Последовательность событий между потоками является обычной операцией для многих многопоточных алгоритмов. Эти последовательности могут быть использованы для назначения идентификаторов ордерам, сделкам, транзакциям, сообщениям, событиям и т. Д. В Disruptor мы используем монотонную последовательность для всех событий, которая реализована как AtomicLong incrementAndGet для сценария многопоточной публикации .
Работая над последней версией Disruptor, я внес некоторые изменения, которые, как я убежден, повысят производительность, однако результаты меня удивили. Я удалил некоторые потенциально мегаморфные вызовы методов, и производительность стала скорее хуже, чем лучше. После долгих исследований я обнаружил, что вызовы мегаморфных методов скрывали проблему производительности с последними процессорами Intel Sandybridge . После того, как мегаморфные вызовы исчезли, разногласия по поводу генерации атомных последовательностей возросли, обнажив проблему. Я также наблюдал эту проблему с производительностью других параллельных структур Java, таких как ArrayBlockingQueue .
Я проводил различные тесты на Sandybridge и до сих пор был впечатлен улучшением производительности по сравнению сNehalem , особенно для приложений, интенсивно использующих память, из-за изменений в его интерфейсе. Однако с этим тестом последовательности я обнаружил, что Sandybridge сделал большой шаг назад по производительности в отношении атомарных инструкций.
Атомные инструкцииразрешить объединение действий чтения-изменения-записи в элементарную операцию. Хорошим примером является увеличение счетчика. Для завершения операции увеличения поток должен прочитать текущее значение, увеличить его, а затем записать результаты. В многопоточной среде эти отдельные операции могут чередоваться с другими потоками, делающими то же самое с искаженными результатами. Обычный способ избежать этого чередования — снять блокировку для взаимного исключения при выполнении шагов. Блокировки очень дороги и часто требуют арбитража ядра между потоками. Современные процессоры предоставляют ряд атомарных инструкций, которые позволяют выполнять такие операции, как атомарное увеличение счетчика или возможность условно устанавливать ссылку на указатель, если значение все еще такое, как ожидалось. Эти операции обычно называютCAS (Сравнить и поменять) инструкции. Хороший способ думать об этих инструкциях CAS подобен оптимистичным блокировкам, подобным тому, что вы испытываете при использовании системы контроля версий, такой как Subversion или CVS. Вы пытаетесь внести изменение, и если версия соответствует ожидаемой, то у вас все получится, в противном случае действие отменяется.
На x86 / x64 эти инструкции известны как инструкции «блокировки». Название «lock» происходит от того, как процессор, после установки своего сигнала блокировки, заблокирует лицевую сторону / шину памяти ( FSB ) для сериализации доступа к памяти, в то время как три шага операции выполнялись атомарно. На более поздних процессорах инструкция блокировки просто реализуется путем получения монопольной блокировки на строке кэша для модификации.
Эти инструкции являются основными строительными блоками, используемыми для реализации высокоуровневых блокировок и семафоров. Это, как будет объяснено ниже, почему я видел проблемы с выполнением Sandybridge для ArrayBlockingQueue в некоторых сравнительных тестах производительности Disruptor .
Вернуться к моей отметке. Тест проводил в AtomicLong.incrementAndGet () значительно больше времени, чем я наблюдал ранее. Сначала я подозревал проблему с JDK 1.6.0_27, которую я только что установил. Я запустил следующий тест с различными JVM, включая 1.7.0, и продолжал получать одинаковые результаты. Затем я загрузил разные операционные системы (Ubuntu, Fedora, Windows 7 — все 64-битные), опять те же результаты. Это привело меня к написанию изолированного теста, который я проводил на Nehalem (2,8 ГГц Core i7 860) и Sandybridge (2,2 ГГц Core i7-2720QM).
import java.util.concurrent.atomic.AtomicLong;
public final class TestAtomicIncrement
implements Runnable
{
public static final long COUNT = 500L * 1000L * 1000L;
public static final AtomicLong counter = new AtomicLong(0L);
public static void main(final String[] args) throws Exception
{
final int numThreads = Integer.parseInt(args[0]);
final long start = System.nanoTime();
runTest(numThreads);
System.out.println("duration = " + (System.nanoTime() - start));
System.out.println("counter = " + counter);
}
private static void runTest(final int numThreads)
throws InterruptedException
{
Thread[] threads = new Thread[numThreads];
for (int i = 0; i < threads.length; i++)
{
threads[i] = new Thread(new TestAtomicIncrement());
}
for (Thread t : threads)
{
t.start();
}
for (Thread t : threads)
{
t.join();
}
}
public void run()
{
long i = 0L;
while (i < COUNT)
{
i = counter.incrementAndGet();
}
}
}
 |
| Figure 1. |
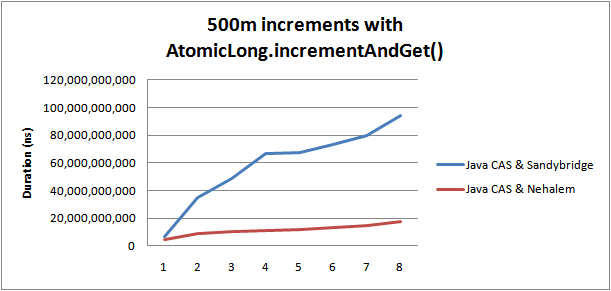
Проведя этот тест на 4 разных процессорах Sandybridge с диапазоном тактовых частот, я пришел к выводу, что использование LOCK CMPXCHG из-за растущего числа потоков гораздо менее масштабируемо, чем предыдущее поколение процессоров Nehalem. На рис. 1 выше показаны результаты в течение наносекунд, чтобы завершить счетчик на 500 миллионов с увеличением числа потоков. Чем меньше тем лучше.
Я подтвердил, что JVM генерирует правильные инструкции для цикла CAS, заставив Hotspot напечатать сгенерированный им ассемблер. Я также подтвердил, что Hotspot генерирует идентичные инструкции ассемблера для Nehalem и Sandybridge.
Затем я решил продолжить исследование и написать следующую программу на C ++, чтобы протестировать соответствующие инструкции по блокировке для сравнения Nehalem и Sandybridge. Из использования « objdump -d » в двоичном файле я знаю,
что
GNU Atomic Builtins генерирует инструкции по блокировке для ADD, XADD и CMPXCHG для соответственно названных функций ниже.
#include <time.h>
#include <pthread.h>
#include <stdlib.h>
#include <iostream>
typedef unsigned long long uint64;
const uint64 COUNT = 500LL * 1000LL * 1000LL;
volatile uint64 counter = 0;
void* run_add(void* numThreads)
{
register uint64 value = (COUNT / *((int*)numThreads)) + 1;
while (--value != 0)
{
__sync_add_and_fetch(&counter, 1);
}
}
void* run_xadd(void*)
{
register uint64 value = counter;
while (value < COUNT)
{
value = __sync_add_and_fetch(&counter, 1);
}
}
void* run_cas(void*)
{
register uint64 value = 0;
while (value < COUNT)
{
do
{
value = counter;
}
while (!__sync_bool_compare_and_swap(&counter, value, value + 1));
}
}
int main (int argc, char* argv[])
{
const int NUM_THREADS = atoi(argv[1]);
pthread_t threads[NUM_THREADS];
void* status;
timespec ts_start;
timespec ts_finish;
clock_gettime(CLOCK_MONOTONIC, &ts_start);
for (int i = 0; i < NUM_THREADS; i++)
{
pthread_create(&threads[i], NULL, run_add, (void*)&NUM_THREADS);
}
for (int i = 0; i < NUM_THREADS; i++)
{
pthread_join(threads[i], &status);
}
clock_gettime(CLOCK_MONOTONIC, &ts_finish);
uint64 start = (ts_start.tv_sec * 1000000000LL) + ts_start.tv_nsec;
uint64 finish = (ts_finish.tv_sec * 1000000000LL) + ts_finish.tv_nsec;
uint64 duration = finish - start;
std::cout << "threads = " << NUM_THREADS << std::endl;
std::cout << "duration = " << duration << std::endl;
std::cout << "counter = " << counter << std::endl;
return 0;
}
 |
| Figure 2. |
Из рисунка 2 видно, что Nehalem работает почти на порядок лучше для атомарных операций, так как конкуренция увеличивается с потоками. Я обнаружил, что LOCK ADD и LOCK XADD похожи друг на друга, поэтому для ясности я только составил график XADD. Операции CAS для C ++ и Java сопоставимы.
Также очень интересно, как XADD значительно превосходит CAS и дает хороший масштабируемый профиль. Для 3 потоков и выше XADD не ухудшается дальше и просто работает со скоростью, с которой процессор может поддерживать связность кэшей. Nehalem и Sandybridge выравниваются соответственно на ~ 100 м и ~ 20 м операций XADD в секунду для 3+ одновременных потоков, тогда как CAS продолжает ухудшаться с увеличением числа потоков из-за конфликта. Естественно, производительность ухудшается, когда
QPIссылки участвуют в сценарии с несколькими сокетами. Oracle признала, что не поддержка XADD является
ошибкой, и, надеюсь, скоро исправит ее для JVM.
Что касается производительности, которую я наблюдал с Sandybridge, было бы здорово, если бы другие могли подтвердить мои выводы, чтобы мы могли получить обратную связь с Intel и решить эту проблему. Я не смог заполучить систему серверного класса с Sandybridge.
От http://mechanical-sympathy.blogspot.com/2011/09/adventures-with-atomiclong.html