Давайте напишем пример Spark Streaming в Scala, который транслируется из Slack. Этот пост покажет, как сначала написать, настроить и выполнить код. Затем исходный код будет рассмотрен подробно. Если у вас нет команды Slack, вы можете создать ее бесплатно. Мы также рассмотрим это.
Давайте начнем с общего обзора шагов, которые мы предпримем.
Обзор Spark Streaming
- Настройка среды разработки для Scala и SBT
- Написать код
- Настроить Slack для доступа к потоку
- Запустите Apache Spark в автономном режиме
- Запустите приложение Spark Streaming
- Пересмотреть код для описания основных понятий.
Итак, наша начальная цель — запуск кода. Затем мы подробно рассмотрим исходный код.
1. Настройка среды разработки Spark Streaming для Scala и SBT
Давайте следовать правилам каталога SBT. Создайте новый каталог для начала. Я собираюсь назвать мой пример с искровым потоком. Ниже приведены команды для создания каталога, но вы также можете использовать менеджер окон, если хотите. Если эта структура каталогов не имеет смысла для вас, или вы не скомпилировали код Scala с SBT раньше, этот пост, вероятно, не самый лучший для вас. Извините, я должен был написать это. Я не имею в виду это как личный выстрел против вас. Я уверен, что вы замечательный и интересный человек. Этот пост не очень продвинутый, но я просто хочу быть честным с вами. Это лучше для нас обоих в долгосрочной перспективе.
Во всяком случае, где мы были? вы Scala-compiling-maestro … о да, структура каталогов.
Пример настройки среды Spark Streaming
|
1
2
3
4
5
6
7
|
mkdir spark-streaming-examplecd spark-streaming-examplemkdir srcmkdir src/mainmkdir src/main/scalamkdir src/main/scala/commkdir src/main/scala/com/supergloo |
Затем создайте файл build.sbt в корне вашего каталога dev. Готовы к сюрпризу? Сюрприз! Мой build.sbt будет в каталоге spark-streaming-example /.
Я использую build.sbt:
Пример Spark Streaming build.sbt
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
name := "spark-streaming-example" version := "1.0" scalaVersion := "2.11.8" libraryDependencies ++= Seq("org.apache.spark" % "spark-streaming_2.11" % "1.6.1", "org.scalaj" %% "scalaj-http" % "2.2.1", "org.jfarcand" % "wcs" % "1.5") |
Вы видите, что происходит, верно? Я сказал, правильно! Надеюсь, ты не вскочил со стула. Я не кричал, но просто хочу убедиться, что ты все еще со мной.
В двух словах: я собираюсь использовать Scala 2.11.8 и получить несколько зависимостей, таких как Spark Streaming 2.11, Scalaj-http и WCS. Ниже приведены ссылки на эти описания. Короче говоря, нам нужно wcs чтобы установить соединение через websocket с scalaj-http а scalaj-http — для http-клиента. Помните, наша первая цель — это рабочий код, а затем мы вернемся к более подробным описаниям. Останься со мной.
2. Напишите код Scala
Я назвал этот шаг «написать код Scala», но чем больше я об этом думаю, это не совсем точно. На самом деле, я собираюсь написать код, а вы можете копировать и вставлять. Повезло тебе. Видишь, как я забочусь о тебе.
Вам нужны два файла:
В каталоге src / main / scala / com / supergloo находится файл SlackReceiver.scala со следующим содержимым:
Пример Spark Streaming Slack Receiver
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
package com.supergloo import org.apache.spark.Loggingimport org.apache.spark.storage.StorageLevelimport org.apache.spark.streaming.receiver.Receiverimport org.jfarcand.wcs.{TextListener, WebSocket} import scala.util.parsing.json.JSONimport scalaj.http.Http /*** Spark Streaming Example Slack Receiver from Slack*/class SlackReceiver(token: String) extends Receiver[String](StorageLevel.MEMORY_ONLY) with Runnable with Logging { @transient private var thread: Thread = _ override def onStart(): Unit = { thread = new Thread(this) thread.start() } override def onStop(): Unit = { thread.interrupt() } override def run(): Unit = { receive() } private def receive(): Unit = { val webSocket = WebSocket().open(webSocketUrl()) webSocket.listener(new TextListener { override def onMessage(message: String) { store(message) } }) } private def webSocketUrl(): String = { val response = Http(slackUrl).param("token", token).asString.body JSON.parseFull(response).get.asInstanceOf[Map[String, Any]].get("url").get.toString } } |
И вам понадобится еще один файл в том же каталоге с именем SlackReceiver.scala со следующим содержимым:
Spark Streaming Пример приложения
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
package com.supergloo import org.apache.spark.SparkConfimport org.apache.spark.streaming.{Seconds, StreamingContext} /** * Spark Streaming Example App */object SlackStreamingApp { def main(args: Array[String]) { val conf = new SparkConf().setMaster(args(0)).setAppName("SlackStreaming") val ssc = new StreamingContext(conf, Seconds(5)) val stream = ssc.receiverStream(new SlackReceiver(args(1))) stream.print() if (args.length > 2) { stream.saveAsTextFiles(args(2)) } ssc.start() ssc.awaitTermination() } } |
Хорошо, на этом этапе «мы» закончили с кодом. И под «мы» я имею в виду вас.
Я думаю, что было бы неплохо убедиться, что SBT счастлив.
Итак, попробуйте sbt compile . Для моей среды я собираюсь запустить это из командной строки в папке spark-streaming-example. В разделе «Ресурсы» этого поста есть ссылка на скринкаст YouTube, на котором я запускаю это. Может быть, это может быть полезно для вас тоже. Я не знаю. Кому ты рассказываешь. На самом деле, не говорите мне, если это сработало. Дайте мне знать на странице комментариев, что не сработало. Это работает на моей машине. Ты когда-нибудь слышал это раньше?
3. Настройте Slack для доступа к API
Вам нужен токен OAuth для доступа API к Slack и для запуска этого примера Spark Streaming. К счастью для нас, Slack предоставляет тестовые токены, которые не требуют прохождения всех перенаправлений OAuth. Этот токен будет идеальным для этого примера.
Чтобы получить токен, перейдите по адресу https://api.slack.com/docs/oauth-test-tokens, чтобы увидеть список своих команд Slack, в которые вы вступили. Вот как выглядит мой (без синей стрелки):
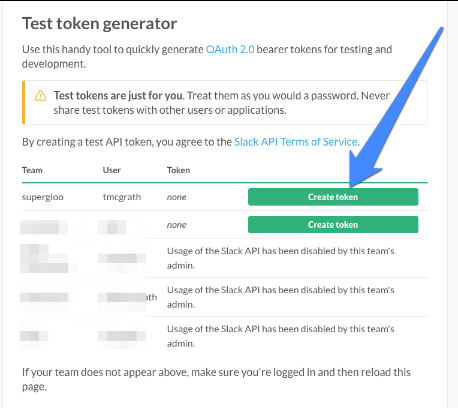
Я выделил немного, чтобы защитить невинных. Дело в том, что вы должны увидеть зеленое поле «Создать токен». Посмотрите еще раз на скриншот выше и там, где указывает синяя стрелка. У вас должна быть эта опция. И если вы этого не сделаете, есть другой вариант для вас.
Легко настроить собственный бесплатный сайт команды Slack. И когда вы это сделаете, по умолчанию в новой настройке команды будет включен доступ API. Итак, создайте новую команду, если у вас нет кнопки «Создать токен» ни у одной из ваших существующих команд. Начните здесь https://slack.com/create .
Если у вас настроена новая команда или когда у вас есть кнопка «Создать токен», доступная на ранее упомянутой странице тестового токена OAuth, щелкните ее, чтобы сгенерировать токен. Сохраните этот маркер, потому что мы, и под «мы», я имею в виду вас, это скоро понадобится. Но сначала «нам» нужно запустить Spark, чтобы мы могли запустить этот пример. Мы в этом вместе, ты и я. Вот так.
4. Запустите Apache Spark в автономном режиме.
Я предполагаю, что у вас есть среда Apache Spark для использования. Если вы этого не сделаете, вы можете быть немного впереди себя с учебником Spark Streaming, как этот. Если ты впереди себя, мне нравится твой стиль. Нет ничего лучше, чем прыгнуть в глубокий конец. Но этот бассейн может быть пустым, и вы можете получить травму. Я не имею в виду обидно буквально. Это скорее психическое, чем физическое.
На этом сайте есть множество ресурсов, которые помогут настроить автономный кластер Spark. Как я уже сказал, вам это нужно. Но давайте продолжим, если хотите.
Для этого урока Spark Streaming я собираюсь использовать самую простую из возможных настроек Spark. Это означает, что мы собираемся запустить Spark в автономном режиме. Видите ли, я могу принимать решения здесь. Я большой блоггер. Хорошо, хорошо, я знаю, на самом деле не большой выстрел. Но парень может мечтать. И я на самом деле не мечтаю стать популярным блоггером. Я мечтаю взять своих детей в приключения по всему миру. Я мечтаю посмотреть фильмы. Иногда я мечтаю посмотреть фильмы, пока мои дети где-то на другом конце света.
В любом случае, если вы играете важную роль с собственным Spark Cluster, вы можете запустить этот пример кода и для него. Ваш звонок. Очевидно, вы здесь хозяин.
Хорошо, босс, запустите Spark Standalone Master из командной строки:
Запустите Spark Master из командной строки
|
1
|
~/Development/spark-1.5.1-bin-hadoop2.4 $ sbin/start-master.sh |
Вам следует вызвать start-master.sh или ваш эквивалент Windows из того места, которое подходит для вашей среды. Для меня это каталог spark-1.5.1-bin-hadoop2.4. Вы знали это, глядя на пример, не так ли?
Следующий старт работника:
Начать Spark Worker
|
1
|
~/Development/spark-1.5.1-bin-hadoop2.4 $ sbin/start-slave.sh spark://todd-mcgraths-macbook-pro.local:7077 |
Вы не хотите добавлять spark://todd-mcgraths-macbook-pro.local:7077 при запуске вашего Spark. Это мое. Оставьте это поле пустым или установите что-то подходящее для вашей машины. todd-mcgraths-macbook-pro.local — мой ноутбук, а не твой.
Хорошо, вы сможете определить, все ли в порядке с запуском Spark. Если нет, то у вас определенно проблемы с этим учебником. Вам, вероятно, нужно немного замедлить скорость. Но ты босс.
Вам может понадобиться открыть другое командное окно для запуска следующего шага.
5. Запустите приложение Spark Streaming
Поклонник Скала и Спарк, здесь мы идем. Слушай, я знаю, что иногда sbt может быть медведем. Требуется некоторое время, чтобы он стал simple build tool . Но я не собираюсь обсуждать это здесь. ОК?
- Запустите SBT в каталоге, где находится build.sbt.
Запустите SBT для запуска Spark Streaming Example
1~/Development/spark-streaming-example$ sbt - В вашей консоли sbt:
Запуск примера Spark Streaming в SBT
1run local[5] <your-oauth-token> output
Что вы должны увидеть:
После запуска SlackStreamingApp вы увидите JSON, полученный из Slack. Боже мой, позвольте мне повторить: JSON из Slack. Мы сделали это! Дора может кричать Ло Hicimos! на этой точке. Или, может быть, Ботс сказал бы это. Я не могу вспомнить, и мне все равно. Вы тоже не
В зависимости от настроек вашего журнала, все может довольно быстро прокрутить вашу консоль.
Вы можете проверить это, добавив сообщения в команду Slack из доступа к токену OAuth. Вы также будете транслировать сообщения для событий Slack, таких как присоединение и выход из каналов, ботов и т. Д.
Вау, мы на самом деле сделали это. Ты и я, малыш. Я был уверен в тебе все время. Я верил в тебя, когда никто другой не верил. Ну, если честно, не совсем. Это Интернет в конце концов. Но время от времени я приятно удивлен. Я все еще думаю, что ты довольно опрятный.
6. Пересмотреть Spark Streaming Code — Опишите ключевые понятия
Хорошо, давайте вернемся к коду и начнем с внешних зависимостей. Как кратко отмечено в разделе build.sbt, мы подключились к Slack через WebSocket. Чтобы установить соединение WebSocket и проанализировать входящие данные JSON, мы использовали три вещи: внешнюю библиотеку WebSocket Scala (wcs), внешнюю библиотеку HttpClient (scalaj-http) и собственный анализатор JSON в Scala. Опять же, ссылки на используемые внешние библиотеки находятся в разделе Ресурсы ниже. Все три из них мы видим в действии в двух функциях SlackReceiver.
Пример Spark Streaming Receiver WebSocket, HttpClient, JSON
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
private def receive(): Unit = { val webSocket = WebSocket().open(webSocketUrl()) webSocket.listener(new TextListener { override def onMessage(message: String) { store(message) } })}private def webSocketUrl(): String = { val response = Http(slackUrl).param("token", token).asString.body JSON.parseFull(response).get.asInstanceOf[Map[String, Any]] .get("url").get.toString} |
Функция webSocketUrl использует токен OAuth, который мы отправили в первом аргументе для run . Подробнее об этом в ближайшее время. Обратите внимание, что данные входящего ответа обрабатываются как JSON в JSON.parseFull. Мы отправили токен OAuth из SlackStreamingApp, когда инициализировали SlackReceiver:
Отправка OAuth-токена нашему Spark Streaming Receiver
|
1
|
val stream = ssc.receiverStream(new SlackReceiver(args(1))) |
Кроме того, мы видим в функции webSocketUrl мы ожидаем, JSON и пары ключ / значение схемы Map [String, Any].
Хорошо, это касается внешних используемых библиотек. Давайте продолжим.
Вспомните из предыдущих руководств по Spark Streaming на этом сайте (ссылки в разделе Ресурсы ниже), Spark Streaming можно рассматривать как микропакетную систему. Вместо ожидания и обработки потоковых данных по одной записи за раз, Spark Streaming дискретизирует потоковые данные в микропакеты. Или, другими словами, приемники Spark Streaming принимают данные параллельно и буферизуют их в памяти рабочих узлов Spark.
Микропакеты опрашивают источники потока в указанные сроки. Какова частота опроса для этого примера приложения? Это каждые 5 секунд, как объявлено в коде приложения SlackStreaming:
Spark Streaming Context установлен на опрос каждые 5 секунд
|
1
|
val ssc = new StreamingContext(conf, Seconds(5)) |
А как насчет StreamingContext? StreamingContext — это тип контекста, который специфичен для Spark Streaming. Удивлены? Конечно, нет. Вы могли бы просто сказать по названию StreamingContext, верно? Я сказал правильно !? Ты вскочил со стула в это время? Я надеюсь, что это так. Вам необходим StreamingContext при создании потоковых приложений.
Вернемся к классу SlackReceiver. Расширение Receiver — это то, что мы делаем при создании настраиваемого приемника для Spark Streaming. И если вы еще не догадались, позвольте мне сказать вам, мы создали специальный приемник для Slack. Ну, ты бы посмотрел на нас. Мы создали специальный приемник. Кто-нибудь принесет нам трофей. Или лента. Или трофей с лентой.
Объявление класса:
Искровой потоковый приемник
|
1
|
class SlackReceiver(token: String) extends Receiver[String](StorageLevel.MEMORY_ONLY) with Runnable { |
Есть несколько вещей, чтобы отметить об этой декларации. Во-первых, для удобства запуска этого образца используется свойство Runnable . Я думал, что будет проще запустить это из SBT.
Мы устанавливаем StorageLevel только для памяти
Искровой потоковый приемник
|
1
|
StorageLevel.MEMORY_ONLY |
Это по умолчанию. Ничего особенного здесь. Это сохраняет RDD как десериализованные объекты в JVM. Если потребности хранилища превысят то, что доступно, они не попадут на диск и будут нуждаться в пересчете каждый раз, когда что-то нужно и не находится в памяти. Опять же, нам больше ничего не нужно в этом примере. Проверьте другие примеры, такие как MEMORY_AND_DISK, MEMORY_ONLY_SER, DISK_ONLY и другие, если вы хотите больше информации об уровнях хранения. Это сообщение Spark Streaming, черт возьми.
Наконец, при расширении Receiver мы переопределяем три функции. (Или, вы можете привести несколько примеров звонков изнутри onStart , но мы не собираемся делать это здесь. Почему? Потому что я большой босс и «провидец». Во-вторых, я большой стрелял в провидца или BSV, как говорят в бизнесе. <- Это бизнес пишется неправильно для моей международной аудитории. <- Это люди пишут неправильно для моей не говорящей на сленге говорящей аудитории…. черт возьми, теперь меня отследили.)
Где мы были?! Не дай мне сбиться с пути, партнер. Нам нужно переопределить две функции, потому что Receiver — это абстрактный класс:
Специальные функции Spark Streaming Receiver
|
01
02
03
04
05
06
07
08
09
10
|
... override def onStart(): Unit = { thread = new Thread(this) thread.start() } override def onStop(): Unit = { thread.interrupt() }... |
onStart создает и запускает новый поток для получения источника потока. Это инициирует вызов нашей переопределенной функции run потока, которая вызывает ранее описанную функцию receive .
onStop обеспечивает остановку всех порожденных потоков при остановке получателя.
.
Итак, это код. Но давайте также рассмотрим, как был вызван этот пример. Важной деталью является использование «5»:
Пример вызова Spark Streaming
|
1
|
run local[5] <your-oauth-token> output |
Почему 5? Если в качестве основного URL мы используем «local» или «local [1]», для выполнения задач будет использоваться только один поток. При использовании входного DStream на основе потокового приемника будет использоваться один поток для запуска приемника, который не оставляет потока для обработки полученных данных. Поэтому всегда используйте «local [ n ]» в качестве основного URL, где n > количество получателей для запуска.
При работе в Spark Cluster за пределами автономного режима количество ядер, выделенных приложению Spark Streaming, должно превышать количество получателей.
Наконец, мы закончим с довольно незначительной детализацией. Последний аргумент «output», который вы видите в SlackStreamingApp, используется здесь:
Необязательно: сохраните файлы Spark Stream в текст
|
1
2
3
|
if (args.length > 2) { stream.saveAsTextFiles(args(2))} |
Этот второй аргумент является необязательным и указывает, должны ли данные потока быть сохранены на диск и в какой каталог.
Вывод
Итак, все шутки в сторону, я надеюсь, что этот пример Spark Streaming поможет вам. Мне нравится помогать хорошим людям, которые пытаются. Я надеюсь, что вы один из тех людей.
Вы можете подписаться на рассылку, подписаться на Twitter и подписаться на YouTube. У вас есть варианты. Я думаю, что ссылки на эти сайты находятся внизу каждой страницы. Если честно, я не совсем уверен, что хочу, чтобы вы подписались или подписались, но я не думаю, что смогу помешать вам сделать это. Итак, ты главный босс. Увидеть? Я сделал это снова. Просто получаю удовольствие.
Позаботьтесь и дайте мне знать, если у вас есть какие-либо вопросы или предложения для этого поста в комментариях ниже.
Вот скринкаст о том, как я проходил через большинство из этих шагов выше.
Смотри, мама, я на YouTube! Вы можете подписаться на канал Supergloo YouTube, если хотите. Моя мама сделала. Думаю. По крайней мере, она сказала мне, что она сделала. (Я называю ее мамой, а не мамой, смирись с этим. Я из Миннесоты.)
Ресурсы для этого учебного примера Spark Streaming
- WSC — асинхронный соединитель WebSocket — https://github.com/jfarcand/WCS
- HttpClient — https://github.com/scalaj/scalaj-http
- Проверьте этот сайт на предмет «Spark Streaming Example Part 1». Этот пост был слабо связан Часть 2.
| Ссылка: | Пример Spark Streaming — Как транслировать из Slack от нашего партнера по JCG Тодда МакГрата в блоге Supergloo . |