ПОЧЕМУ LOOM?
Одним из драйверов потоков в Java 8 было параллельное программирование. В своем потоковом конвейере вы указываете, что вы хотите сделать, и ваши задачи автоматически распределяются на доступные процессоры:

|
1
2
3
4
5
|
var result = myData .parallelStream() .map(someBusyOperation) .reduce(someAssociativeBinOp) .orElse(someDefault); |
Параллельные потоки прекрасно работают, когда структура данных дешева, чтобы разделить на части, и операции поддерживают занятость процессоров. Вот для чего он был разработан.
Но это не поможет вам, если ваша рабочая нагрузка состоит из задач, которые в основном блокируются. Это типичное веб-приложение, обслуживающее множество запросов, причем каждый запрос тратит большую часть времени на ожидание результата службы REST, запроса к базе данных и т. Д.
В 1998 году было удивительно, что веб-сервер Sun Java (предшественник Tomcat) выполнял каждый запрос в отдельном потоке, а не в процессе ОС. Таким образом, он мог обслуживать тысячи одновременных запросов! В наше время это не так удивительно. Каждый поток занимает значительное количество памяти, и на обычном сервере не может быть миллионов потоков.
Вот почему современная мантра серверного программирования: «Никогда не блокируйте!» Вместо этого вы указываете, что должно произойти после того, как данные станут доступны.
Этот стиль асинхронного программирования отлично подходит для серверов, позволяя им легко поддерживать миллионы одновременных запросов. Это не так здорово для программистов.
Вот асинхронный запрос с HttpClient API:
|
1
2
3
4
5
6
|
HttpClient.newBuilder() .build() .sendAsync(request, HttpResponse.BodyHandlers.ofString()) .thenAccept(response -> . . .); .thenApply(. . .); .exceptionally(. . .); |
То, что мы обычно достигаем с помощью операторов, теперь кодируется как вызовы методов. Если бы мы любили этот стиль программирования, у нас не было бы операторов на нашем языке программирования и весело писать код на Лиспе.

Такие языки, как JavaScript и Kotlin, предоставляют нам «асинхронные» методы, где мы пишем операторы, которые затем преобразуются в вызовы методов, подобные тем, которые вы только что видели. Это хорошо, за исключением того, что теперь есть два вида методов — обычные и преобразованные. И вы не можете смешивать их («красная таблетка / синяя таблетка»).
Project Loom берет свое руководство от таких языков, как Erlang и Go, где блокировка не имеет большого значения. Вы запускаете задачи в «волокнах», «легких потоках» или «виртуальных потоках». Название обсуждается, но я предпочитаю «волокно», поскольку оно хорошо обозначает тот факт, что несколько нитей выполняются в потоке носителя. Волокна припаркованы, когда происходит операция блокировки, такая как ожидание блокировки или ввода / вывода. Парковка относительно дешевая. Несущая нить может поддерживать тысячу волокон, если каждое из них припарковано большую часть времени.
Имейте в виду, что Project Loom не решает всех проблем параллелизма. Он ничего не делает для вас, если у вас сложные вычислительные задачи и вы хотите, чтобы все процессорные ядра были заняты. Это не поможет вам с пользовательскими интерфейсами, которые используют один поток (для сериализации доступа к структурам данных, которые не являются потокобезопасными). Продолжайте использовать AsyncTask / SwingWorker / JavaFX Task для этого варианта использования. Project Loom полезен, когда у вас много задач, которые проводят большую часть своего времени в блокировании.
NB. Если вы были здесь в течение очень долгого времени, вы можете помнить, что ранние версии Java имели «зеленые потоки», которые были сопоставлены с потоками ОС. Однако есть принципиальная разница. Когда зеленая нить блокировалась, ее несущая нить также блокировалась, что препятствовало продвижению всех других зеленых нитей в той же самой несущей нити.
ПИЩАЯ ШИНЫ
На данный момент Project Loom все еще очень исследовательский. API постоянно меняется, поэтому будьте готовы адаптироваться к последней версии API, когда вы попробуете код после праздников.
Вы можете загрузить двоичные файлы Project Loom по адресу http://jdk.java.net/loom/ , но они обновляются нечасто. Однако на Linux-машине или виртуальной машине легко создать самую последнюю версию:
|
1
2
3
4
5
|
git clone https://github.com/openjdk/loomcd loom git checkout fiberssh configure make images |
В зависимости от того, что вы уже установили, у вас может быть несколько сбоев в configure , но сообщения сообщают вам, какие пакеты вам нужно установить, чтобы вы могли продолжить.
В текущей версии API волокно или, как его сейчас называют, виртуальный поток, представляется как объект класса Thread . Вот три способа производства волокон. Во-первых, существует новый фабричный метод, который может создавать потоки ОС или виртуальные потоки:
|
1
|
Thread thread = Thread.newThread(taskname, Thread.VIRTUAL, runnable); |
Если вам нужно больше настроек, есть API для конструктора:
|
1
2
3
4
5
6
|
Thread thread = Thread.builder() .name(taskname) .virtual() .priority(Thread.MAX_PRIORITY) .task(runnable) .build(); |
Однако создание потоков вручную в течение некоторого времени считалось плохой практикой, поэтому вам, вероятно, не следует делать ни одно из этих действий. Вместо этого используйте исполнителя с фабрикой потоков:
|
1
2
|
ThreadFactory factory = Thread.builder().virtual().factory();ExecutorService exec = Executors.newFixedThreadPool(NTASKS, factory); |
Теперь семейный фиксированный пул потоков будет планировать виртуальные потоки с завода точно так же, как это всегда делалось. Конечно, будут также потоки-носители уровня ОС для запуска этих виртуальных потоков, но это является внутренним для реализации виртуальных потоков.
Фиксированный пул потоков будет ограничивать общее количество одновременных виртуальных потоков. По умолчанию отображение из виртуальных потоков в потоки-носители выполняется с помощью пула соединений jdk.defaultScheduler.parallelism , который использует столько ядер, сколько задано системным свойством jdk.defaultScheduler.parallelism , либо по умолчанию Runtime.getRuntime().availableProcessors() . Вы можете предоставить свой собственный планировщик на фабрике потоков:
|
1
|
factory = Thread.builder().virtual().scheduler(myExecutor).factory(); |
Я не знаю, если это то, что кто-то хотел бы сделать. Почему носителей больше, чем ядер?
Вернуться к нашему исполнителю. Вы выполняете задачи в виртуальных потоках так же, как вы использовали для выполнения задач в потоках уровня ОС:
|
1
2
3
4
5
6
|
for (int i = 1; i <= NTASKS; i++) { String taskname = "task-" + i; exec.submit(() -> run(taskname));}exec.shutdown();exec.awaitTermination(delay, TimeUnit.MILLISECONDS); |
В качестве простого теста мы можем просто спать в каждой задаче.
|
01
02
03
04
05
06
07
08
09
10
|
public static int DELAY = 10_000; public static void run(Object obj) { try { Thread.sleep((int) (DELAY * Math.random())); } catch (InterruptedException ex) { ex.printStackTrace(); } System.out.println(obj); } |
Если вы теперь установите NTASKS на 1_000_000 и закомментируете .virtual() в программе-изготовителе, программа завершится с ошибкой .virtual() памяти. Миллионы потоков уровня ОС занимают много памяти. Но с виртуальными потоками это работает.
По крайней мере, он должен работать, и он работал для меня с предыдущими сборками Loom. К сожалению, после сборки, которую я скачал 5 декабря, я получил дамп ядра. Это происходило со мной время от времени, когда я экспериментировал с Loom. Надеюсь, это будет исправлено, когда вы попробуете это.
Теперь вы готовы попробовать что-то более сложное. Хайнц Кабуц недавно представил головоломку с программой, которая загружала тысячи мультяшных изображений Дилберта. Для каждого календарного дня есть страница, такая как https://dilbert.com/strip/2011-06-05 . Программа считывает эти страницы, размещает URL изображения мультфильма на каждой странице и загружает каждое изображение. Это был беспорядок завершаемых фьючерсов , что-то вроде:
|
1
2
3
4
5
6
|
CompletableFuture .completedFuture(getUrlForDate(date)) .thenComposeAsync(this::readPage, executor) .thenApply(this::getImageUrl) .thenComposeAsync(this::readPage) .thenAccept(this::process); |
С волокнами код гораздо понятнее:
|
1
2
3
4
5
|
exec.submit(() -> { String page = new String(readPage(getUrlForDate(date))); byte[] image = readPage(getImageUrl(page)); process(image);}); |
Конечно, каждый вызов readPage блокирует, но с волокнами нам все равно.
Попробуйте это с тем, что вам небезразлично. Читайте большое количество веб-страниц, обрабатывайте их, выполняйте больше операций чтения блокировок и наслаждайтесь тем, что блокирование обходится дешево с помощью волокон.
СТРУКТУРИРОВАННАЯ ВАЛЮТА
Первоначальной мотивацией для Project Loom было внедрение волокон, но в начале этого года проект приступил к экспериментальному API для структурированного параллелизма. В этой настоятельно рекомендуемой статье (из которой взяты изображения ниже) Натаниэль Смит предлагает структурированные формы параллелизма. Вот его центральный аргумент. Запуск задачи в новом потоке на самом деле не лучше, чем программирование с помощью GOTO, то есть вредно:
|
1
|
new Thread(runnable).start(); |
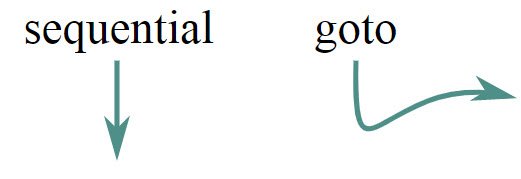
Когда несколько потоков работают без согласования, это снова спагетти-код. В 1960-х годах структурное программирование заменило goto ветвями, циклами и функциями:
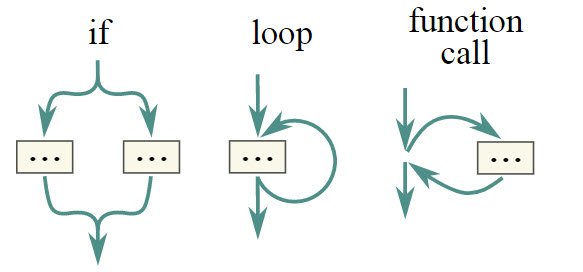
Теперь пришло время для структурированного параллелизма. При запуске параллельных задач мы должны знать по чтению текста программы, когда они все закончили.
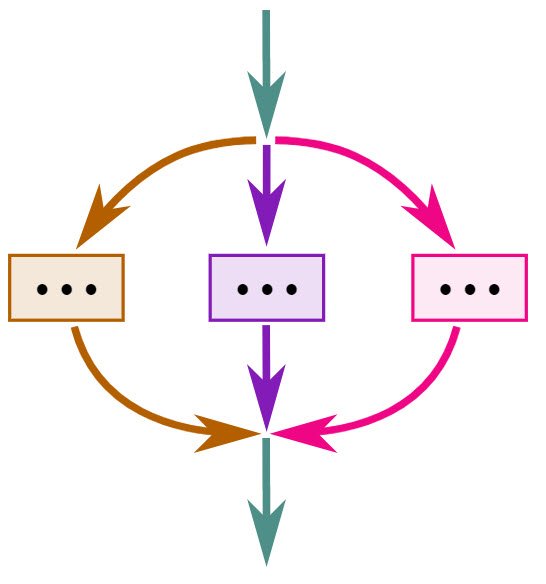
Таким образом, мы можем контролировать ресурсы, которые используют задачи.
К лету 2019 года Project Loom имел API для выражения структурированного параллелизма. К сожалению, этот API в настоящее время в клочья из-за более недавнего эксперимента по объединению API потоков и волокон, но вы можете попробовать его с прототипом на http://jdk.java.net/loom/ .
Здесь мы планируем ряд задач:
|
1
2
3
4
5
|
FiberScope scope = FiberScope.open();for (int i = 0; i < NTASKS; i++) { scope.schedule(() -> run(i));}scope.close(); |
Вызов scope.close() блокирует, пока не завершатся все волокна. Помните — блокировка не является проблемой с волокнами. Как только область действия закрыта, вы точно знаете, что волокна закончили.
FiberScope является автозаполняемым, поэтому вы можете использовать инструкцию try -with-resources:
|
1
2
3
|
try (var scope = FiberScope.open()) { ...} |
Но что, если одна из задач никогда не закончится?
Вы можете создать область с крайним сроком ( Instant ) или тайм-аутом ( Duration ):
|
1
2
3
4
|
try (var scope = FiberScope.open(Instant.now().plusSeconds(30))) { for (...) scope.schedule(...);} |
Все волокна, которые не были завершены в срок / тайм-аут, отменяются. Как? Читать дальше.
ОТМЕНА
Отмена всегда была боль в Java. По договоренности вы отменяете поток, прерывая его. Если поток блокирует, операция блокировки завершается с InterruptedException . В противном случае устанавливается статус прерванного флага. Получение правильных чеков утомительно. Бесполезно, что прерванный статус может быть сброшен или InterruptedException является проверенным исключением.
Обработка отмены в java.util.concurrent была непоследовательна. Рассмотрим ExecutorService.invokeAny . Если какая-либо задача дает результат, остальные отменяются. Но CompletableFuture.anyOf позволяет всем задачам выполняться до конца, даже если их результаты будут игнорироваться.
API Loom Project 2019 года решал проблему отмены. В этой версии волокна имеют операцию cancel , аналогичную interrupt , но отмена является безотзывной. Статический метод Fiber.cancelled возвращает true если текущее волокно было отменено.
Когда область действия истекает, ее волокна отменяются.
Отмена может контролироваться следующими параметрами в конструкторе FiberScope .
-
CANCEL_AT_CLOSE: закрытие области отменяет все запланированные волокна вместо блокировки -
PROPAGATE_CANCEL: в случае отмены владения волокном все новые запланированные волокна автоматически отменяются. -
IGNORE_CANCEL: запланированные волокна не могут быть отменены
Все эти параметры не установлены на верхнем уровне. Параметры IGNORE_CANCEL и IGNORE_CANCEL наследуются от родительской области.
Как вы можете видеть, было достаточно много настроек. Мы должны увидеть, что вернется, когда эта проблема будет вновь рассмотрена. Для структурированного параллелизма необходимо автоматически отменять все волокна в области действия, когда область действия заканчивается или принудительно закрывается.
РЕЗЬБОВЫЕ МЕСТА
Для меня стало неожиданностью, что одной из AccessControlContext для разработчиков Project Loom являются переменные ThreadLocal , а также более эзотерические вещи — загрузчики классов контекста, AccessControlContext . Я понятия не имел, так много катался на нитках.
Если у вас есть структура данных, которая не безопасна для одновременного доступа, вы можете иногда использовать экземпляр для каждого потока. Классический пример — SimpleDateFormat . Конечно, вы можете продолжать создавать новые объекты форматирования, но это неэффективно. Итак, вы хотите поделиться одним. Но глобальный
|
1
|
public static final SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd"); |
не сработает Если два потока обращаются к нему одновременно, форматирование может быть искажено.
Таким образом, имеет смысл иметь один из них на поток:
|
1
2
|
public static final ThreadLocal<SimpleDateFormat> dateFormat = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyy-MM-dd")); |
Чтобы получить доступ к фактическому форматеру, позвоните
|
1
|
String dateStamp = dateFormat.get().format(new Date()); |
При первом вызове get в данном потоке вызывается лямбда-выражение в конструкторе. С этого момента метод get возвращает экземпляр, принадлежащий текущему потоку.
Для темы это принятая практика. Но вы действительно хотите иметь миллион случаев, когда есть миллион волокон?
Это не проблема для меня, потому что кажется проще использовать что-то поточно-безопасное, например, форматер java.time . Но Project Loom размышлял над «локальными FiberScope » объектов — один из этих FiberScope повторно активирован.
Локали потоков также использовались в качестве приближения для локализации процессора в ситуациях, когда потоков примерно столько же, сколько процессоров. Это может быть поддержано API, который фактически моделирует намерение пользователя.
СОСТОЯНИЕ ПРОЕКТА
Разработчики, которые хотят использовать Project Loom, естественно, озабочены API, который, как вы видели, не исчерпан. Тем не менее, большая часть работы по реализации находится под капотом.
Важной частью является обеспечение возможности парковки волокон при блокировке работы. Это было сделано для работы в сети, поэтому вы можете подключаться к веб-сайтам, базам данных и т. Д. Внутри волокон. Парковка, когда локальный блок файловых операций в настоящее время не поддерживается.
Фактически, повторные реализации этих библиотек уже есть в JDK 11, 12 и 13 — дань полезности частых выпусков.
Блокировка на мониторах ( synchronized блоках и методах) пока не поддерживается, но это необходимо в конечном итоге. ReentrantLock теперь в порядке.
Если волокно блокируется в нативном методе, это «закрепит» нить, и ни одно из ее волокон не будет прогрессировать. Project Loom ничего не может с этим поделать.
Method.invoke требует больше работы для поддержки.
Работа по поддержке отладки и мониторинга продолжается.
Как уже упоминалось, стабильность по-прежнему является проблемой.
Самое главное, производительность имеет путь. Парковка и отмена парковки волокон — это не бесплатный обед. Раздел стека времени выполнения необходимо заменять каждый раз.
Во всех этих областях достигнут большой прогресс, поэтому давайте вернемся к тому, что заботит разработчиков — API. Это действительно хорошее время, чтобы взглянуть на Project Loom и подумать, как вы хотите его использовать.
Для вас имеет значение, что один и тот же класс представляет нити и волокна? Или вы бы предпочли, чтобы часть багажа Thread была выброшена? Вы покупаете обещание структурированного параллелизма?
Изучите Project Loom, посмотрите, как он работает с вашими приложениями и фреймворками, и предоставьте отзыв для команды разработчиков Intrepid!
|
Смотреть оригинальную статью здесь: Project Loom Мнения, высказанные участниками Java Code Geeks, являются их собственными. |