В этом посте мы увидим, как разработать простой язык. Мы будем стремиться получить:
- парсер для языка
- редактор для IntelliJ . Редактор должен иметь подсветку синтаксиса, проверку и автозаполнение
Мы также бесплатно получили бы редактор для Eclipse и веб-редактор , но, пожалуйста, не стесняйтесь, мы не будем рассматривать это в этом посте.
В прошлом году я сосредоточился на изучении новых вещей (в основном веб и опс), но одна из вещей, которые мне все еще нравятся больше всего, это разработка DSL (предметно-ориентированных языков). Первой связанной технологией, с которой я играл, был Xtext : Xtext — это фантастический инструмент, который позволяет вам определять грамматику вашего языка и создавать удивительные редакторы для такого языка. До сих пор он разрабатывался только для платформы Eclipse: это означает, что новые языки могут разрабатываться с использованием Eclipse, и полученные в результате редакторы могут быть затем установлены в Eclipse.
В последнее время я использую гораздо меньше Eclipse, и поэтому мой интерес к Xtext угас до сих пор, когда наконец новый выпуск Xtext (все еще в бета-версии) нацелен на IntelliJ. Поэтому, пока мы будем разрабатывать наш язык с использованием Eclipse, мы затем сгенерируем плагины для использования нашего языка как в IntelliJ.
Методы, которые мы собираемся увидеть, могут быть использованы для разработки любого языка, но мы собираемся применить их к конкретному случаю: преобразованиям AST. Этот пост предназначен для новичков Xtext, и я пока не буду вдаваться в подробности, я просто делюсь своим первым впечатлением от цели IntelliJ. Учтите, что эта функциональность в настоящее время является бета-версией, поэтому мы можем ожидать некоторые грубые края.
Проблема, которую мы пытаемся решить: адаптировать парсеры ANTLR, чтобы получить классные AST
Мне нравится играть с парсерами, а ANTLR — отличный генератор парсеров. Есть прекрасные грамматики для полноценных языков, таких как Java. Теперь проблема в том, что грамматика языков, подобных Java, довольно сложна, и сгенерированные парсеры создают AST, которые не просты в использовании. Основная проблема связана с тем, как обрабатываются правила приоритета. Рассмотрим грамматику для Java 8 , созданную Теренсом Парром и Сэмом Харвеллом. Давайте посмотрим, как определяются некоторые выражения:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
conditionalExpression : conditionalOrExpression | conditionalOrExpression '?' expression ':' conditionalExpression ;conditionalOrExpression : conditionalAndExpression | conditionalOrExpression '||' conditionalAndExpression ;conditionalAndExpression : inclusiveOrExpression | conditionalAndExpression '&&' inclusiveOrExpression ;inclusiveOrExpression : exclusiveOrExpression | inclusiveOrExpression '|' exclusiveOrExpression ;exclusiveOrExpression : andExpression | exclusiveOrExpression '^' andExpression ;andExpression : equalityExpression | andExpression '&' equalityExpression ;equalityExpression : relationalExpression | equalityExpression '==' relationalExpression | equalityExpression '!=' relationalExpression ;relationalExpression : shiftExpression | relationalExpression '<' shiftExpression | relationalExpression '>' shiftExpression | relationalExpression '<=' shiftExpression | relationalExpression '>=' shiftExpression | relationalExpression 'instanceof' referenceType ;shiftExpression : additiveExpression | shiftExpression '<' '<' additiveExpression | shiftExpression '>' '>' additiveExpression | shiftExpression '>' '>' '>' additiveExpression ;additiveExpression : multiplicativeExpression | additiveExpression '+' multiplicativeExpression | additiveExpression '-' multiplicativeExpression ;multiplicativeExpression : unaryExpression | multiplicativeExpression '*' unaryExpression | multiplicativeExpression '/' unaryExpression | multiplicativeExpression '%' unaryExpression ;unaryExpression : preIncrementExpression | preDecrementExpression | '+' unaryExpression | '-' unaryExpression | unaryExpressionNotPlusMinus ; |
Это просто фрагмент большой части кода, используемого для определения выражений. Теперь представьте, что у вас есть простое выражение preIncrementExpression (что-то вроде: ++ a ). В AST у нас будет узел типа preIncrementExpression, который будет содержаться в unaryExpression.
Унарное выражение будет содержаться в мультипликативном выражении , которое будет содержаться в аддитивном выражении и так далее, и так далее. Эта организация необходима для обработки приоритета операторов между операциями различного типа, чтобы 1 + 2 * 3 анализировался как сумма 1 и 2 * 3 вместо умножения 1 + 2 и 3 . Проблема в том, что с логической точки зрения умножения и сложения являются выражениями на одном уровне: не имеет смысла иметь матрешки с узлами AST. Рассмотрим этот код:
|
1
|
class A { int a = 1 + 2 * 3; } |
Хотя мы хотели бы что-то вроде:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
[CompilationUnitContext] [TypeDeclarationContext] [ClassDeclarationContext] [NormalClassDeclarationContext] class A [ClassBodyContext] { [ClassBodyDeclarationContext] [ClassMemberDeclarationContext] [FieldDeclarationContext] [UnannTypeContext] [UnannPrimitiveTypeContext] [NumericTypeContext] [IntegralTypeContext] int [VariableDeclaratorListContext] [VariableDeclaratorContext] [VariableDeclaratorIdContext] a = [VariableInitializerContext] [ExpressionContext] [AssignmentExpressionContext] [ConditionalExpressionContext] [ConditionalOrExpressionContext] [ConditionalAndExpressionContext] [InclusiveOrExpressionContext] [ExclusiveOrExpressionContext] [AndExpressionContext] [EqualityExpressionContext] [RelationalExpressionContext] [ShiftExpressionContext] [AdditiveExpressionContext] [AdditiveExpressionContext] [MultiplicativeExpressionContext] [UnaryExpressionContext] [UnaryExpressionNotPlusMinusContext] [PostfixExpressionContext] [PrimaryContext] [PrimaryNoNewArray_lfno_primaryContext] [LiteralContext] 1 + [MultiplicativeExpressionContext] [MultiplicativeExpressionContext] [UnaryExpressionContext] [UnaryExpressionNotPlusMinusContext] [PostfixExpressionContext] [PrimaryContext] [PrimaryNoNewArray_lfno_primaryContext] [LiteralContext] 2 * [UnaryExpressionContext] [UnaryExpressionNotPlusMinusContext] [PostfixExpressionContext] [PrimaryContext] [PrimaryNoNewArray_lfno_primaryContext] [LiteralContext] 3 ; } <EOF> |
Хотя мы хотели бы что-то вроде:
|
1
2
3
4
5
6
7
8
|
[CompilationUnit] [FieldDeclaration] [PrimitiveTypeRef] [Sum] [Multiplication] [IntegerLiteral] [IntegerLiteral] [IntegerLiteral] |
В идеале мы хотим указать грамматики, которые производят AST в стиле Матрешки, но используют более плоские AST при анализе кода, поэтому мы собираемся создавать адаптеры из AST, как это сделано Antlr и «логическими» AST. Как мы планируем это сделать? Мы начнем с разработки языка, определяющего форму узлов так, как мы хотим, чтобы они отображались в логических AST, и мы также определим, как отобразить узлы Antlr (узлы в стиле Матрешки) в эти логические узлы. Это просто проблема, которую мы пытаемся решить: Xtext может использоваться для разработки любого языка, просто как маньяк парсера, мне нравится использовать DSL для решения проблем, связанных с парсером. Что очень мета .
Начало работы: установка Eclipse Luna DSL и создание проекта
Мы собираемся скачать версию Eclipse, содержащую бета-версию Xtext 2.9 . В вашем новом Eclipse вы можете создавать проекты нового типа: Xtext Projects .
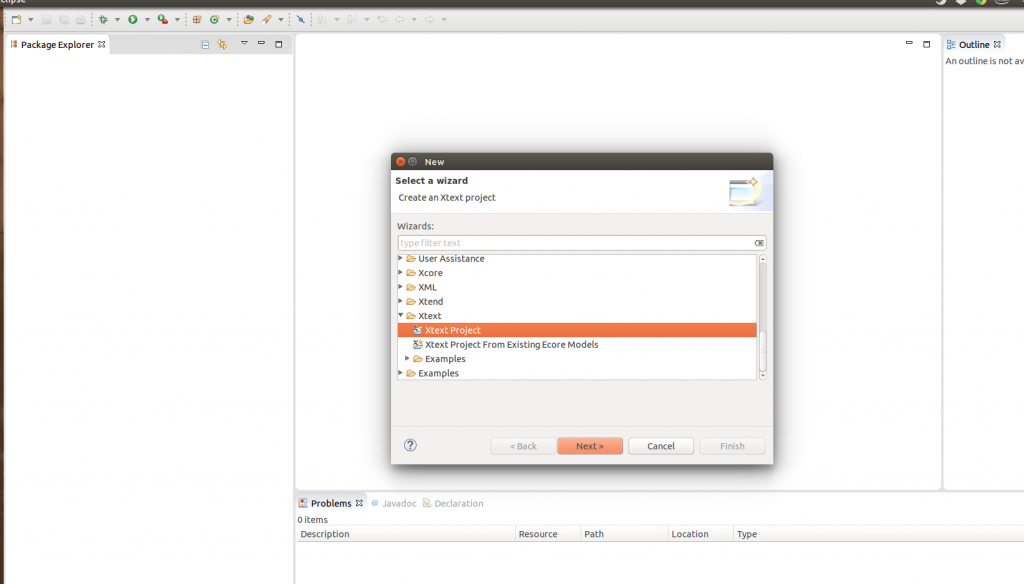
Нам просто нужно определить название проекта и выбрать расширение, которое будет связано с нашим новым языком
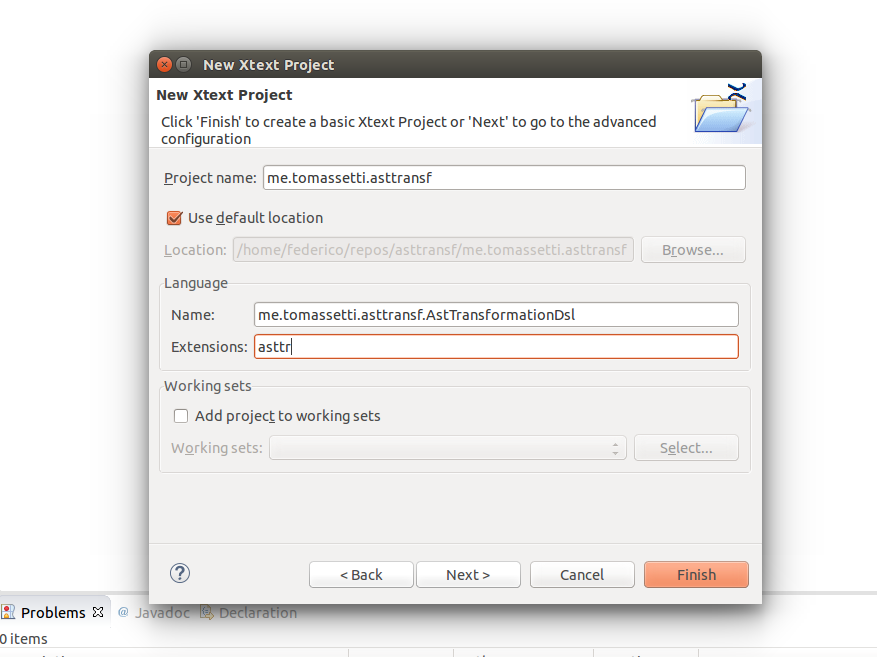
И затем мы выбираем платформы, в которых мы заинтересованы (да, есть также веб-платформа … мы рассмотрим это в будущем)
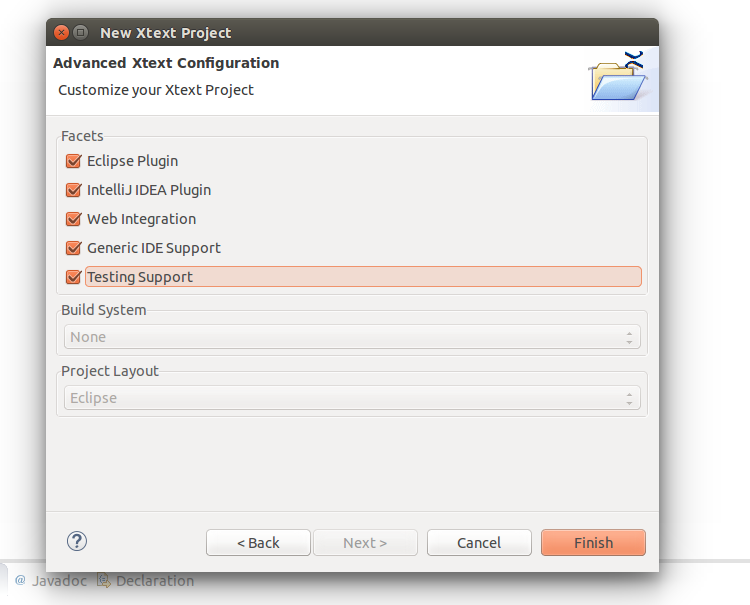
Созданный проект содержит образец грамматики. Мы могли бы использовать его как есть, нам нужно было бы просто сгенерировать несколько файлов с файлом MWE2.
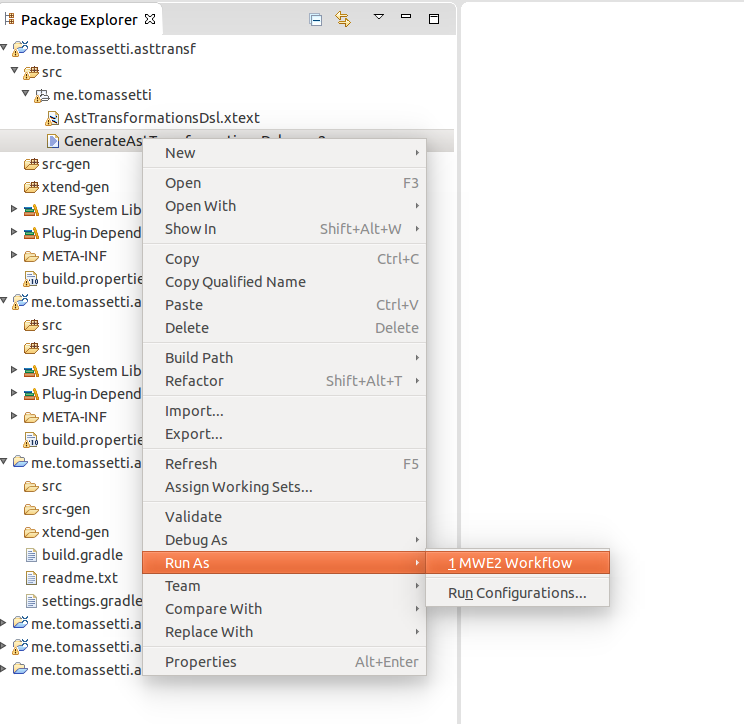
После запуска этой команды мы могли бы просто использовать наш новый плагин в IntelliJ или в Eclipse. Но вместо этого мы собираемся сначала изменить грамматику, чтобы преобразовать данный пример в наш великолепный DSL.
Пример нашего DSL
Наш язык будет выглядеть в IntelliJ IDEA (круто, а?).
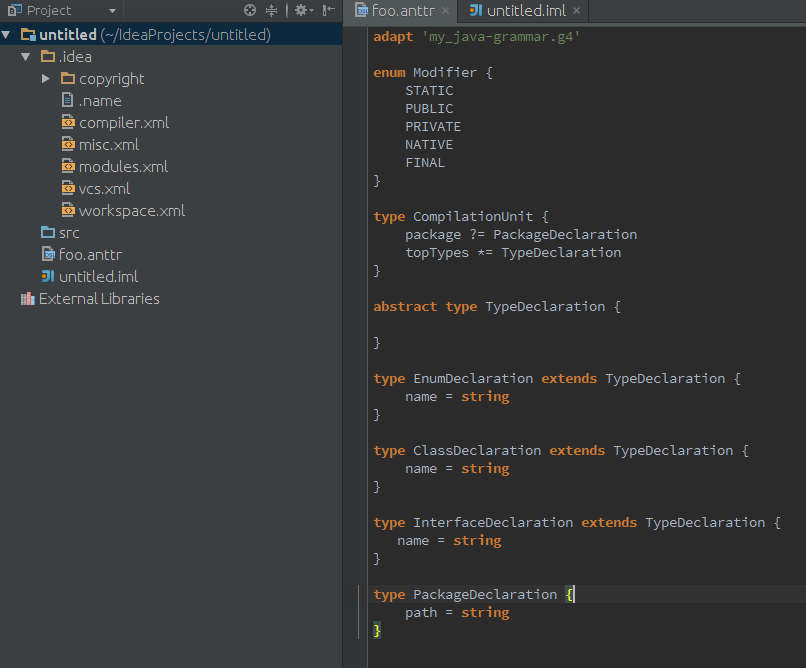
Конечно, это только начало, но мы начинаем определять некоторые базовые типы узлов для анализатора Java:
- перечисление, представляющее возможные модификаторы (предупреждение: это не полный список)
- CompilationUnit, который содержит необязательный PackageDeclaration и, возможно, множество TypeDeclarations
- TypeDeclaration является абстрактным узлом, и есть три конкретных типа, расширяющих его: EnumDeclaration, ClassDeclaration и InterfaceDeclaration (нам не хватает объявления аннотации)
Нам нужно будет добавить десятки выражений и утверждений, но вы должны получить представление о языке, который мы пытаемся создать. Также обратите внимание, что у нас есть ссылка на грамматику Antlr (в первой строке), но мы еще не определяем, как наши определенные типы узлов отображаются на типы узлов Antlr. Теперь вопрос: как мы это построим?
Определите грамматику
Мы можем определить грамматику нашего языка с помощью простой записи EBNF (с несколькими расширениями). Найдите файл с расширением xtext в вашем проекте и измените его следующим образом:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
grammar me.tomassetti.AstTransformationsDsl with org.eclipse.xtext.common.Terminalsgenerate astTransformationsDsl "http://www.tomassetti.me/AstTransformationsDsl"Model: antlr=AntlrGrammarRef declarations+=Declaration*; AntlrGrammarRef: 'adapt' grammarFile=STRING; Declaration: NodeType | NamedEnumDeclaration;NamedEnumDeclaration: 'enum' name=ID '{' values+=EnumNodeTypeFieldValue+ '}';UnnamedEnumDeclaration: 'enum' '{' values+=EnumNodeTypeFieldValue+ '}'; NodeType: 'abstract'? 'type' name=ID ('extends' superType=[NodeType])? ('from' antlrNode=ID)? '{' fields+=NodeTypeField* '}'; NodeTypeField: name=ID (many='*='|optional='?='|single='=') value=NodeTypeFieldValue; NodeTypeFieldValue: UnnamedEnumDeclaration | RelationNodeTypeField | AttributeNodeTypeField; EnumNodeTypeFieldValue: name=ID;RelationNodeTypeField: type=[NodeType]; AttributeNodeTypeField: {AttributeNodeTypeField}('string'|'int'|'boolean'); |
Первое определяемое нами правило соответствует корню AST ( модель в нашем случае). Наша Модель начинается со ссылки на файл Antlr и список объявлений. Идея состоит в том, чтобы указать объявления наших «логических» типов узлов и то, как типы узлов «antlr» должны быть сопоставлены с ними. Таким образом, мы определим преобразования, которые будут иметь ссылки на определенный элемент … в грамматике antlr, которую мы укажем в правиле AntlrGrammarRef .
Мы можем определить либо Enum, либо NodeType. NodeType имеет имя, может быть абстрактным и может расширять другой NodeType. Обратите внимание, что супертип является ссылкой на NodeType . Это означает, что получившийся редактор автоматически сможет дать нам автозаполнение (перечисляя все NodeTypes, определенные в файле) и проверку, подтверждая, что мы ссылаемся на существующий NodeType .
В наших NodeTypes мы можем определить столько полей, сколько захотим ( NodeTypeField ). Каждое поле начинается с имени, за которым следует оператор:
- * = означает, что мы можем иметь 0..n значений в этом поле
- ? = означает, что поле является необязательным (0..1) значением
- = означает, что всегда присутствует ровно одно значение
NodeTypeField также имеет тип значения, который может представлять собой перечисление, определенное inline ( БезымянныйEnumDeclaration ), отношение (это означает, что этот узел содержит другие узлы) или атрибут (это означает, что этот узел имеет некоторые базовые атрибуты, такие как строка или логическое значение).
Довольно просто, а?
Таким образом, мы в основном повторно запускаем файлы MWE2, и мы готовы к работе.
Смотрите плагин в действии
Чтобы увидеть, как наш плагин установлен в IntelliJ IDEA, нам нужно просто запустить gradle runIdea из каталога, содержащего плагин идеи (в нашем случае me.tomassetti.asttransf.idea ). Просто отметьте, что вам нужна последняя версия gradle и вам нужно определить JAVA_HOME . Эта команда загрузит IntelliJ IDEA, установит разработанный нами плагин и запустит его. В открытой IDE вы можете создать новый проект и определить новый файл. Просто используйте расширение, которое мы указали при создании проекта (в нашем случае .anttr ) и IDEA должна использовать наш недавно определенный редактор.
В настоящее время проверка работает, но редактор реагирует довольно медленно. Автозаполнение вместо этого сломано для меня. Учтите, что это всего лишь бета-версия, поэтому я ожидаю, что эти проблемы исчезнут до выхода Xtext 2.9.
Следующие шаги
Мы только начинаем, но удивительно, как мы можем создать DSL с его редактором для IDEA, работающим за считанные минуты.
Я планирую работать в нескольких разных направлениях:
- Нам нужно посмотреть, как упаковать и распространить плагин: мы можем попробовать его, используя gradle runIdea, но мы хотим просто создать двоичный файл, чтобы люди могли его установить, не обрабатывая исходные тексты редактора.
- Используйте произвольные зависимости от Maven: это будет довольно сложно, потому что Maven и плагин Eclipse (пакеты OSGi) определяют свои зависимости по-своему, поэтому обычно файлы jar должны быть упакованы в пакеты для использования в плагинах Eclipse. Однако есть альтернативы, такие как Tycho и p2-maven-plugin . Спойлер : Я не ожидаю, что этот будет слишком быстрым и легким…
- Мы пока не можем ссылаться на элементы, определенные в грамматике Antlr . Теперь это означает, что мы должны иметь возможность анализировать грамматику Antlr и программно создавать модели EMF, чтобы мы могли ссылаться на нее в нашем DSL. Требуется знать ЭДС (и это занимает некоторое время…). Я собираюсь поиграть с этим в будущем, и для этого, вероятно, потребуется учебное пособие.
Выводы
Хотя мне больше не нравится Eclipse (теперь я привык к IDEA, и он мне кажется намного лучше: быстрее и легче), Eclipse Modeling Framework продолжает быть очень интересным программным обеспечением, и возможность использовать его с IDEA — это здорово.
Некоторое время я не играл с EMF и Xtext, и я должен сказать, что видел некоторые улучшения. У меня было ощущение, что Eclipse не очень дружелюбен к командной строке, и в целом его сложно интегрировать с системами CI. Я вижу усилия, предпринимаемые для исправления этих проблем (см. Tycho или вспомогательную работу, которую мы использовали для запуска IDEA с разработанным нами редактором), и это мне кажется очень позитивным.
Смешение технологий, прагматическое сочетание лучших аспектов разных миров — моя философия, поэтому я надеюсь найти время, чтобы больше поиграть с этим материалом.
| Ссылка: | Разработайте DSL для Eclipse и IntelliJ, используя Xtext от нашего партнера по JCG |