Мы часто упоминаем фразу «Механическая симпатия», фактически это даже название блога Мартина . Речь идет о понимании того, как работает базовое оборудование, и о программировании таким образом, чтобы оно работало с этим, а не против него.
Мы получили ряд комментариев и вопросов о загадочном заполнении строк кэша в RingBuffer , и я упоминал об этом в последнем посте . Так как это поддается красивым картинкам, я подумал, что это следующая вещь, которую я буду решать.
Comp Sci 101
Одна из вещей, которые мне нравятся в работе с LMAX, — это все то, что я изучал в университете, и в моем A Level Computing что-то действительно значит. Так часто, как разработчик, вы можете сойти с рук, не понимая ЦП, структуры данных илиBig O запись — я провел 10 лет своей карьеры, забыв обо всем этом. Но оказывается, что если вы знаете об этих вещах и применяете эти знания, вы можете придумать очень умный, очень быстрый код.
Итак, переподготовка для тех из нас, кто изучал это в школе, и введение для тех, кто не учился. Осторожно — этот пост содержит огромные упрощения.
Процессор — это сердце вашей машины, и в конечном итоге он должен выполнять все операции, выполняя вашу программу. Основная память (RAM) — это место, где хранятся ваши данные (включая строки вашей программы). Мы собираемся игнорировать такие вещи, как жесткие диски и сети, потому что Disruptor нацелен на работу как можно больше в памяти.
Процессор имеет несколько уровней кэша между ним и основной памятью, потому что даже доступ к основной памяти слишком медленный. Если вы выполняете одну и ту же операцию над частью данных несколько раз, имеет смысл загружать ее в место, очень близкое к процессору, когда она выполняет операцию (подумайте, счетчик циклов — вы не хотите, чтобы отключение в основную память, чтобы получить это, чтобы увеличивать его каждый раз, когда вы зацикливаетесь).

Чем ближе кэш к процессору, тем он быстрее и меньше. Кэш L1 небольшой и очень быстрый, и находится рядом с ядром, которое его использует. L2 больше и медленнее, и все еще используется только одним ядром. L3 чаще встречается на современных многоядерных машинах, снова больше, медленнее и распределяется между ядрами в одном сокете. Наконец, у вас есть основная память, которая распределяется между всеми ядрами и всеми сокетами.
Когда процессор выполняет операцию, сначала он ищет в L1 необходимые ему данные, затем L2, затем L3, и, наконец, если он не находится ни в одном из кэшей, данные необходимо извлекать полностью из основной памяти. Чем дальше, тем больше времени займет операция. Поэтому, если вы делаете что-то очень часто, вы хотите убедиться, что данные находятся в кеше L1.
В презентации QCon’а Мартина и Майка
приводятся некоторые ориентировочные данные о затратах на кеширование:
| Задержка от процессора до … | Прибл. количество тактов процессора |
Прибл. время в наносекундах |
| Основная память | ~ 60-80ns | |
| Транзит QPI (между розетками, не отрисован) |
~ 20ns | |
| Кэш L3 | ~ 40-45 циклов, | ~ 15ns |
| L2 кеш | ~ 10 циклов, | ~ 3 нс |
| L1 кеш | ~ 3-4 цикла, | ~ 1ns |
| регистр | 1 цикл |
Если вы стремитесь к сквозной задержке примерно в 10 миллисекунд, то 80-наносекундное путешествие в основную память для получения недостающих данных займет серьезную часть этого.
Теперь интересно отметить, что в кеше хранятся не отдельные элементы, то есть это не одна переменная, а один указатель. Кэш состоит из строк кэша, обычно 64 байта, и он эффективно ссылается на местоположение в основной памяти. Длина Java составляет 8 байт, поэтому в одной строке кэша вы можете иметь 8 переменных.

(Я собираюсь игнорировать несколько уровней кэша для простоты)
Это замечательно, если вы обращаетесь к массиву long — когда одно значение из массива загружается в кеш, вы получаете до 7 дополнительных бесплатно. Таким образом, вы можете пройти этот массив очень быстро. Фактически, вы можете очень быстро перебирать любую структуру данных, которая выделяется непрерывным блокам в памяти. Я упомянул об этом в самом
первом посте о кольцевом буфере , и он объясняет, почему мы используем для него массив.
Поэтому, если элементы в вашей структуре данных не размещаются рядом друг с другом в памяти (связанные списки, я смотрю на вас), вы не получите преимущества от загрузки кеша. Вы могли бы получить пропуск кэша для каждого элемента в этой структуре данных.
Тем не менее, есть недостаток для всей этой бесплатной загрузки. Представьте, что ваше длинное не является частью массива. Представьте, что это всего лишь одна переменная. Давайте назовем это головой, без реальной причины. Затем представьте, что у вас есть другая переменная в вашем классе рядом с ней. Будем произвольно называть это хвостом. Теперь, когда вы загружаете голову в свой кеш, вы получаете хвост бесплатно.

Что звучит нормально. Пока вы не поймете, что хвост написан вашим производителем, а голова написана вашим потребителем. Эти две переменные на самом деле не тесно связаны, и фактически будут использоваться двумя разными потоками, которые могут работать на двух разных ядрах.
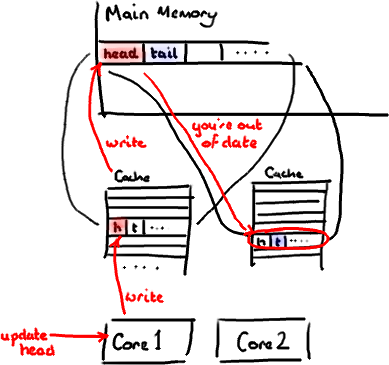
Представьте, что ваш потребитель обновляет ценность головы. Значение кэша обновляется, значение в памяти обновляется, и любые другие строки кэша, содержащие заголовок, становятся недействительными, потому что другие кэши не будут иметь нового блестящего значения. И помните, что мы имеем дело с уровнем всей линии, мы не можем просто пометить голову как недействительную.

Теперь, если какой-либо процесс, работающий на другом ядре, просто хочет прочитать значение tail, всю строку кэша необходимо перечитать из основной памяти. Таким образом, поток, который не имеет ничего общего с вашим потребителем, читает значение, которое не имеет ничего общего с головой, и это замедляется из-за отсутствия кэша.
Конечно, это еще хуже, если два отдельных потока записывают два разных значения. Оба ядра будут лишать законной силы строку кэша на другом ядре и должны будут перечитывать ее каждый раз, когда другой поток записывает в нее. По сути, у вас есть конфликт записи между двумя потоками, даже если они записывают в две разные переменные.
Это называется
ложным разделением , потому что каждый раз, когда вы получаете доступ к голове, вы тоже получаете хвост, и каждый раз, когда вы получаете доступ к хвосту, вы также получаете голову. Все это происходит под прикрытием, и никакое предупреждение компилятора не скажет вам, что вы только что написали код, который будет очень неэффективным для одновременного доступа.
Вы увидите, что Disruptor устраняет эту проблему, по крайней мере, для архитектуры, которая имеет размер кэша 64 байта или меньше, добавляя заполнение, чтобы гарантировать, что порядковый номер кольцевого буфера никогда не находится в строке кэша с чем-либо еще.
public long p1, p2, p3, p4, p5, p6, p7; // cache line padding
private volatile long cursor = INITIAL_CURSOR_VALUE;
public long p8, p9, p10, p11, p12, p13, p14; // cache line padding
Таким образом, нет никакого ложного совместного использования, никакого непреднамеренного конфликта с любыми другими переменными, нет ненужных промахов кэша.
Это стоит делать и на ваших классах Entry — если у вас разные потребители пишут в разные поля, вам нужно будет убедиться, что между этими полями нет ложного разделения.
От http://mechanitis.blogspot.com/2011/07/dissecting-disruptor-why-its-so-fast_22.html