Обработка ошибок — одна из самых сложных и игнорируемых частей разработки программного обеспечения, и если система распространяется, то это становится еще сложнее.
Хорошая статья написана на тему « Простое тестирование может предотвратить большинство критических ошибок» .

Каждый разработчик должен прочитать эту статью. Я постараюсь обобщить ключевые выводы из этой статьи, но предложу прочитать статью, чтобы узнать о ней больше.
Распределенная система простоя является распространенным явлением, и некоторые из недавних примеров
Youtube был закрыт в октябре 2018 года около 1 часа
Амазонка не работала в премьерный день июля 2018 года
Сервисы Google, такие как Map, Gmail, Youtube, не работали в 2018 году
Facebook также был в стороне от многих проблем утечки данных, с которыми они сталкиваются.
В этой статье рассказывается о катастрофическом сбое в распределенных системах, таких как Cassandra, Hbase, HDFS, Redis, Map Reduce.
Согласно статье, большинство ошибок связано с двумя причинами.
— сбой происходит из-за сложной последовательности событий
— Катастрофическая ошибка из-за неправильного обращения
— Я включу 3-й по «игнорированию проектного давления», который я написал в посте « дизайнерское давление на инженера»
Пример из отключения HBase
1 — Балансировщик нагрузки Передача области R из подчиненного устройства в подчиненное
2 — Раб B, открытый регион R
3 — Мастер удаляет текущий регион Zookeeper R после того, как он принадлежит Slave B
4 — Раб B умирает
5 — Регион R назначен подчиненному C и подчиненному C, откройте регион
6 — Master пытается удалить Slave B znode на Zookeeper и потому, что Slave b не работает и весь кластер выходит из строя из-за неправильного кода обработки ошибок.
В приведенном выше примере последовательность событий имеет значение для воспроизведения вопроса.
Сбой HDFS, когда блок не реплицируется.
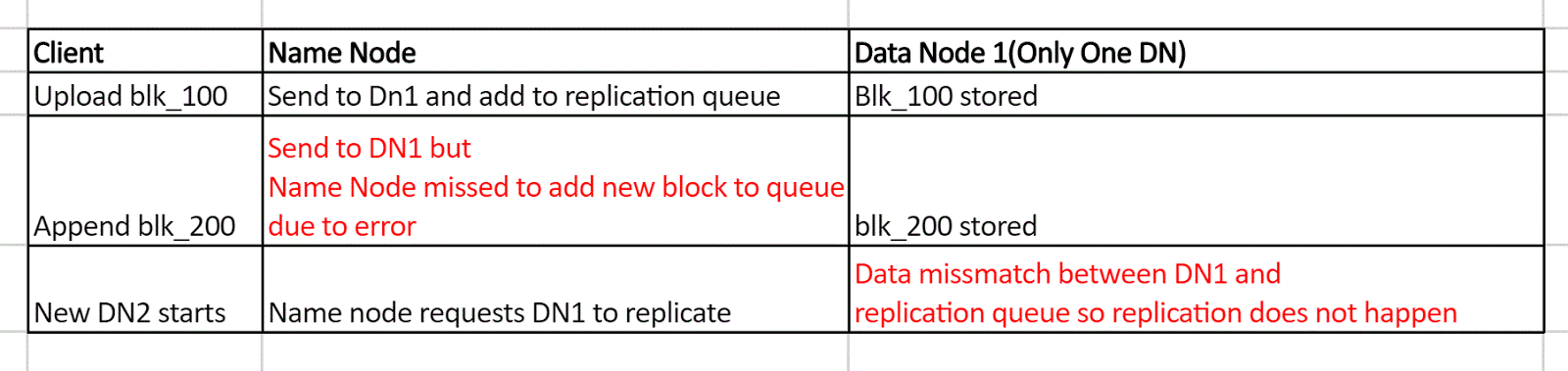
В этом примере также последовательность событий, и когда запускается новый узел данных, это выявляет ошибку системы.
У бумаги есть еще много примеров.
Основная причина ошибки
92% катастрофической ошибки происходит из-за неправильной обработки ошибок.
Это означает, что ошибка была вычтена, но код обработки ошибок не был хорош, похоже ли это на большой проект, над которым вы работали!
1 — ошибки игнорируются
Это является причиной 25% сбоев, я думаю, что число будет много во многих живых системах.
|
1
2
3
4
|
eg of such errorcatch(RebootException e) {log.info("Reboot occurred....")} |
Да, этот безвредный вид записи оператора игнорирует исключение и является очень распространенным анти-шаблоном обработки ошибок.
2 — исключение превышения
Это также очень распространено, например, общий блок захвата и разрушение всей системы.
|
1
2
3
|
catch(Throwable e) {cluster.abort()} |
3 — TODO / FIXME в комментариях
Да, настоящая распределенная система в производстве также имеет много TODO / FIXME в критической части кода.
Некоторый другой пример обработки ошибок
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
<i>} catch (IOException e) {</i><i> // will never happen </i><i> }</i><i>} catch (NoTransitionException e) {</i><i> /* Why this can happen? Ask God not me. */ </i><i> }</i><i>try { tableLock.release(); } </i><i>catch (IOException e) { </i><i> LOG("Can't release lock”, e); </i><i>} </i> |
4 — Приоритет развития функции
Я думаю, что все разработчики программного обеспечения согласятся с этим. Это также называется Tech Debt, и я не могу представить себе лучшего примера, чем банкротство Knight Capital, которое было связано с конфигурацией и экспериментальным кодом.
Вывод
Все ошибки сложно воспроизвести, но лучший модульный тест определенно их поймает, это также показывает, что модульный / интеграционный тест, выполненный во многих системах, не является сценарием тестирования, таким как отключение и возвращение сервиса и его влияние на систему.
Исходя из приведенного выше примера, будет выглядеть, как будто все ошибки произошли из-за исключительной ситуации с проверкой Java, но она не отличается в другой системе, такой как C / C ++, которая не проверяла, но все не проверено, и ответственность за ее проверку в различных местах лежит на разработчику.
На языке примечаний без системы типов, такой как Python, очень легко писать код, который будет ломаться во время выполнения, и если вам действительно не повезет, то в коде обработки ошибок будет какая-то ошибка типа, и он будет протестирован в производстве.
Кроме того, почти все продукты будут иметь некоторую интеграцию с инструментами статического кода (findbugs), но эти инструменты не придают большего значения такому анти-шаблону обработки ошибок.
Ссылка на проблемы, упомянутые в статье
Пожалуйста, расскажите о большем количестве анти-паттернов, которые вы видели в производственной системе.
До тех пор Счастливое юнит-тестирование.
| Посмотрите оригинальную статью здесь: Простое тестирование может предотвратить большинство критических ошибок
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |