Поисковые системы все о поиске строк. Пользователь вводит термин запроса, который затем извлекается из инвертированного индекса. Иногда пользователь ищет значение, которое является только подстрокой значений в индексе, и пользователь также может быть заинтересован в этих совпадениях. Это особенно важно для таких языков, как немецкий, которые содержат составные слова, такие как Semmelknödel, где Knödel означает клецки, а Semmel специализирует их.
Wildcards
Для демонстрации подходов я использую очень простую схему. Документы состоят из текстового поля и идентификатора. Конфигурация, а также модульное тестирование также доступны на Github .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
<fields> <field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="text" type="text_general" indexed="true" stored="false"/></fields><uniqueKey>id</uniqueKey><types> <fieldType name="string" class="solr.StrField" sortMissingLast="true" /> <fieldType name="text_general" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType></types> |
Один из подходов, который довольно популярен при выполнении совпадений префиксов или суффиксов, — это использование групповых символов при запросах. Это может быть сделано программно, но вам нужно позаботиться о том, чтобы любой пользовательский ввод был правильно экранирован. Предположим, у вас есть термин dumpling в индексе, и пользователь вводит термин dump . Если вы хотите убедиться, что термин запроса совпадает с документом в индексе, вы можете просто добавить подстановочный знак к пользовательскому запросу в коде вашего приложения, чтобы результирующий запрос был дампом * .
Как правило, вы должны быть осторожны, когда делаете слишком много магии, как это: если пользователь на самом деле ищет документы, содержащие слово dump, он может быть не заинтересован в документах, содержащих клецки. Вы должны решить для себя, хотите ли вы, чтобы результаты соответствовали только интересам пользователя (точность) или показывали пользователю как можно больше возможных совпадений (напомним). Это сильно зависит от вариантов использования вашего приложения.
Вы можете немного улучшить пользовательский опыт, увеличив точные соответствия для вашего срока. Вам нужно создать более сложный запрос, но в этом случае документы, содержащие точное совпадение, получат более высокую оценку:
|
1
|
dump^2 OR dump* |
При создании такого запроса вы также должны позаботиться о том, чтобы пользователь не мог добавить термины, которые сделают запрос недействительным. Метод escapeQueryChars escapeQueryChars класса ClientUtils может использоваться для экранирования пользовательского ввода.
Если вы сейчас принимаете во внимание совпадения суффиксов, запрос может быть довольно сложным, и создание такого запроса на стороне клиента не для всех. В зависимости от вашего приложения лучшим подходом может быть другой подход: вы можете создать другое поле, содержащее NGrams во время индексации.
Префикс соответствует с NGrams
NGrams — это подстроки ваших проиндексированных терминов, которые вы можете поместить в дополнительное поле. Эти подстроки могут затем использоваться для поиска, поэтому нет необходимости в подстановочных знаках. Используя обработчик (e) dismax, вы можете автоматически установить усиление для вашего поля, которое используется для точных совпадений, чтобы вы получили то же поведение, которое мы видели выше.
Для совпадения префиксов мы можем использовать EdgeNGramFilter , настроенный для дополнительного поля:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
... <field name="text_prefix" type="text_prefix" indexed="true" stored="false"/>... <copyField source="text" dest="text_prefix"/>... <fieldType name="text_prefix" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.LowerCaseTokenizerFactory"/> <filter class="solr.EdgeNGramFilterFactory" minGramSize="3" maxGramSize="15" side="front"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.LowerCaseTokenizerFactory"/> </analyzer> </fieldType> |
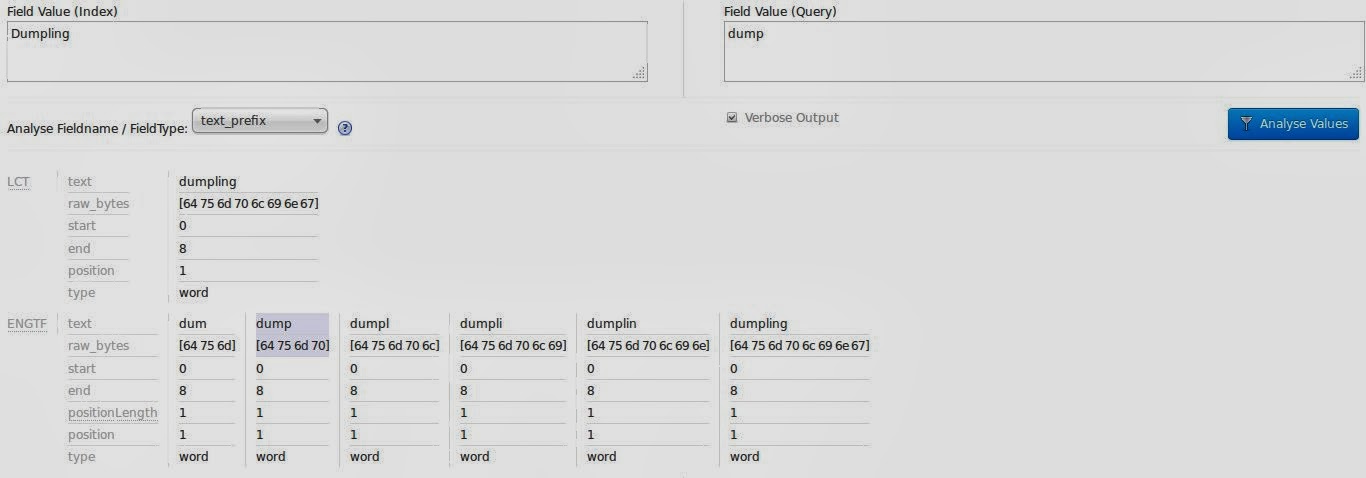
Во время индексации значение текстового поля копируется в поле text_prefix и анализируется с помощью EdgeNGramFilter. Граммы создаются для любой длины от 3 до 15, начиная с начала строки. При индексации термина клецки это будет:
- дум
- свалка
- dumpl
- dumpli
- Dumplin
- клецка
Во время запроса термин снова не разделяется, поэтому можно использовать точное совпадение для подстроки. Как обычно, представление анализа административной части Solr может помочь увидеть процесс анализа в действии.
Используя обработчик dismax, вы теперь можете передать запрос пользователя как есть и просто посоветовать ему выполнить поиск по вашим полям, добавив параметр qf=text^2,text_prefix .
Суффикс Матчи
Для языков, которые содержат составные слова, распространенным требованием также является сопоставление суффиксов. Если пользователь запрашивает термин Knödel (пельмени), ожидается, что документы, содержащие термин Semmelknödel, также совпадают.
При использовании версий Solr до 4.3 это не проблема. Вы можете использовать EdgeNGramFilterFactory для создания граммов, начиная с конца строки.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
... <field name="text_suffix" type="text_suffix" indexed="true" stored="false"/>... <copyField source="text" dest="text_suffix"/>... <fieldType name="text_suffix" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.EdgeNGramFilterFactory" minGramSize="3" maxGramSize="15" side="back"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.KeywordTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>... |
Это создает суффиксы индексированного термина, который также содержит термин knödel, поэтому наш запрос работает.
Но, используя более свежие версии Solr, вы столкнетесь с проблемой во время индексации:
|
1
2
3
4
5
|
java.lang.IllegalArgumentException: Side.BACK is not supported anymore as of Lucene 4.4, use ReverseStringFilter up-front and afterward at org.apache.lucene.analysis.ngram.EdgeNGramTokenFilter.(EdgeNGramTokenFilter.java:114) at org.apache.lucene.analysis.ngram.EdgeNGramTokenFilter.(EdgeNGramTokenFilter.java:149) at org.apache.lucene.analysis.ngram.EdgeNGramFilterFactory.create(EdgeNGramFilterFactory.java:52) at org.apache.lucene.analysis.ngram.EdgeNGramFilterFactory.create(EdgeNGramFilterFactory.java:34) |
Вы больше не можете использовать EdgeNGramFilterFactory для суффиксов ngram. Но, к счастью, трассировка стека также помогает нам решить проблему. Мы должны объединить это с ReverseStringFilter:
|
01
02
03
04
05
06
07
08
09
10
11
|
<fieldType name="text_suffix" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.LowerCaseTokenizerFactory"/> <filter class="solr.ReverseStringFilterFactory"/> <filter class="solr.EdgeNGramFilterFactory" minGramSize="3" maxGramSize="15" side="front"/> <filter class="solr.ReverseStringFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.LowerCaseTokenizerFactory"/> </analyzer></fieldType> |
Теперь это даст те же результаты, что и раньше.
Вывод
Собираетесь ли вы манипулировать запросом, добавляя подстановочные знаки, или следует использовать подход NGram, в значительной степени зависит от вашего варианта использования, а также от вкуса. Лично я использую NGrams большую часть времени, поскольку дисковое пространство обычно не имеет значения для проектов, над которыми я работаю. Поиск по шаблону стал намного быстрее в Lucene 4, поэтому я сомневаюсь, что в этом есть реальная выгода Тем не менее, я склонен делать как можно больше обработки во время индексации.
| Ссылка: | Префиксы и суффиксы в Solr от нашего партнера JCG Флориана Хопфа в блоге Dev Time . |