Tuple — очень мощная конструкция в языке программирования, она позволяет создавать последовательность конечных элементов. Элементы в кортеже могут быть различного типа и очень легко объявляться как («что-то», 1, новый Date ())
Хорошая вещь в кортеже — вы должны выбирать только тип данных элемента, а не имя.
Информатика имеет 2 трудные проблемы: аннулирование кэша и присвоение имен.
Кортеж помогает с проблемой именования.
Ничто не приходит бесплатно, и у каждой вещи есть свой компромисс. В этом блоге я поделюсь темной стороной кортежа. Я возьму, например, кортеж Scala.
Каковы разные способы реализации кортежа?
Класс с массивом объектов
Это первый вариант, который мне приходит в голову, это хорошо для гибкости, но плохо для производительности, как
- проверки типа дорогие
- и имеет накладные расходы на проверку индекса массива.
- Параметр имеет тип объекта, поэтому оказывает давление на память как для чтения, так и для записи.
- дорого сделать неизменным. Мы поговорим о неизменности позже.
- нет типов, поэтому сериализация будет большой накладной
Класс с фиксированным номером параметра.
Это лучше, чем первый, но у него тоже мало проблем
- Параметр имеет тип объекта, поэтому оказывает давление на память
- Изменяемый, если фреймворк или библиотека не генерируют код или не поддерживают объекты с фиксированным макетом, такие как (Tuple, Tuple2, Tuple3…)
- Затраты на сериализацию из-за типа объекта.
Scala использует фиксированное число параметров подхода.
В отсутствие Tuple выбор бедного человека состоял в том, чтобы создать класс с числом переменных экземпляра N и дать им правильный тип, в scala есть класс Case, основанный на старой школьной мысли.
Давайте сравним класс Tuple и Case. Я возьму кортеж с 4 параметрами и 2 из них являются примитивными (Int & Double).
Кортеж: (String, String, Int, Double)
Класс case : класс case Trade (символ: String, обмен: String, кол-во: Int, цена: Double)
По структуре они одинаковы и могут заменять друг друга.
Тест памяти
Бенчмарк создает N экземпляра класса tuple / case и помещает его в коллекцию и измеряет распределение памяти.
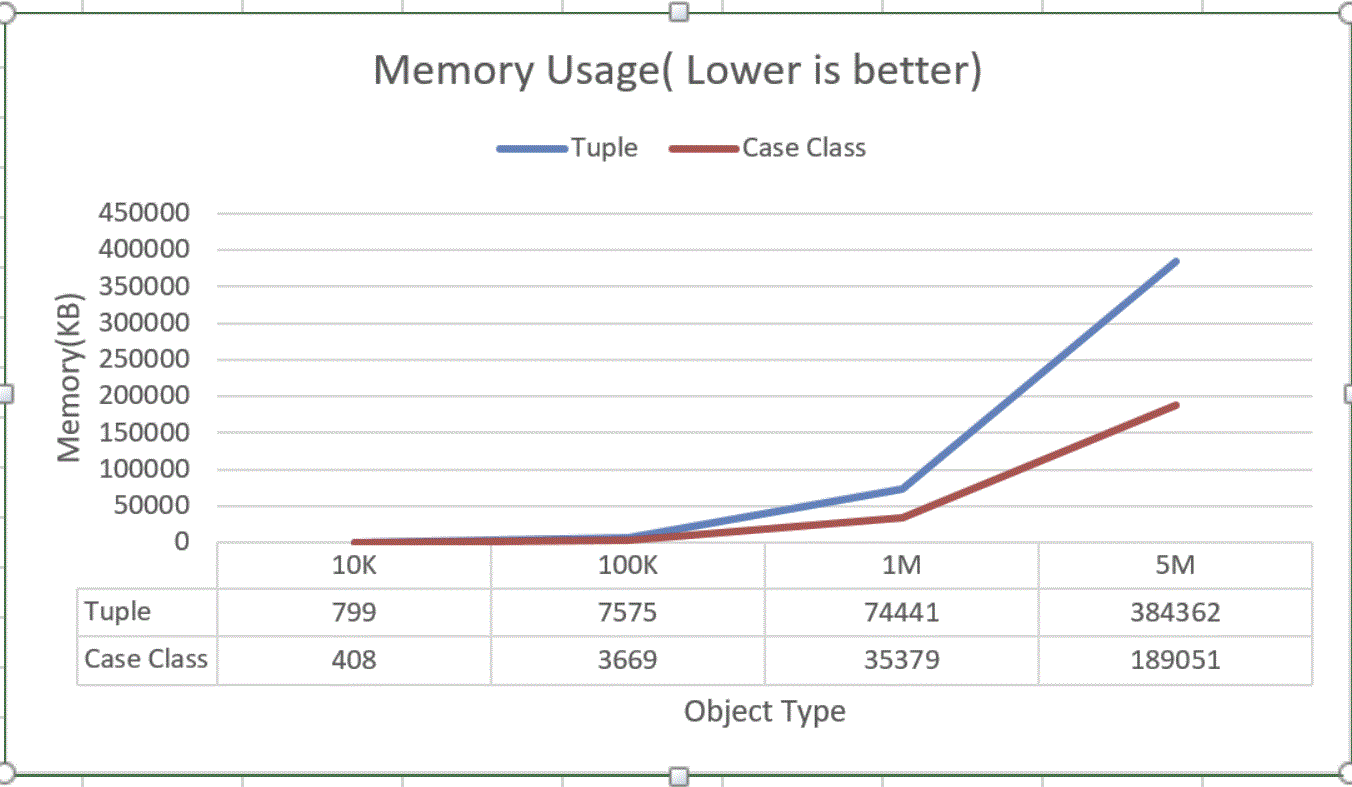
Использование памяти для Tuple удваивается, для 5 миллионов объектный кортеж занимает 384 МБ, а класс case занимает всего 189 МБ.
Читать тест производительности
В этом тесте объекты распределяются один раз, и к ним осуществляется базовая агрегация.
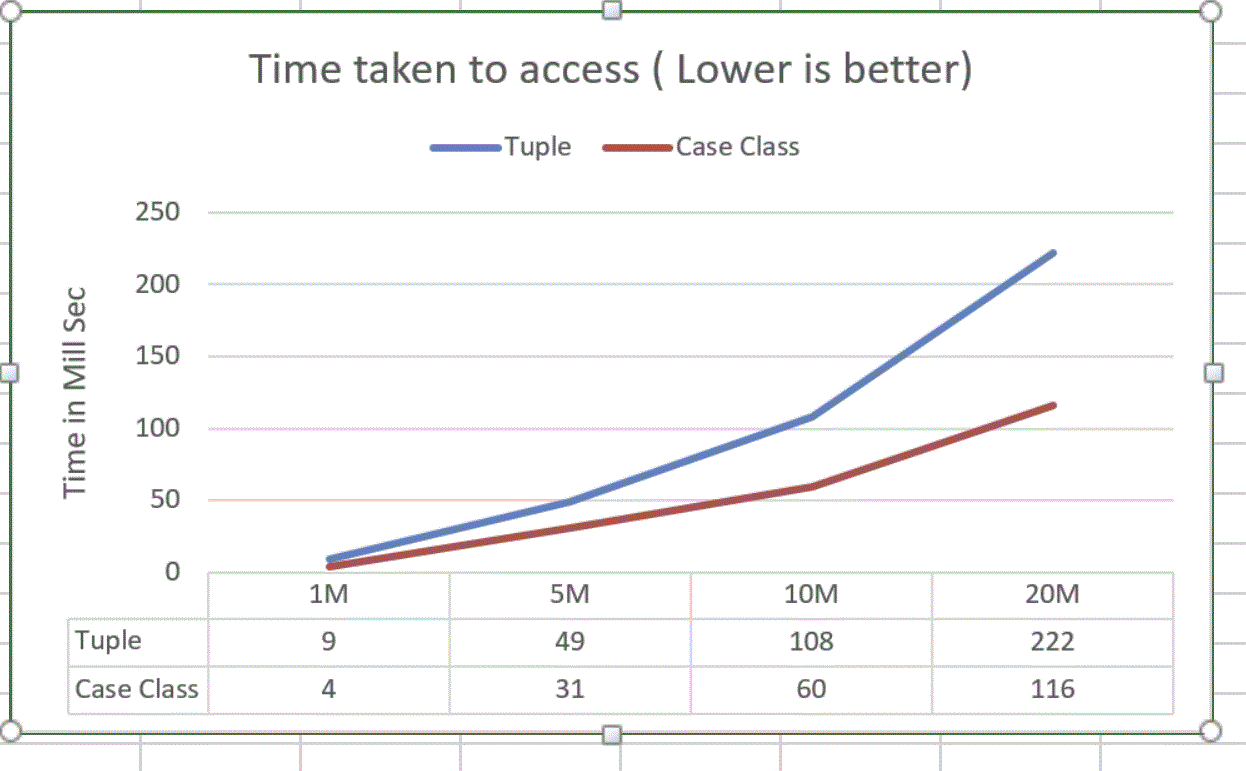
На этом графике показано время, необходимое для суммирования значения Double для объекта 1 миллион, 5 миллионов и т. Д.
Чтение из кортежа происходит медленно, оно занимает вдвое больше времени.
Одна вещь, которая не показана в этой диаграмме, это давление памяти, создаваемое во время чтения. Кортеж оказывает давление на память во время чтения.
Эти цифры показывают, что Tuple не подходит как для памяти, так и для процессора.
Давайте углубимся в код, сгенерированный как для кортежа, так и для класса case, чтобы понять, почему мы видим эти числа.
Я поставлю код Java, который генерируется компилятором Scala.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
/* Code for (String,String,Int,Double)*/public class Tuple4<T1, T2, T3, T4> implements Product4<T1, T2, T3, T4>, Serializable{ private final T1 _1; public T1 _1(){return (T1)this._1;} public T2 _2(){ return (T2)this._2; } public T3 _3(){ return (T3)this._3; } public T4 _4(){ return (T4)this._4; }} |
Scala хорошо делает, чтобы пометить значения как final, поэтому он получает некоторую эффективность чтения от этого, но все, что выбрасывается при создании типа объекта и выполнении приведения типа во время выполнения при каждом запросе значения.
Код класса дела
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
/* Code for case class Trade(symbol: String, exchange: String, qty: Int, price: Double)*/public class Trade implements Product, Serializable{ private final String symbol; public double price(){ return this.price; } public int qty(){ return this.qty; } public String exchange(){ return this.exchange; } public String symbol(){ return this.symbol; } } |
Для кода caseclass scala по-прежнему использует примитивный тип, что дает всю эффективность использования памяти и процессора.
Spark является очень популярной средой крупномасштабной обработки данных, и большая часть производственного кода написана с использованием Tuple.
Преобразование на основе кортежей создает большую нагрузку на ГХ и влияет на загрузку ЦП.
Поскольку кортеж полностью основан на типе объекта, он также влияет на передачу по сети.
Информация о типе очень важна для оптимизации, и именно поэтому Spark 2 основан на наборе данных, который имеет компактное представление.
Поэтому в следующий раз в поисках быстрого улучшения поменяйте Tuple на case case.
Код, используемый для бенчмаркинга доступен @ githib
| Смотреть оригинальную статью здесь: производительность Scala Tuple
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |