1. Введение
Представьте, что у нас есть приложение, которому необходим доступ к внешнему веб-сервису, чтобы собирать информацию о клиентах и затем обрабатывать ее. Более конкретно, мы не можем получить всю эту информацию за один вызов. Если мы хотим искать разных клиентов, нам потребуется несколько вызовов.
Как показано на рисунке ниже, пример приложения извлекает информацию о нескольких клиентах, группирует их в списке и затем обрабатывает для расчета общей суммы своих покупок:
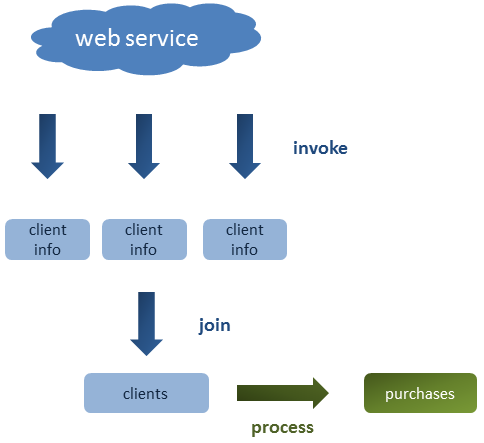
В этом посте мы увидим различные способы сбора информации, и какой из них является лучшим с точки зрения производительности.
Это пост, связанный с Java. Однако мы будем использовать среду Spring для вызова веб-службы RESTful .
Разделы:
- Вступление
- Объясняя пример
- Первая попытка: последовательный поток
- Улучшение производительности: параллельный поток
- Неблокирующая обработка с CompletableFuture
- Вывод
Исходный код можно найти в репозитории Java 8 GitHub .
Кроме того, вы можете получить доступ к исходному коду веб-приложения, предоставляющего веб-службу RESTful, в этом хранилище.
2. Объясняя пример
В нашем приложении у нас есть список из 20 идентификаторов, представляющих клиентов, которых мы хотим получить из веб-службы. После извлечения всех клиентов мы рассмотрим, что покупал каждый клиент, и подведем их итоги, чтобы вычислить общую сумму денег, потраченную всеми клиентами.
Однако существует одна проблема: этот веб-сервис позволяет извлекать только одного клиента при каждом вызове, поэтому нам потребуется вызывать сервис двадцать раз. Кроме того, веб-служба работает немного медленнее, и для ответа на запрос требуется не менее двух секунд.
Если мы посмотрим на приложение, реализующее веб-сервис, то увидим, что вызовы обрабатываются классом ClientController:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
@RestController@RequestMapping(value="/clients")public class ClientController { @Autowired private ClientService service; @RequestMapping(value="/{clientId}", method = RequestMethod.GET) public @ResponseBody Client getClientWithDelay(@PathVariable String clientId) throws InterruptedException { Thread.sleep(2000); Client client = service.getClient(clientId); System.out.println("Returning client " + client.getId()); return client; }} |
Thread.sleep используется для имитации медлительности ответа.
Класс домена (Клиент) содержит необходимую нам информацию; сколько денег потратил клиент:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
public class Client implements Serializable { private static final long serialVersionUID = -6358742378177948329L; private String id; private double purchases; public Client() {} public Client(String id, double purchases) { this.id = id; this.purchases = purchases; } //Getters and setters} |
3. Первая попытка: последовательный поток
В этом первом примере мы будем последовательно вызывать сервис для получения информации обо всех двадцати клиентах:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public class SequentialStreamProcessing { private final ServiceInvoker serviceInvoker; public SequentialStreamProcessing() { this.serviceInvoker = new ServiceInvoker(); } public static void main(String[] args) { new SequentialStreamProcessing().start(); } private void start() { List<String> ids = Arrays.asList( "C01", "C02", "C03", "C04", "C05", "C06", "C07", "C08", "C09", "C10", "C11", "C12", "C13", "C14", "C15", "C16", "C17", "C18", "C19", "C20"); long startTime = System.nanoTime(); double totalPurchases = ids.stream() .map(id -> serviceInvoker.invoke(id)) .collect(summingDouble(Client::getPurchases)); long endTime = (System.nanoTime() - startTime) / 1_000_000; System.out.println("Sequential | Total time: " + endTime + " ms"); System.out.println("Total purchases: " + totalPurchases); }} |
Выход:
|
1
2
|
Sequential | Total time: 42284 msTotal purchases: 20.0 |
Выполнение этой программы занимает примерно 42 секунды. Это слишком много времени. Посмотрим, сможем ли мы улучшить его производительность.
4. Повышение производительности: параллельный поток
Java 8 позволяет нам разбивать поток на куски и обрабатывать каждый в отдельном потоке. Нам нужно просто создать поток в предыдущем примере как параллельный поток.
Следует учитывать, что каждый чанк будет выполняться в своем потоке асинхронно, поэтому порядок обработки чанков не должен иметь значения. В нашем случае мы суммируем покупки, чтобы мы могли это сделать.
Давайте попробуем это:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
private void start() { List<String> ids = Arrays.asList( "C01", "C02", "C03", "C04", "C05", "C06", "C07", "C08", "C09", "C10", "C11", "C12", "C13", "C14", "C15", "C16", "C17", "C18", "C19", "C20"); long startTime = System.nanoTime(); double totalPurchases = ids.parallelStream() .map(id -> serviceInvoker.invoke(id)) .collect(summingDouble(Client::getPurchases)); long endTime = (System.nanoTime() - startTime) / 1_000_000; System.out.println("Parallel | Total time: " + endTime + " ms"); System.out.println("Total purchases: " + totalPurchases);} |
Выход:
|
1
2
|
Parallel | Total time: 6336 msTotal purchases: 20.0 |
Вау, это большое улучшение! Но откуда этот номер?
Параллельные потоки внутренне используют ForkJoinPool, который является пулом, используемым средой ForkJoin, представленной в Java 7. По умолчанию пул использует столько потоков, сколько могут обработать процессоры вашей машины. Мой ноутбук является четырехъядерным процессором, который может обрабатывать 8 потоков (вы можете проверить это, вызвав Runtime.getRuntime.availableProcessors), поэтому он может выполнять 8 обращений к веб-службе параллельно. Поскольку нам нужно 20 вызовов, потребуется как минимум 3 «раунда»:
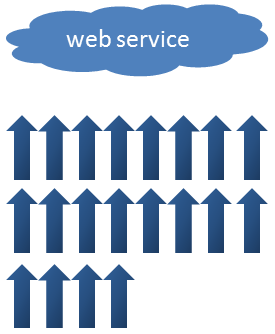
Итак, с 40 секунд до 6 это довольно хорошее улучшение, но можем ли мы его еще улучшить? Ответ — да.
5. Неблокирующая обработка с CompletableFuture
Давайте проанализируем предыдущее решение.
Мы отправляем 8 потоков, каждый из которых вызывает веб-службу, но пока служба обрабатывает запрос (две целых секунды), наши процессоры не делают ничего, кроме ожидания (это операция ввода-вывода). Пока эти запросы не вернутся, мы не сможем отправлять больше запросов.
Вопрос в том, что если бы мы могли отправлять все 20 запросов асинхронно, освобождая наши процессоры и обрабатывая каждый ответ, когда он доступен? Вот где CompletableFuture приходит на помощь:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
public class AsyncStreamExecutorProcessing { private final ServiceInvoker serviceInvoker; private final ExecutorService executorService = Executors.newFixedThreadPool(100); public AsyncStreamExecutorProcessing() { this.serviceInvoker = new ServiceInvoker(); } public static void main(String[] args) { new AsyncStreamExecutorProcessing().start(); } private void start() { List<String> ids = Arrays.asList( "C01", "C02", "C03", "C04", "C05", "C06", "C07", "C08", "C09", "C10", "C11", "C12", "C13", "C14", "C15", "C16", "C17", "C18", "C19", "C20"); long startTime = System.nanoTime(); List<CompletableFuture<Client>> futureRequests = ids.stream() .map(id -> CompletableFuture.supplyAsync(() -> serviceInvoker.invoke(id), executorService)) .collect(toList()); double totalPurchases = futureRequests.stream() .map(CompletableFuture::join) .collect(summingDouble(Client::getPurchases)); long endTime = (System.nanoTime() - startTime) / 1_000_000; System.out.println("Async with executor | Total time: " + endTime + " ms"); System.out.println("Total purchases: " + totalPurchases); executorService.shutdown(); }} |
Выход:
|
1
2
|
Async with executor | Total time: 2192 msTotal purchases: 20.0 |
Это заняло треть времени, проведенного в предыдущем примере.
Мы отправили все 20 запросов одновременно, поэтому время, затрачиваемое на операции ввода-вывода, расходуется только один раз. Как только приходят ответы, мы быстро их обрабатываем.
Важно использовать службу executor, установленную в качестве необязательного второго параметра метода supplyAsync. Мы указали пул из ста потоков, чтобы мы могли отправлять 100 запросов одновременно. Если мы не указываем исполнителя, пул ForkJoin будет использоваться по умолчанию.
Вы можете попытаться удалить исполнителя, и вы увидите ту же производительность, что и в параллельном примере.
6. Заключение
Мы видели, что при выполнении операций, не связанных с вычислениями (например, операций ввода-вывода), мы можем использовать класс CompletableFuture, чтобы использовать преимущества наших процессоров и повысить производительность наших приложений.
| Ссылка: | Повышение производительности: неблокирующая обработка потоков от нашего партнера по |