В настоящее время я слежу за курсом Coursera ‘ Mining Massive Datasets ‘. В течение некоторого времени я интересовался MapReduce и Apache Hadoop, и с этим курсом я надеюсь получить больше информации о том, когда и как MapReduce может помочь решить некоторые реальные проблемы бизнеса (другой способ, который я описал здесь ). Этот курс Coursera в основном посвящен теории используемых алгоритмов, а не самому кодированию. Первая неделя посвящена PageRanking и тому, как Google использовал это для ранжирования страниц. К счастью, есть много возможностей найти эту тему в сочетании с Hadoop. Я попал сюда и решил поближе взглянуть на этот код.
Я взял этот код (разветвил его) и немного переписал. Я создал модульные тесты для картографов и редукторов, как я описал здесь . В качестве теста я использовал пример из курса. У нас есть три веб-страницы, ссылающиеся друг на друга и / или на себя:
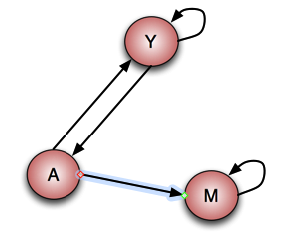
Эта схема ссылок должна соответствовать следующему рейтингу страницы:
- Y 7/33
- А 5/33
- М 21/33
Так как код примера MapReduce ожидает XML «Wiki-страницу» в качестве входных данных, я создал следующий набор тестов:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
<mediawiki xmlns="http://www.mediawiki.org/xml/export-0.10/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mediawiki.org/xml/export-0.10/ http://www.mediawiki.org/xml/export-0.10.xsd" version="0.10" xml:lang="en"> <page> <title>A</title> <id>121173</id> <revision> ... <text xml:space="preserve" bytes="6523">[[Y]] [[M]]</text> </revision> </page> <page> <title>Y</title> <id>121173</id> <revision> ... <text xml:space="preserve" bytes="6523">[[A]] [[Y]]</text> </revision> </page> <page> <title>M</title> <id>121173</id> <revision> ... <text xml:space="preserve" bytes="6523">[[M]]</text> </revision> </page></mediawiki> |
Глобальный способ работы уже хорошо объяснен на самой странице . Я опишу только созданные мной тесты. С оригинальным объяснением и моими юнит-тестами вы сможете разобраться в этом вопросе и понять, что происходит.
Как описано, общая работа делится на три части:
- разбор
- расчета
- заказ
В части синтаксического анализа берется необработанный XML, разбивается на страницы и отображается так, что мы получаем в качестве вывода страницу в качестве ключа и значение страниц, на которые она имеет исходящие ссылки. Таким образом, входными данными для модульного теста будут три XML-страницы Wiki, как показано выше. Ожидается «заголовок» страниц со связанными страницами. Модульный тест выглядит так:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
package net.pascalalma.hadoop.job1;...public class WikiPageLinksMapperTest { MapDriver<LongWritable, Text, Text, Text> mapDriver; String testPageA = " <page>\n" + " <title>A</title>\n" + " ..." + " <text xml:space=\"preserve\" bytes=\"6523\">[[Y]] [[M]]</text>\n" + " </revision>"; String testPageY = " <page>\n" + " <title>Y</title>\n" + " ..." + " <text xml:space=\"preserve\" bytes=\"6523\">[[A]] [[Y]]</text>\n" + " </revision>\n" + " </page>"; String testPageM = " <page>\n" + " <title>M</title>\n" + " ..." + " <text xml:space=\"preserve\" bytes=\"6523\">[[M]]</text>\n" + " </revision>\n" + " </page>"; @Before public void setUp() { WikiPageLinksMapper mapper = new WikiPageLinksMapper(); mapDriver = MapDriver.newMapDriver(mapper); } @Test public void testMapper() throws IOException { mapDriver.withInput(new LongWritable(1), new Text(testPageA)); mapDriver.withInput(new LongWritable(2), new Text(testPageM)); mapDriver.withInput(new LongWritable(3), new Text(testPageY)); mapDriver.withOutput(new Text("A"), new Text("Y")); mapDriver.withOutput(new Text("A"), new Text("M")); mapDriver.withOutput(new Text("Y"), new Text("A")); mapDriver.withOutput(new Text("Y"), new Text("Y")); mapDriver.withOutput(new Text("M"), new Text("M")); mapDriver.runTest(false); }} |
Выход картографа будет входом для нашего редуктора. Модульный тест для этого выглядит так:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
package net.pascalalma.hadoop.job1;...public class WikiLinksReducerTest { ReduceDriver<Text, Text, Text, Text> reduceDriver; @Before public void setUp() { WikiLinksReducer reducer = new WikiLinksReducer(); reduceDriver = ReduceDriver.newReduceDriver(reducer); } @Test public void testReducer() throws IOException { List<Text> valuesA = new ArrayList<Text>(); valuesA.add(new Text("M")); valuesA.add(new Text("Y")); reduceDriver.withInput(new Text("A"), valuesA); reduceDriver.withOutput(new Text("A"), new Text("1.0\tM,Y")); reduceDriver.runTest(); }} |
Как показывает модульный тест, мы ожидаем, что редуктор уменьшит входные данные до значения «начального» ранга страницы 1,0, объединенного со всеми страницами, на которые (ключевая) страница имеет исходящие ссылки. Это выход этой фазы и будет использоваться в качестве входа для фазы «расчета».
В части вычисления будет выполнен пересчет рангов входящих страниц для реализации метода « мощной итерации ». Этот шаг будет выполнен несколько раз, чтобы получить приемлемый рейтинг страниц для данного набора страниц. Как сказано выше, выходные данные предыдущей части являются входными данными этого шага, как мы видим в модульном тесте для этого преобразователя:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
package net.pascalalma.hadoop.job2;...public class RankCalculateMapperTest { MapDriver<LongWritable, Text, Text, Text> mapDriver; @Before public void setUp() { RankCalculateMapper mapper = new RankCalculateMapper(); mapDriver = MapDriver.newMapDriver(mapper); } @Test public void testMapper() throws IOException { mapDriver.withInput(new LongWritable(1), new Text("A\t1.0\tM,Y")); mapDriver.withInput(new LongWritable(2), new Text("M\t1.0\tM")); mapDriver.withInput(new LongWritable(3), new Text("Y\t1.0\tY,A")); mapDriver.withOutput(new Text("M"), new Text("A\t1.0\t2")); mapDriver.withOutput(new Text("A"), new Text("Y\t1.0\t2")); mapDriver.withOutput(new Text("Y"), new Text("A\t1.0\t2")); mapDriver.withOutput(new Text("A"), new Text("|M,Y")); mapDriver.withOutput(new Text("M"), new Text("M\t1.0\t1")); mapDriver.withOutput(new Text("Y"), new Text("Y\t1.0\t2")); mapDriver.withOutput(new Text("A"), new Text("!")); mapDriver.withOutput(new Text("M"), new Text("|M")); mapDriver.withOutput(new Text("M"), new Text("!")); mapDriver.withOutput(new Text("Y"), new Text("|Y,A")); mapDriver.withOutput(new Text("Y"), new Text("!")); mapDriver.runTest(false); }} |
Вывод здесь объясняется на странице источника. «Дополнительные» предметы с «!» и ‘|’ необходимы в шаге сокращения для расчетов. Модульный тест для редуктора выглядит так:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
package net.pascalalma.hadoop.job2;...public class RankCalculateReduceTest { ReduceDriver<Text, Text, Text, Text> reduceDriver; @Before public void setUp() { RankCalculateReduce reducer = new RankCalculateReduce(); reduceDriver = ReduceDriver.newReduceDriver(reducer); } @Test public void testReducer() throws IOException { List<Text> valuesM = new ArrayList<Text>(); valuesM.add(new Text("A\t1.0\t2")); valuesM.add(new Text("M\t1.0\t1")); valuesM.add(new Text("|M")); valuesM.add(new Text("!")); reduceDriver.withInput(new Text("M"), valuesM); List<Text> valuesA = new ArrayList<Text>(); valuesA.add(new Text("Y\t1.0\t2")); valuesA.add(new Text("|M,Y")); valuesA.add(new Text("!")); reduceDriver.withInput(new Text("A"), valuesA); List<Text> valuesY = new ArrayList<Text>(); valuesY.add(new Text("Y\t1.0\t2")); valuesY.add(new Text("|Y,A")); valuesY.add(new Text("!")); valuesY.add(new Text("A\t1.0\t2")); reduceDriver.withInput(new Text("Y"), valuesY); reduceDriver.withOutput(new Text("A"), new Text("0.6\tM,Y")); reduceDriver.withOutput(new Text("M"), new Text("1.4000001\tM")); reduceDriver.withOutput(new Text("Y"), new Text("1.0\tY,A")); reduceDriver.runTest(false); }} |
Как показано, выходные данные преобразователя воссоздаются как входные данные, и мы проверяем, что выходные данные редуктора соответствуют первой итерации вычисления ранга страницы. Каждая итерация приведет к одному и тому же формату вывода, но с различными значениями ранга страницы.
Последний шаг — часть заказа. Это довольно просто, как и модульный тест. Эта часть содержит только маппер, который принимает выходные данные предыдущего шага и «переформатирует» его в нужный формат: pagerank + page pagek by pagerank. Сортировка по ключу выполняется платформой Hadoop, когда результат отображения отображается на шаге редуктора, поэтому этот порядок не отражается в модульном тесте Mapper. Код для этого модульного теста:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
package net.pascalalma.hadoop.job3;...public class RankingMapperTest { MapDriver<LongWritable, Text, FloatWritable, Text> mapDriver; @Before public void setUp() { RankingMapper mapper = new RankingMapper(); mapDriver = MapDriver.newMapDriver(mapper); } @Test public void testMapper() throws IOException { mapDriver.withInput(new LongWritable(1), new Text("A\t0.454545\tM,Y")); mapDriver.withInput(new LongWritable(2), new Text("M\t1.90\tM")); mapDriver.withInput(new LongWritable(3), new Text("Y\t0.68898\tY,A")); //Please note that we cannot check for ordering here because that is done by Hadoop after the Map phase mapDriver.withOutput(new FloatWritable(0.454545f), new Text("A")); mapDriver.withOutput(new FloatWritable(1.9f), new Text("M")); mapDriver.withOutput(new FloatWritable(0.68898f), new Text("Y")); mapDriver.runTest(false); }} |
Итак, здесь мы просто проверяем, что преобразователь принимает входные данные и правильно форматирует выходные данные.
На этом завершаются все примеры юнит-тестов. С этим проектом вы сможете протестировать его сами и получить более полное представление о том, как работает оригинальный код. Это, конечно, помогло мне понять это!
- С полной версией кода, включая юнит-тесты, можно ознакомиться здесь .
| Ссылка: | Рассчитывайте PageRanks с помощью Apache Hadoop от нашего партнера по JCG Паскаля Альмы в блоге Pragmatic Integrator . |