Apache ActiveMQ, JBoss A-MQ и Red Hat
Apache ActiveMQ — это очень популярный брокер обмена сообщениями с открытым исходным кодом, созданный теми же людьми, которые создали (и работают) Apache Karaf , Apache Camel , Apache ServiceMix и многие другие. Он имеет активное сообщество, очень гибок и может быть развернут в высокопроизводительных и высокодоступных сценариях.
В Red Hat (там, где я работаю) мы поддерживаем продукт под названием JBoss A-MQ , который представляет собой усиленную, полностью поддерживаемую предприятием версию открытого проекта ActiveMQ, поддерживаемую предприятием. Red Hat полностью привержена открытому исходному коду, и все наши продукты являются открытым исходным кодом (за исключением этого открытого булл-хауса). Наши клиенты, и в особенности те, кто использует JBoss A-MQ, являются лидерами в своих областях (розничная торговля / электронная торговля). розничная торговля, правительство, судоходство, поставщики медицинских услуг, финансы, телекоммуникационные компании и т. д.) и развертывание JBoss A-MQ в крайне критических ситуациях.
Поскольку кодовая база JBoss A-MQ исходит от вышестоящего сообщества ActiveMQ, и все исправления ошибок и улучшения, которые мы делаем на стороне Red Hat, возвращаются в сообщество, я хотел бы поделиться с вами улучшением, которое мы недавно внесли, ускорили наш вариант использования у известного клиента в 25 раз и потенциально могли бы также помочь вашему варианту использования. Принятые исправления находятся в основной ветке и не будут доступны до выпуска сообщества 5.12 (хотя будут доступны в патче для JBoss A-MQ 6.1 раньше, возможно, в конце этой недели или в начале следующей недели) , хотя я призываю вас проверить ночной SNAPSHOT 5.12, чтобы попробовать его раньше ( ночные снимки можно найти здесь ).
Наша проблема …
Чтобы установить контекст, мы говорим о постоянном обмене сообщениями через брокера. Это означает, что брокер не примет на себя ответственность за сообщение, пока оно не будет безопасно сохранено в постоянном хранилище. На этом этапе брокер должен доставить сообщение потребителю и не должен терять его, пока потребитель не признает ответственность за сообщение.
Документация ActiveMQ описывает этот поток следующим образом:
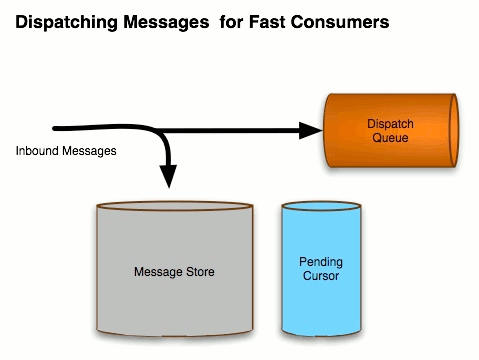
Однако, чтобы сообщение не потерялось, мы должны предположить, что хранилище сообщений доступно. В случае, описанном в оставшейся части этой статьи, мы используем адаптер постоянства KahaDB , который является стандартным адаптером постоянства, предоставляемым из коробки. Нам нужно иметь файлы базы данных kahadb в высокодоступном хранилище (NAS, SAN и т. Д.). Второе требование заключается в том, что когда мы записываем сообщение в файловую систему, мы должны синхронизировать данные на диск (иначе говоря, очистить все буферы между приложением, ОС, сетью и оборудованием), чтобы мы могли быть уверены, что диск не будет потерять данные. Вы можете получить компромиссы с очень быстрым «постоянством», не синхронизируясь с диском и позволяя ОС буферизовать записи, но это создает вероятность потери сообщений при сбое.
Вернемся к нашей истории: в нашем случае мы использовали файловую систему GFS2 поверх блочного устройства хранения данных с RHEL 6.5. Когда ActiveMQ записывает сообщение в базу данных, он попросит дескриптор файла ОС «синхронизировать», чтобы все содержимое было безопасно на диске, и заблокирует записывающий поток до тех пор, пока это не будет завершено (происходит немного больше, но упростит это на секунду). Эта синхронизация очень дорогая, и мы заметили, что она была еще медленнее, потому что данные синхронизировались и метаданные синхронизировались при КАЖДОМ вызове. (все это в некоторой степени зависит от ОС, файловой системы и т. д.… для этого конкретного сценария мы говорим о RHEL 6.5 и GFS2).
В нашем случае использования мы решили, что нам не нужно синхронизировать метаданные во всех вызовах для синхронизации, а только те, которые операционная система считает необходимыми для поддержания согласованности. Так что в ActiveMQ есть недокументированная (напоминающая мне об этом документирование) функция, которую вы можете настроить так, чтобы НЕ принудительно синхронизировать метаданные при каждом вызове синхронизации и делегировать ОС. Для этого передайте этот флаг в JVM во время запуска:
|
1
|
-Dorg.apache.activemq.kahaDB.files.skipMetadataUpdate=true |
Это позволит ОС принять решение, синхронизировать ли метаданные или нет. А в некоторых случаях это ускоряет запись на диск с последующей синхронизацией данных.
Однако в нашем случае это было не так. Мы получали около 76 сообщений в секунду, что не проходит тест на запах для меня.
DiskBenchmark с ActiveMQ
Таким образом, мы вытащили малоизвестный инструмент для тестирования производительности дисков, который поставляется с ActiveMQ из коробки (обратите внимание … этот документ тоже :)). Он проверяет, насколько быстро он может писать / читать из базовой файловой системы. В этом случае это полезно, поскольку ActiveMQ также написан на Java, для этого DiskBenchmark будет использовать API-интерфейсы Java. Таким образом, вы можете использовать его как одну точку данных для определения скорости записи. Существуют и другие тесты системного уровня, которые вы можете выполнить для проверки отдельных частей вашей системы хранения / файловой системы, но я отступаю — этот пост уже слишком длинный.
Чтобы запустить тест производительности диска, перейдите в каталог установки ActiveMQ и выполните следующее:
|
1
2
|
java -classpath "lib/*" \org.apache.activemq.store.kahadb.disk.util.DiskBenchmark |
Это запустит тест и покажет результаты. Наши результаты для этого случая выглядели хорошо, учитывая аппаратное обеспечение:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
Benchmarking: /mnt/gfs2/disk-benchmark.dat Writes: 639996 writes of size 4096 written in 10.569 seconds. 60554.074 writes/second. 236.53935 megs/second. Sync Writes: 23720 writes of size 4096 written in 10.001 seconds. 2371.763 writes/second. 9.264699 megs/second. Reads: 3738602 reads of size 4096 read in 10.001 seconds. 373822.8 writes/second. 1460.2454 megs/second. |
Увеличение размера блока до 4 МБ (это максимальный размер по умолчанию для ActiveMQ):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
java -classpath "lib/*" \org.apache.activemq.store.kahadb.disk.util.DiskBenchmark \--bs=4194304Benchmarking: /mnt/gfs2/disk-benchmark.dat Writes: 621 writes of size 4194304 written in 10.235 seconds. 60.674156 writes/second. 242.69662 megs/second. Sync Writes: 561 writes of size 4194304 written in 10.017 seconds. 56.00479 writes/second. 224.01917 megs/second. Reads: 2280 reads of size 4194304 read in 10.004 seconds. 227.90884 writes/second. 911.6354 megs/second. |
Эти записи синхронизации 9.x мег / с и 224.x мег / с не совпали с нашими 76 мс / с, поэтому мы копали немного глубже.
Огромное спасибо Роберту Петерсону (Robert Peterson) из Red Hat, работающему в команде по хранению… После просеивания сквозных связей и использования знаний Боба о файловой системе / хранилище мы смогли увидеть, что, поскольку размер файла продолжает расти с каждой записью, ОС действительно будет также синхронизировать метаданные, поэтому не ускорит запись с этим флагом JVM, чтобы пропустить обновления метаданных. Боб рекомендовал, чтобы мы предварительно распределили файлы, в которые мы записываем … и затем меня поразило … хм … это то, что делал утилита Disk Benchmark!
Поэтому после написания патча для предварительного размещения файлов журнала мы увидели, что наши показатели производительности выросли с 76 TPS до 2000 TPS. Я провел некоторое быстрое тестирование на других файловых системах, и, похоже, это заметно повлияло на это, хотя я не могу сказать наверняка без более тщательного тестирования.
Итак, теперь с этим патчем мы можем настроить KahaDB для «предварительного выделения» файлов журнала. Из коробки он предварительно выделит файл как разреженный файл . Этот тип файла может быть или не быть достаточным для ваших потребностей настройки, поэтому попробуйте сначала. Для нас этого было недостаточно — нам нужно было предварительно распределить блоки / структуры, поэтому мы предварительно распределили с нулями:
|
1
2
|
<kahaDB directory="/mnt/gfs2/kahadb" \enableJournalDiskSyncs="true" preallocationStrategy="zeros" /> |
Это позволило нам выполнять синхронизацию / fsync данных и сохранять обновления метаданных, а также снижало нагрузку на файловую систему для распределения этих блоков. Это привело к резкому увеличению производительности.
Обратите внимание, что есть три стратегии предварительного распределения:
-
sprase_file— по умолчанию, из коробки -
zeros— ActiveMQ предварительно выделяет файл, записывая нули (0 × 00) в эти блоки -
os_kernel_copy— ActiveMQ делегирует распределение операционной системе
Проверьте, какой из них лучше работает для вас. Я также работаю над патчем, чтобы сделать предварительное распределение пакетами против всего файла.
См. Документацию для получения дополнительной информации о KahaDB и предварительном распределении.
Окончательные результаты
После некоторого быстрого тестирования сценариев я заметил увеличение производительности в разных файловых системах, используемых для этого конкретного варианта использования. Конечно, ваше тестирование / оборудование / сценарии / ОС / сеть / конфигурация / filessytem и т. Д. Может сильно отличаться от того, которое использовалось в этом тесте, поэтому спросите у компьютера, прежде чем приступить к работе. Тем не менее, наши цифры для этого варианта использования на нашем модельном, неинтересном оборудовании
|
1
2
3
4
5
6
|
| strategy |Local storage | GFS2 | NFSv4|------------------|--------------|----------|---------| `sparse_file` | 64 m/s | 76 m/s | 522 m/s || `zeros` | 163 m/s | 2072 m/s | 613 m/s || `os_kernel_copy` | 162 m/s | BUG | 623 m/s | ------------------------------------------------------ |
НОТА!!!!
Просто отметьте, что для опции os_kernel_copy он может не работать, если он работает на RHEL 6.x / 7.x и использует GFS2, поэтому держитесь подальше от этого, пока ошибка ядра не будет исправлена :)
| Ссылка: | Повышение производительности ActiveMQ в области обмена сообщениями в 25 раз от нашего партнера по JCG Кристиана Поста в блоге |