Эта статья является частью нашего курса Академии под названием Основы параллелизма Java .
В этом курсе вы погрузитесь в магию параллелизма. Вы познакомитесь с основами параллелизма и параллельного кода и узнаете о таких понятиях, как атомарность, синхронизация и безопасность потоков. Проверьте это здесь !
Содержание
1. Введение
В этой статье обсуждается тема производительности для многопоточных приложений. Определив термины производительность и масштабируемость, мы подробнее рассмотрим закон Амдала. Далее в курсе мы увидим, как мы можем уменьшить конфликт блокировок, применяя различные методы, которые продемонстрированы на примерах кода.
2. Производительность
Потоки могут быть использованы для повышения производительности приложений. Причиной этого может быть то, что у нас есть несколько процессоров или процессорных ядер. Каждое ядро ЦП может работать над своей собственной задачей, следовательно, разделение большой задачи на серию небольших задач, выполняемых независимо друг от друга, может улучшить общее время выполнения приложения. Примером такого улучшения производительности может быть приложение, которое изменяет размеры изображений, которые лежат в структуре папок на жестком диске. Однопоточный подход будет просто перебирать все файлы и масштабировать каждое изображение за другим. Если у нас есть ЦП с более чем одним ядром, процесс изменения размера будет использовать только одно из доступных ядер. Многопоточный подход может, например, позволить потоку-производителю сканировать файловую систему и добавлять все найденные файлы в очередь, которая обрабатывается группой рабочих потоков. Когда у нас столько рабочих потоков, сколько у нас ядер ЦП, мы гарантируем, что каждому ядру ЦП есть чем заняться, пока все изображения не будут обработаны.
Другой пример, когда многопоточность может улучшить общую производительность приложения, — это варианты использования с большим временем ожидания ввода-вывода. Давайте предположим, что мы хотим написать приложение, которое отражает весь веб-сайт в виде HTML-файлов на наш жесткий диск. Начиная с одной страницы, приложение должно следовать всем ссылкам, которые указывают на один и тот же домен (или часть URL). Поскольку время между отправкой запроса на удаленный веб-сервер и до момента получения всех данных может быть длительным, мы можем распределить работу по нескольким потокам. Один или несколько потоков могут анализировать полученные HTML-страницы и помещать найденные ссылки в очередь, в то время как другие потоки отправляют запросы на веб-сервер, а затем ждут ответа. В этом случае мы используем время ожидания для новых запрашиваемых страниц с разбором уже полученных. В отличие от предыдущего примера, это приложение может даже повысить производительность, если мы добавим больше потоков, чем у нас будет процессорных ядер.
Эти два примера показывают, что производительность означает выполнение большей работы в более короткие сроки. Это, конечно, классическое понимание термина производительности. Но использование потоков также может улучшить отзывчивость наших приложений. Представьте себе простое приложение с графическим интерфейсом с формой ввода и кнопкой «Процесс». Когда пользователь нажимает кнопку, приложение должно отображать нажатую кнопку (кнопка должна блокироваться, как если бы она была нажата и снова поднималась при отпускании мыши), и должна быть выполнена фактическая обработка входных данных. Если эта обработка занимает больше времени, однопоточное приложение не может реагировать на дальнейший ввод данных пользователем, т.е. нам нужен дополнительный поток, который обрабатывает события из операционной системы, такие как щелчки мыши или движения указателя мыши.
Масштабируемость означает способность программы повышать производительность, добавляя к ней дополнительные ресурсы. Представьте, что нам нужно изменить размер огромного количества изображений. Поскольку количество ядер ЦП нашего текущего компьютера ограничено, добавление большего количества потоков не повышает производительность. Производительность может даже ухудшиться, поскольку планировщику приходится управлять большим количеством потоков, а создание и отключение потоков также требует затрат ресурсов процессора.
2.1. Закон Амдала
Последний раздел показал, что в некоторых случаях добавление новых ресурсов может улучшить общую производительность нашего приложения. Чтобы вычислить, какую производительность может получить наше приложение, когда мы добавляем дополнительные ресурсы, нам необходимо определить части программы, которые должны запускаться сериализованно / синхронизировано, и части программы, которые могут работать параллельно. Если мы обозначим часть программы, которая должна выполняться синхронизированно с B (например, количество выполненных строк синхронизировано), и если мы обозначим число доступных процессоров через n, то закон Амдала позволяет нам вычислить верхний предел для ускорения наше приложение может достичь:
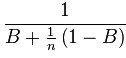
фигура 1
Если мы позволим n приблизиться к бесконечности, член (1-B) / n сходится к нулю. Следовательно, мы можем пренебречь этим термином, и верхний предел ускорения сходится к 1 / B, где B — это доля времени выполнения программы до оптимизации, проводимой в непараллелизуемом коде. Если B составляет, например, 0,5, что означает, что половина программы не может быть распараллелена, обратное значение 0,5 равно 2; следовательно, даже если мы добавим неограниченное количество процессоров в наше приложение, мы получим ускорение только примерно на два. Теперь давайте предположим, что мы можем переписать код так, чтобы только 0,25 времени выполнения программы проводилось в синхронизированных блоках. Теперь обратное значение 0,25 равно 4, что означает, что мы создали приложение, которое будет работать с большим количеством процессоров примерно в четыре раза быстрее, чем с одним процессором.
С другой стороны, мы также можем использовать закон Амдала для вычисления доли времени выполнения программы, которая должна быть синхронизирована для достижения заданного ускорения. Если мы хотим добиться ускорения примерно до 100, обратное значение равно 0,01, что означает, что мы должны потратить только около 1 процента времени выполнения в синхронизированном коде.
Подводя итог выводам из закона Амдала, можно сделать вывод, что максимальная скорость, которую программа может получить за счет использования дополнительного процессора, ограничена обратной величиной доли времени, которое программа проводит в синхронизированных частях кода. Хотя на практике не всегда легко вычислить эту долю, даже если вы задумываетесь о крупных бизнес-приложениях, закон подсказывает нам, что мы должны очень тщательно продумать синхронизацию и сохранить части времени выполнения программы. маленький, который должен быть сериализован.
2.2. Влияние производительности потоков
Записи этой статьи до этого момента указывают, что добавление дополнительных потоков в приложение может улучшить производительность и скорость отклика. Но с другой стороны, это не бесплатно. Потоки всегда оказывают некоторое влияние на производительность сами.
Первое влияние на производительность — это создание самого потока. Это занимает некоторое время, так как JVM должна получить ресурсы для потока из базовой операционной системы и подготовить структуры данных в планировщике, который решает, какой поток выполнять следующим.
Если вы используете столько потоков, сколько у вас процессорных ядер, то каждый поток может работать на своем собственном процессоре и может прерываться не так часто. На практике операционная система может потребовать, конечно, своих собственных вычислений во время работы вашего приложения; следовательно, даже в этом случае потоки прерываются и должны ждать, пока операционная система не позволит им снова работать. Ситуация становится еще хуже, когда вам нужно использовать больше потоков, чем у вас процессорных ядер. В этом случае планировщик может прервать ваш поток, чтобы позволить другому потоку выполнить свой код. В такой ситуации текущее состояние запущенного потока должно быть сохранено, состояние запланированного потока, который должен выполняться следующим, должно быть восстановлено. Кроме того, сам планировщик должен выполнить некоторые обновления своих внутренних структур данных, которые снова используют мощность процессора. Все вместе это означает, что каждое переключение контекста с одного потока на другой требует затрат ресурсов процессора и, следовательно, приводит к снижению производительности по сравнению с однопоточным решением.
Другой ценой наличия нескольких потоков является необходимость синхронизации доступа к общим структурам данных. Помимо использования синхронизированного ключевого слова, мы также можем использовать volatile для обмена данными между несколькими потоками. Если более чем один поток конкурирует за общие данные, мы имеем дело с конфликтом. Затем JVM должна решить, какой поток выполнять следующим. Если это не текущий поток, вводятся затраты на переключение контекста. Затем текущий поток должен ждать, пока он не сможет получить блокировку. JVM может решить, как реализовать это ожидание. Когда ожидаемое время до получения блокировки мало, то ожидание вращения, то есть попытка получить блокировку снова и снова, может быть более эффективным по сравнению с необходимым переключением контекста при приостановке потока и разрешении другому потоку занимать ЦП. Возвращение ожидающего потока к выполнению влечет за собой другое переключение контекста и добавляет дополнительные затраты к конфликту блокировки.
Поэтому разумно уменьшить количество переключений контекста, которые необходимы из-за конфликта блокировок. В следующем разделе описываются два подхода к уменьшению этой конкуренции.
2,3. Блокировка раздора
Как мы видели в предыдущем разделе, два или более потока, конкурирующих за одну блокировку, вводят дополнительные тактовые циклы, поскольку конфликт может заставить планировщика либо позволить одному потоку вращаться в ожидании блокировки, либо позволить другому потоку занять процессор со стоимостью два переключателя контекста. В некоторых случаях конкуренция за блокировку может быть уменьшена путем применения одного из следующих методов:
- Размах замка уменьшен.
- Количество раз получения определенной блокировки уменьшается.
- Использование аппаратных поддерживаемых оптимистических операций блокировки вместо синхронизации.
- По возможности избегайте синхронизации
- Избегайте объединения объектов
2.3.1 Сокращение области
Первый метод может быть применен, когда замок удерживается дольше, чем необходимо. Часто это может быть достигнуто путем перемещения одной или нескольких строк из синхронизированного блока, чтобы сократить время, в течение которого текущий поток удерживает блокировку. Меньшее количество строк кода для выполнения ранее текущего потока может покинуть синхронизированный блок, и тем самым позволить другим потокам получить блокировку. Это также согласуется с Законом Амдала, поскольку мы сокращаем долю времени выполнения, которое тратится в синхронизированных блоках.
Чтобы лучше понять эту технику, взгляните на следующий исходный код:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
public class ReduceLockDuration implements Runnable { private static final int NUMBER_OF_THREADS = 5; private static final Map<String, Integer> map = new HashMap<String, Integer>(); public void run() { for (int i = 0; i < 10000; i++) { synchronized (map) { UUID randomUUID = UUID.randomUUID(); Integer value = Integer.valueOf(42); String key = randomUUID.toString(); map.put(key, value); } Thread.yield(); } } public static void main(String[] args) throws InterruptedException { Thread[] threads = new Thread[NUMBER_OF_THREADS]; for (int i = 0; i < NUMBER_OF_THREADS; i++) { threads[i] = new Thread(new ReduceLockDuration()); } long startMillis = System.currentTimeMillis(); for (int i = 0; i < NUMBER_OF_THREADS; i++) { threads[i].start(); } for (int i = 0; i < NUMBER_OF_THREADS; i++) { threads[i].join(); } System.out.println((System.currentTimeMillis()-startMillis)+"ms"); }} |
В этом примере приложения мы позволяем пяти потокам конкурировать за доступ к общей карте. Чтобы позволить только одному потоку одновременно обращаться к карте, код, который обращается к карте и добавляет новую пару ключ / значение, помещается в синхронизированный блок. Когда мы более внимательно посмотрим на блок, мы увидим, что вычисление ключа, а также преобразование примитивного целого числа 42 в объект типа Integer не должны быть синхронизированы. Концептуально они относятся к коду, который обращается к карте, но они локальны для текущего потока, и экземпляры не изменяются другими потоками. Следовательно, мы можем переместить их из синхронизированного блока:
|
01
02
03
04
05
06
07
08
09
10
11
|
public void run() { for (int i = 0; i < 10000; i++) { UUID randomUUID = UUID.randomUUID(); Integer value = Integer.valueOf(42); String key = randomUUID.toString(); synchronized (map) { map.put(key, value); } Thread.yield(); }} |
Уменьшение синхронизированного блока влияет на время выполнения, которое можно измерить. На моей машине время выполнения всего приложения уменьшено с 420 мс до 370 мс для версии с минимизированным синхронизированным блоком. Это сокращает время выполнения на 11%, просто перемещая три строки кода из синхронизированного блока. Оператор Thread.yield() введен для того, чтобы вызвать больше переключений контекста, поскольку этот вызов метода сообщает JVM, что текущий поток готов передать процессор другому ожидающему потоку. Это снова вызывает больше конфликтов блокировки, так как в противном случае один поток может работать на процессоре слишком долго без какого-либо конкурирующего потока.
2.3.2 Блокировка разделения
Другой способ уменьшить конфликт блокировок — это разделить один замок на несколько блокировок меньшего объема. Этот метод может быть применен, если у вас есть один замок для защиты различных аспектов вашего приложения. Предположим, мы хотим собрать некоторые статистические данные о нашем приложении и реализовать простой класс счетчика, который содержит для каждого аспекта примитивную переменную счетчика. Поскольку наше приложение является многопоточным, мы должны синхронизировать доступ к этим переменным, поскольку они доступны из разных параллельных потоков. Самый простой способ сделать это — использовать ключевое слово synchronized в сигнатуре метода для каждого метода Counter:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
public static class CounterOneLock implements Counter { private long customerCount = 0; private long shippingCount = 0; public synchronized void incrementCustomer() { customerCount++; } public synchronized void incrementShipping() { shippingCount++; } public synchronized long getCustomerCount() { return customerCount; } public synchronized long getShippingCount() { return shippingCount; }} |
Этот подход также означает, что каждое приращение счетчика блокирует весь экземпляр счетчика. Другие потоки, которые хотят увеличить другую переменную, должны ждать, пока эта единственная блокировка не будет снята. В этом случае более эффективно использовать отдельные блокировки для каждого счетчика, как в следующем примере:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
public static class CounterSeparateLock implements Counter { private static final Object customerLock = new Object(); private static final Object shippingLock = new Object(); private long customerCount = 0; private long shippingCount = 0; public void incrementCustomer() { synchronized (customerLock) { customerCount++; } } public void incrementShipping() { synchronized (shippingLock) { shippingCount++; } } public long getCustomerCount() { synchronized (customerLock) { return customerCount; } } public long getShippingCount() { synchronized (shippingLock) { return shippingCount; } }} |
В этой реализации представлены два отдельных объекта синхронизации, по одному для каждого счетчика. Следовательно, поток, пытающийся увеличить количество клиентов в нашей системе, должен конкурировать только с другими потоками, которые также увеличивают количество клиентов, но не должен конкурировать с потоками, пытающимися увеличить количество отгрузок.
Используя следующий класс, мы можем легко измерить влияние этого разделения блокировки:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
public class LockSplitting implements Runnable { private static final int NUMBER_OF_THREADS = 5; private Counter counter; public interface Counter { void incrementCustomer(); void incrementShipping(); long getCustomerCount(); long getShippingCount(); } public static class CounterOneLock implements Counter { ... } public static class CounterSeparateLock implements Counter { ... } public LockSplitting(Counter counter) { this.counter = counter; } public void run() { for (int i = 0; i < 100000; i++) { if (ThreadLocalRandom.current().nextBoolean()) { counter.incrementCustomer(); } else { counter.incrementShipping(); } } } public static void main(String[] args) throws InterruptedException { Thread[] threads = new Thread[NUMBER_OF_THREADS]; Counter counter = new CounterOneLock(); for (int i = 0; i < NUMBER_OF_THREADS; i++) { threads[i] = new Thread(new LockSplitting(counter)); } long startMillis = System.currentTimeMillis(); for (int i = 0; i < NUMBER_OF_THREADS; i++) { threads[i].start(); } for (int i = 0; i < NUMBER_OF_THREADS; i++) { threads[i].join(); } System.out.println((System.currentTimeMillis() - startMillis) + "ms"); }} |
На моей машине реализация с одной единственной блокировкой занимает в среднем около 56 мс, тогда как вариант с двумя отдельными блокировками занимает около 38 мс. Это сокращение примерно на 32 процента.
Другое возможное улучшение — еще больше разделить блокировки, различая блокировки чтения и записи. Например, класс Counter предоставляет методы для чтения и записи значения счетчика. Хотя чтение текущего значения может выполняться несколькими потоками параллельно, все операции записи должны быть сериализованы. Пакет java.util.concurrent предоставляет готовую реализацию такого ReadWriteLock .
Реализация ReentrantReadWriteLock управляет двумя отдельными блокировками. Один для доступа для чтения и один для доступа для записи. И блокировка чтения и записи предлагают методы для блокировки и разблокировки. Блокировка записи получается только при отсутствии блокировки чтения. Блокировка чтения может быть получена более чем в потоке считывателя, пока блокировка записи не получена. В демонстрационных целях ниже показана реализация класса счетчика с использованием ReadWriteLock :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
public static class CounterReadWriteLock implements Counter { private final ReentrantReadWriteLock customerLock = new ReentrantReadWriteLock(); private final Lock customerWriteLock = customerLock.writeLock(); private final Lock customerReadLock = customerLock.readLock(); private final ReentrantReadWriteLock shippingLock = new ReentrantReadWriteLock(); private final Lock shippingWriteLock = shippingLock.writeLock(); private final Lock shippingReadLock = shippingLock.readLock(); private long customerCount = 0; private long shippingCount = 0; public void incrementCustomer() { customerWriteLock.lock(); customerCount++; customerWriteLock.unlock(); } public void incrementShipping() { shippingWriteLock.lock(); shippingCount++; shippingWriteLock.unlock(); } public long getCustomerCount() { customerReadLock.lock(); long count = customerCount; customerReadLock.unlock(); return count; } public long getShippingCount() { shippingReadLock.lock(); long count = shippingCount; shippingReadLock.unlock(); return count; }} |
Все обращения к чтению защищаются установлением блокировки чтения, в то время как все доступы к записи защищаются соответствующей блокировкой записи. В случае, если приложение использует гораздо больше чтения, чем доступа для записи, реализация такого типа может даже получить большее улучшение производительности, чем предыдущая, поскольку все потоки чтения могут получать доступ к методу getter параллельно.
2.3.3 Блокировка чередования
В предыдущем примере показано, как разделить одну блокировку на две отдельные блокировки. Это позволяет конкурирующим потокам получать только блокировку, которая защищает структуры данных, которыми они хотят манипулировать. С другой стороны, этот метод также увеличивает сложность и риск мертвых блокировок, если они не реализованы должным образом.
С другой стороны, чередование замков — это метод, аналогичный разделению замков. Вместо разделения одной блокировки, которая защищает разные части или аспекты кода, мы используем разные блокировки для разных значений. Класс ConcurrentHashMap из пакета java.util.concurrent JDK использует эту технику для повышения производительности приложений, которые в значительной степени зависят от HashMap . В отличие от синхронизированной версии java.util.HashMap , ConcurrentHashMap использует 16 различных блокировок. Каждый замок защищает только 1/16 доступных хэш-контейнеров. Это позволяет различным потокам, которые хотят вставлять данные в разные секции доступных хэш-блоков, делать это одновременно, поскольку их работа защищена различными блокировками. С другой стороны, это также создает проблему для получения более одной блокировки для определенных операций. Если вы хотите скопировать, например, всю Карту, необходимо получить все 16 блокировок.
2.3.4 Атомные операции
Другой способ уменьшить конфликт блокировок — использовать так называемые атомарные операции. Этот принцип объяснен и оценен более подробно в одной из следующих статей. Пакет java.util.concurrent предлагает поддержку атомарных операций для некоторых примитивных типов данных. Атомарные операции реализуются с помощью так называемой операции сравнения и замены (CAS), предоставляемой процессором. Инструкция CAS обновляет значение определенного регистра, только если текущее значение равно предоставленному значению. Только в этом случае старое значение заменяется новым.
Этот принцип можно использовать для оптимистического увеличения переменной. Если мы предположим, что наш поток знает текущее значение, он может попытаться увеличить его с помощью операции CAS. Если окажется, что другой поток тем временем увеличил значение, и наше значение больше не является текущим, мы запрашиваем текущее значение и пробуем снова. Это можно сделать до тех пор, пока мы успешно не увеличим счетчик. Преимущество этой реализации, хотя нам может потребоваться некоторое вращение, состоит в том, что нам не нужна какая-либо синхронизация.
Следующая реализация класса Counter использует подход атомарных переменных и не использует синхронизированный блок:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
public static class CounterAtomic implements Counter { private AtomicLong customerCount = new AtomicLong(); private AtomicLong shippingCount = new AtomicLong(); public void incrementCustomer() { customerCount.incrementAndGet(); } public void incrementShipping() { shippingCount.incrementAndGet(); } public long getCustomerCount() { return customerCount.get(); } public long getShippingCount() { return shippingCount.get(); }} |
По сравнению с классом CounterSeparateLock общее среднее время выполнения уменьшается с 39 до 16 мс. Это сокращение времени выполнения примерно на 58 процентов.
2.3.5 Избегайте горячих точек
Типичная реализация списка будет управлять внутренним счетчиком, который содержит количество элементов в списке. Этот счетчик обновляется каждый раз, когда новый элемент добавляется в список или удаляется из списка. При использовании в однопоточном приложении эта оптимизация является разумной, поскольку операция size() в списке будет возвращать ранее вычисленное значение напрямую. Если список не содержит количество элементов в списке, операция size() должна будет выполнить итерацию по всем элементам, чтобы вычислить его.
Что является общей оптимизацией во многих структурах данных, может стать проблемой в многопоточных приложениях. Предположим, мы хотим поделиться экземпляром этого списка с кучей потоков, которые вставляют и удаляют элементы из списка и запрашивают его размер. Переменная counter теперь также является общим ресурсом, и весь доступ к ее значению должен быть синхронизирован. Счетчик стал горячей точкой в реализации.
Следующий фрагмент кода демонстрирует эту проблему:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
public static class CarRepositoryWithCounter implements CarRepository { private Map<String, Car> cars = new HashMap<String, Car>(); private Map<String, Car> trucks = new HashMap<String, Car>(); private Object carCountSync = new Object(); private int carCount = 0; public void addCar(Car car) { if (car.getLicencePlate().startsWith("C")) { synchronized (cars) { Car foundCar = cars.get(car.getLicencePlate()); if (foundCar == null) { cars.put(car.getLicencePlate(), car); synchronized (carCountSync) { carCount++; } } } } else { synchronized (trucks) { Car foundCar = trucks.get(car.getLicencePlate()); if (foundCar == null) { trucks.put(car.getLicencePlate(), car); synchronized (carCountSync) { carCount++; } } } } } public int getCarCount() { synchronized (carCountSync) { return carCount; } }} |
Реализация CarRepository содержит два списка: один для легковых автомобилей и один для грузовых автомобилей. Он также предоставляет метод, который возвращает количество легковых и грузовых автомобилей, которые в настоящее время находятся в обоих списках. В качестве оптимизации он увеличивает внутренний счетчик каждый раз, когда новый автомобиль добавляется в один из двух списков. Эта операция должна быть синхронизирована с выделенным экземпляром carCountSync . Та же самая синхронизация используется, когда возвращается значение счетчика.
Чтобы избавиться от этой дополнительной синхронизации, CarRepository мог бы быть реализован путем исключения дополнительного счетчика и вычисления общего количества автомобилей каждый раз, когда значение запрашивается с помощью вызова getCarCount() :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
public static class CarRepositoryWithoutCounter implements CarRepository { private Map<String, Car> cars = new HashMap<String, Car>(); private Map<String, Car> trucks = new HashMap<String, Car>(); public void addCar(Car car) { if (car.getLicencePlate().startsWith("C")) { synchronized (cars) { Car foundCar = cars.get(car.getLicencePlate()); if (foundCar == null) { cars.put(car.getLicencePlate(), car); } } } else { synchronized (trucks) { Car foundCar = trucks.get(car.getLicencePlate()); if (foundCar == null) { trucks.put(car.getLicencePlate(), car); } } } } public int getCarCount() { synchronized (cars) { synchronized (trucks) { return cars.size() + trucks.size(); } } }} |
Теперь нам нужно синхронизироваться со списком легковых и грузовых автомобилей в getCarCount() и вычислить размер, но дополнительная синхронизация при добавлении новых автомобилей может быть исключена.
2.3.6 Избегайте объединения объектов
В первых версиях создания объекта Java VM использование оператора new было дорогой операцией. Это привело многих программистов к общей схеме объединения объектов. Вместо того, чтобы создавать определенные объекты снова и снова, они создавали пул этих объектов, и каждый раз, когда требовался экземпляр, один из них отбирался из пула. После использования объекта он был возвращен в пул и может использоваться другим потоком.
То, что имеет смысл на первый взгляд, может быть проблемой при использовании в многопоточных приложениях. Теперь пул объектов распределяется между всеми потоками, и доступ к объектам в пуле должен быть синхронизирован. Эти дополнительные накладные расходы на синхронизацию теперь могут превышать затраты на создание самого объекта. Это даже верно, если учесть дополнительные затраты на сборщик мусора для сбора вновь созданных экземпляров объектов.
Как и в случае всей оптимизации производительности, этот пример еще раз показывает, что каждое возможное улучшение должно быть тщательно измерено перед применением. Оптимизации, которые, на первый взгляд, имеют смысл, могут оказаться даже узкими местами производительности, если они не реализованы правильно.