таблица 8
Мы twemproxy простую топологию с тремя экземплярами Redis (пул серверов) и twemproxy перед ними twemproxy ( nutcracker ), как показано на рисунке ниже:
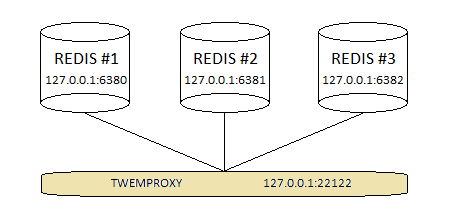
Рисунок 1. Twemproxy с конфигурацией пула серверов Redis, состоящей из трех экземпляров
Файл conf/nutcracker.yml twemproxy из twemproxy ( twemproxy ) является хорошим началом для поиска других примеров конфигурации. Что касается демонстрации, мы начнем со следующего sharded серверов, отражающего топологию, показанную выше.
Файл Щелкунчик-sharded.yml :
|
01
02
03
04
05
06
07
08
09
10
11
12
|
sharded: listen: 127.0.0.1:22122 hash: fnv1a_64 distribution: ketama auto_eject_hosts: true redis: true server_retry_timeout: 2000 server_failure_limit: 2 servers: - 127.0.0.1:6380:1 - 127.0.0.1:6381:1 - 127.0.0.1:6382:1 |
В sharded серверов используется ketama согласованное с ketama для распределения ключей с хэш-ключом, установленным в fnv1a_64 .
Перед запуском twemproxy ( nutcracker ) мы должны запустить все три экземпляра Redis на портах 6380 , 6381 и 6382 .
|
1
2
3
|
redis-server --port 6380redis-server --port 6381redis-server --port 6382 |
После этого экземпляр twemproxy ( nutcracker ) с примером конфигурации можно запустить с помощью команды:
|
1
|
nutcracker -c nutcracker-sharded.yml |

Рисунок 2. Twemproxy (щелкунчик) был успешно запущен
Самый простой способ проверки шардинга (разбиения) в действии — подключиться к twemproxy ( nutcracker ), сохранить пару пар ключ / значение и затем попытаться получить все сохраненные ключи из каждого экземпляра Redis: каждый ключ должен возвращаться одним и только одним Например, другие должны вернуть ( nil ). Хотя запрос тех же ключей у twemproxy ( nutcracker ) всегда приведет к ранее сохраненному значению. В нашем примере конфигурации twemproxy ( nutcracker ) прослушивает порт 22122 и может быть подключен с помощью обычного инструмента redis-cli . Три ключа userkey , somekey и anotherkey будут установлены на некоторые значения.
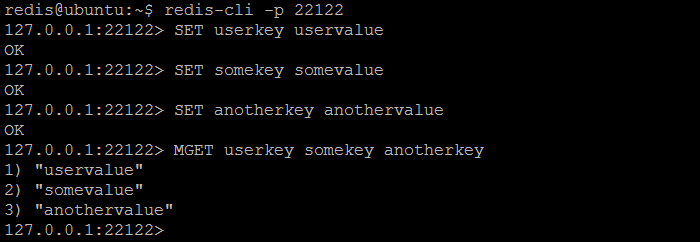
Рисунок 3. Установка нескольких пар ключ / значение в Twemproxy (Щелкунчик) и проверка их сохранения
Теперь, если мы twemproxy каждый отдельный экземпляр Redis из нашего twemproxy серверов twemproxy ( twemproxy ), некоторые ключи ( userkey , somekey , anotherkey ) будут разрешены в некоторых экземплярах, но не другими.
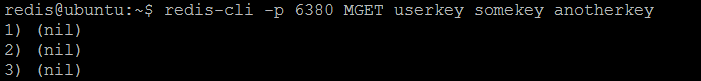
Рисунок 4. Redis # 1 не хранит ключи

Рисунок 5. Redis # 2 userkey только один ключ userkey
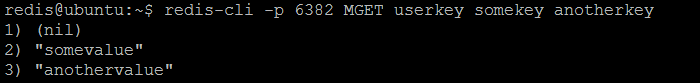
Рисунок 6. Redis # 3 имеет два ключа somekey и anotherkey сохранены
Можно задать интересный вопрос: почему ключи хранятся таким образом? Ответ — настроенная hash function : ключи распределены последовательно по всем экземплярам Redis в пуле серверов. Но для того, чтобы иметь сбалансированное (четное или случайное) распределение, сконфигурированная hash function должна быть очень тщательно выбрана с учетом шаблонов именования ключей, используемых приложением. Как показывает наш пример, ключи не распределены равномерно по всем экземплярам (у первого экземпляра ничего нет, у второго — один ключ, а у третьего — два ключа).
Последнее предостережение: хотя twemproxy ( nutcracker ) поддерживает протокол Redis, не все команды поддерживаются из-за ограничений, обсуждаемых в разделе « Когда использовать Sharding (Partitioning) ».
Для получения более подробной информации о twemproxy ( nutcracker ), пожалуйста, обратитесь к https://github.com/twitter/twemproxy , он имеет отличную, актуальную документацию.
8. Что дальше
В этом разделе мы рассмотрели только один способ решения вопроса о разделении (разбиении) в Redis. В следующей части, Redis Clustering , мы рассмотрим альтернативные решения.