Мое недавнее замедление публикации состоит в том, что я пытался написать публикацию, объясняющую барьеры памяти и их применимость в Disruptor . Проблема в том, что независимо от того, сколько я читаю и сколько раз я задаю вечно терпеливым вопросам Мартина и Майка, пытающимся прояснить какой-то вопрос, я просто интуитивно не понимаю предмет. Я думаю, у меня нет глубоких базовых знаний, необходимых для полного понимания.
Поэтому вместо того, чтобы делать из себя идиота, пытающегося объяснить что-то, чего я на самом деле не понимаю, я попытаюсь охватить на уровне абстрактного / массового упрощения то, что я понимаю в этой области. Мартин написал пост, входящий в барьеры памяти в некоторых деталях, так что, надеюсь, мне удастся сойтись с рассмотрением предмета.
Отказ от ответственности: любые ошибки в объяснении — полностью мои собственные, и я не думаю о реализации Disruptor или о парнях LMAX, которые действительно знают об этом.
В чем смысл?
Моя главная цель в этой серии постов в блоге — объяснить, как работает Disruptor и, в несколько меньшей степени, почему. В теории я должен быть в состоянии обеспечить мост между кодом и технической статьей , говоря об этом с точки зрения разработчика, который может захотеть его использовать.
В документе упоминаются барьеры памяти, и я хотел понять, что они из себя представляют и как они применяются.
Что такое барьер памяти?
Это инструкция процессора. Да, еще раз, мы думаем о вещах на уровне процессора, чтобы получить необходимую нам производительность (знаменитая механическая симпатия Мартина). По сути, это инструкция: а) обеспечить порядок, в котором выполняются определенные операции, и б) повлиять на видимость некоторых данных (что может быть результатом выполнения какой-либо инструкции).
Компиляторы и процессоры могут переупорядочивать инструкции при условии, что конечный результат одинаков, чтобы попытаться оптимизировать производительность. Вставка барьера памяти сообщает процессору и компилятору, что то, что произошло до этой команды, должно оставаться перед этой командой, а то, что происходит после, должно оставаться после. Все сходства с поездкой в Лас-Вегас целиком в вашем собственном уме.
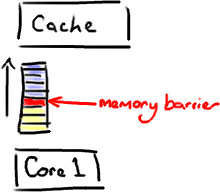
Еще одна вещь, которую делает барьер памяти, это принудительно обновляет различные кэши ЦП — например, барьер записи сбрасывает все данные, которые были записаны до того, как барьер был отправлен в кэш, поэтому любой другой поток, который пытается прочитать эти данные, получит самая последняя версия, независимо от того, каким ядром или каким сокетом она может быть выполнена.
Какое это имеет отношение к Java?
Теперь я знаю, что вы думаете — это не ассемблер. Это Java.
Волшебное заклинание здесь — слово volatile (то, что я чувствовал, никогда не было ясно объяснено в сертификации Java). Если ваше поле
изменчиво
, Java Memory Model вставляет инструкцию барьера записи после записи в нее и инструкцию барьера чтения перед чтением из нее.

Это означает, что если вы пишете в изменчивое поле, вы знаете, что:
- Любой поток, обращающийся к этому полю после точки, в которую вы написали, получит обновленное значение
- Все, что вы делали до того, как написали это поле, гарантированно произойдет, и любые обновленные значения данных также будут видны, поскольку барьер памяти сбрасывал все предыдущие записи в кэш.
Так рада, что ты спросил. Пришло время снова начать рисовать пончики.

Производитель получит следующую
запись (или партию из них) и сделает все, что ему нужно сделать с записями, обновив их любыми значениями, которые он хочет поместить в них.
Как вы знаете , в конце всех изменений производитель вызывает метод commit для кольцевого буфера, который обновляет порядковый номер. Эта запись изменяемого поля (курсора) создает барьер памяти, который в конечном счете приводит к обновлению всех кэшей (или, по крайней мере, делает их недействительными соответственно).
В этот момент потребители могут получить обновленный порядковый номер (8), и поскольку барьер памяти также гарантирует порядок команд, которые произошли до этого, потребители могут быть уверены, что все изменения, внесенные производителем в
запись в позиции 7 также доступны.
Порядковый номер на получателе является нестабильным и читается рядом внешних объектов — другие
нижестоящие потребители могут отслеживать этого потребителя
, а
ProducerBarrier /
RingBuffer (в зависимости от того, смотрите ли вы старый или более новый код) отслеживает его, чтобы сделать уверен, что кольцо не оборачивается.
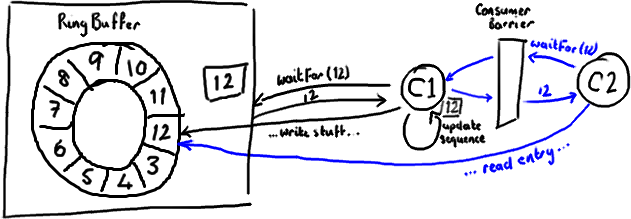
Итак, если ваш нисходящий потребитель (C2) видит, что более ранний потребитель (C1) достигает номера 12, когда C2 читает записи до 12 из кольцевого буфера, он получит все обновления C1, сделанные в записи, прежде чем он обновит свой порядковый номер.
По сути, все, что происходит после того, как C2 получает обновленный порядковый номер (показано синим цветом выше), должно происходить после того, как все, что C1 сделал с кольцевым буфером, перед обновлением его порядкового номера (показано черным цветом).
Влияние на производительность
Барьеры памяти, будучи еще одной инструкцией уровня процессора, не имеют такой же
стоимости, как блокировки — ядро не вмешивается и не осуществляет арбитраж между несколькими потоками. Но ничего не приходит бесплатно. Барьеры памяти имеют свою стоимость: компилятор / ЦП не могут переупорядочивать инструкции, что может привести к неэффективному использованию ЦП, а обновление кешей, очевидно, влияет на производительность. Так что не думайте, что использование volatile вместо блокировки избавит вас от лишнего шума.
Вы заметите, что реализация Disruptor пытается читать и записывать порядковый номер как можно реже. Каждое чтение или запись изменчивого поля является относительно дорогостоящей операцией. Тем не менее, признание этого также очень хорошо сочетается с режимом пакетирования — если вы знаете, что не следует читать или записывать последовательности слишком часто, имеет смысл собрать целую группу записей и обработать их перед обновлением порядкового номера. на стороне производителя и потребителя. Вот пример из
BatchConsumer :
long nextSequence = sequence + 1;
while (running)
{
try
{
final long availableSequence = consumerBarrier.waitFor(nextSequence);
while (nextSequence <= availableSequence)
{
entry = consumerBarrier.getEntry(nextSequence);
handler.onAvailable(entry);
nextSequence++;
}
handler.onEndOfBatch();
sequence = entry.getSequence();
}
...
catch (final Exception ex)
{
exceptionHandler.handle(ex, entry);
sequence = entry.getSequence();
nextSequence = entry.getSequence() + 1;
}
}
(Вы заметите, что это «старый» код и соглашения об именах, потому что это соответствует моим предыдущим постам в блоге, я подумал, что это немного менее запутанно, чем переход прямо к новым соглашениям).
В приведенном выше коде мы используем локальную переменную для увеличения во время нашего цикла над записями, которые обрабатывает потребитель. Это означает, что мы читаем и пишем в поле volatile sequence (выделено жирным шрифтом) так редко, как только можем.
В итоге
Барьеры памяти — это инструкции процессора, которые позволяют вам делать определенные предположения о том, когда данные будут видны другим процессам. В Java вы реализуете их с ключевым словом volatile. Использование volatile означает, что вам не обязательно добавлять блокировки, но это даст вам повышение производительности по сравнению с их использованием. Однако вам нужно немного подумать о своем дизайне, в частности о том, как часто вы используете изменяемые поля и как часто вы читаете и пишете их.
PS Учитывая, что Новый Мировой Порядок в Disruptor использует теперь совершенно разные соглашения об именах ко всему, о чем я до сих пор писал в блоге, я думаю, что следующий пост отображает старый мир на новый.
От http://mechanitis.blogspot.com/2011/08/dissecting-disruptor-why-its-so-fast.html