 Распространение XML для обмена данными и формат файла конфигурации привело к появлению многочисленных библиотек Java XML Parser с открытым исходным кодом (изображение слева). Действительно, Java включает в себя свою собственную полноценную библиотеку XML, избавляя от необходимости загружать дополнительную библиотеку XML. Тем не менее, встроенные и большинство парсеров Java XML с открытым исходным кодом, как правило, страдают от нескольких значительных проблем, таких как сложность и раздутый размер, и это скорее нормально, чем исключительно.
Распространение XML для обмена данными и формат файла конфигурации привело к появлению многочисленных библиотек Java XML Parser с открытым исходным кодом (изображение слева). Действительно, Java включает в себя свою собственную полноценную библиотеку XML, избавляя от необходимости загружать дополнительную библиотеку XML. Тем не менее, встроенные и большинство парсеров Java XML с открытым исходным кодом, как правило, страдают от нескольких значительных проблем, таких как сложность и раздутый размер, и это скорее нормально, чем исключительно.
Это связано с тем, что большинство анализаторов Java XML предназначены для корпоративного использования, и поэтому поддержка новейших технологий XML, таких как XPATH, SCHEMA, встроена в библиотеки, что приводит к увеличению сложности и раздувания. Более того, большинство этих библиотек фактически повторно используют дополнительные внешние библиотеки, что значительно увеличивает их размер и сложность и запрещает их широкое использование при разработке настольных и мобильных приложений (большинство проектов с открытым исходным кодом страдают от плохой документации и поддержки и в сочетании с их сложностью дают Ява незаслуженное дурное имя). Кроме того, большой размер библиотеки и огромная сложность просто излишни, если вы просто хотите использовать XML элементарным способом (например, файл конфигурации, загрузка данных через сервис Web 2.0, например, Amazon).
Therefore a simple and easy-to-program solution is needed if one want to bundle it with mobile, applet, desktop solution that will be downloaded and deployed.
NanoXML
NanoXML is just the perfect Java XML Parser solution for those who value ease of use, simplicity and compactness. As its name implies, it is unprecedentedly lightweight and compact in size, taking less than 50kb (after modification) in space while still retaining important functionality ( a far cry from megabyte-size Java XML Parsers). Even though its development becomes inactive since 2003, its current version is still very much useful for processing simple XML stuff. It may not support the advanced technologies like XPATH, SCHEMA, however it is definitely capable of holding its own through its rich and easy API for searching, adding, updating and removing XML tag and attributes.
The reasons that I prefer NanoXML over competing solutions are because it is very simple to use, extremely compact, very fast and most importantly, it is much easier to extend its feature due to ‘lesser advanced’ features. Its compactness is particularly enticing for application that need to be downloaded over the web. In fact, NanoXML becomes a important component for those current projects I working now. This includes replacing the XML handling mechanism in gwtClassRun currently using string manipulation with NanoXML as having Java XML Parser will make XML processing more robust and easier to maintain.
Enhancement
Despite NanoXML in its current version 2.2.3, is a very useful library, it could definitely be made more flexible. Few caveats of NanoXML remain in this version that might deter its usage. Currently it ignores all comment in XML. Another problem is that adding of tag element can only be added to the last position. These limitations may deter others from considering it as a viable solution.
After failure to receive a response from the author over the request for those desired features, I ended up ‘hacking’ the source code and build those desired features. So after hours of dabbling with the code, the following ‘critical’ features are finally added.
— Parsing and generation of comment
— Adding tag element in specific position
See example section.
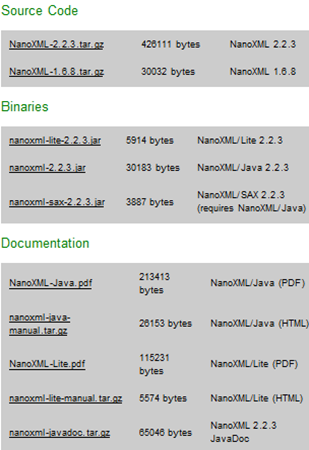
Download
The modified codes and binary are available for download
http://geekycoder.files.wordpress.com/2008/07/nanoxml-224.doc
Rename the file to nanoxml-224.zip because WordPress.com does not allow zip file to be stored in its service.
For documentation and support, please check the NanoXML’s original site.
For those who are interested to learn and use NanoXML, they can download through the following site (Click on the image)
Note that the last official version is version 2.2.3 . Since I have modified the code, I unofficially distinguished it by making it version v2.2.4 without official approval from the author (After failure to receive reply from email)
Note that the changes is only made for nanoxml-2.2.3.jar file, not the lite or SAX version
Example
For those who want to learn about NanoXML and the use of ‘enhanced’ features, the following is the example.
test.xml
<root name=”main”>
<child name=”me1″/>
<child name=”me2″/>
<child name=”me3″/>
</root>
XmlTest.java
import net.n3.nanoxml.*;
import java.io.File;
public class XmlTest
{
// ## means new features added.
public static void main(String[] _args) throws Exception
{
IXMLParser parser = XMLParserFactory.createDefaultXMLParser();
/*// If pass string, use stringReader
IXMLReader reader = StdXMLReader.stringReader(”<root></root>”);
*/
// Pass by file. Important to use toURL method otherwise exception will be thrown.
IXMLReader reader = StdXMLReader.fileReader(
new File(”c:/test.xml”).toURI().getPath());
parser.setReader(reader);
// parse() method does not include comment
IXMLElement xml = (IXMLElement) parser.parse(true); // ## true means parse comment too
IXMLElement _x = xml.createElement(”newChild”);
_x.setComment(”This is new child”); // ## Adding comment
_x.setAttribute(”att1″, “me1″);
_x.setAttribute(”att2″, “me2″);
xml.addChild(_x, 0); // ## Adding at specific position.
IXMLElement _b = xml.getChildAtIndex(1);
xml.removeChild(_b); // Remove tag
XMLWriter writer = new XMLWriter(System.out);
// Default for write is excluded comment
writer.setIncludeComment(true); // ## Include comment at generation.
writer.write(xml, true);
}
}
Result
After running the code against the testfile, the output should display:
<root name=”main”>
<!–This is new child–>
<newChild att1=”me1″ att2=”me2″/>
<child name=”me2″/>
<child name=”me3″/>
</root>