Вступление
В моем предыдущем посте я описал, как транзакции уровня приложения предлагают подходящий механизм управления параллелизмом для длинных разговоров.
Все объекты загружаются в контексте Hibernate Session, выступая в качестве транзакционного кэша с обратной записью .
Контекст персистентности Hibernate может содержать одну и только одну ссылку на данный объект. Кэш первого уровня гарантирует повторяющиеся чтения на уровне сеанса.
Если разговор охватывает несколько запросов, у нас могут быть повторяемые операции чтения на уровне приложения. Длинные разговоры по своей сути являются состоянием, поэтому мы можем выбрать отдельные объекты или контексты длительного хранения . Но повторяемые операции чтения на уровне приложения требуют стратегии управления параллелизмом на уровне приложения, такой как оптимистическая блокировка.
Подвох
Но такое поведение может оказаться неожиданным время от времени.
Если ваша Hibernate Session уже загрузила данную сущность, то любой последующий запрос сущности (JPQL / HQL) будет возвращать ту же самую ссылку на объект (без учета текущего загруженного снимка базы данных):
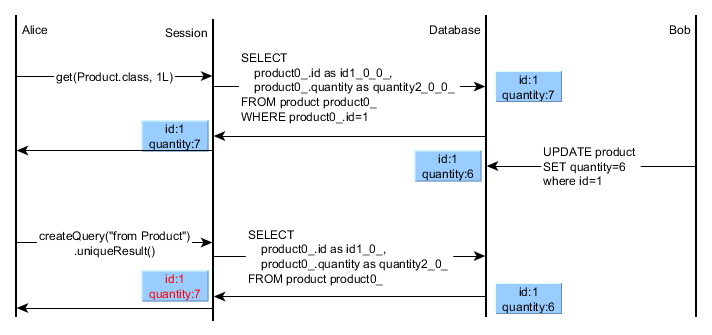
В этом примере мы видим, что кэш первого уровня предотвращает перезапись уже загруженного объекта. Чтобы доказать это поведение, я придумал следующий тестовый пример:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
final ExecutorService executorService = Executors.newSingleThreadExecutor();doInTransaction(new TransactionCallable<Void>() { @Override public Void execute(Session session) { Product product = new Product(); product.setId(1L); product.setQuantity(7L); session.persist(product); return null; }});doInTransaction(new TransactionCallable<Void>() { @Override public Void execute(Session session) { final Product product = (Product) session.get(Product.class, 1L); try { executorService.submit(new Callable<Void>() { @Override public Void call() throws Exception { return doInTransaction(new TransactionCallable<Void>() { @Override public Void execute(Session _session) { Product otherThreadProduct = (Product) _session.get(Product.class, 1L); assertNotSame(product, otherThreadProduct); otherThreadProduct.setQuantity(6L); return null; } }); } }).get(); Product reloadedProduct = (Product) session.createQuery("from Product").uniqueResult(); assertEquals(7L, reloadedProduct.getQuantity()); assertEquals(6L, ((Number) session.createSQLQuery("select quantity from Product where id = :id").setParameter("id", product.getId()).uniqueResult()).longValue()); } catch (Exception e) { fail(e.getMessage()); } return null; }}); |
Этот тестовый пример ясно иллюстрирует различия между запросами сущностей и проекциями SQL. В то время как проекции SQL-запросов всегда загружают последнее состояние базы данных, результаты запросов сущностей управляются кэшем первого уровня, обеспечивая повторяющиеся чтения на уровне сеанса.
Обходной путь 1. Если ваш вариант использования требует перезагрузки самого последнего состояния объекта базы данных, вы можете просто обновить рассматриваемый объект.
Обходной путь 2: Если вы хотите, чтобы объект был отделен от кэша первого уровня Hibernate, вы можете легко его удалить , поэтому в следующем запросе объекта можно использовать последнее значение объекта базы данных.
Помимо предубеждений
Спящий режим — это средство, а не цель. Уровень доступа к данным требует как чтения, так и записи, и ни простой JDBC, ни Hibernate не являются универсальными решениями. Стек знаний о данных намного лучше подходит для получения большинства ваших запросов на чтение данных и написания DML-операторов.
В то время как нативный SQL остается де-факто техникой чтения реляционных данных, Hibernate преуспевает в записи данных. Hibernate — это постоянная структура, и вы никогда не должны забывать об этом. Загрузка объектов имеет смысл, если вы планируете распространять изменения обратно в базу данных. Вам не нужно загружать объекты для отображения представлений, доступных только для чтения, в этом случае гораздо более подходящей является проекция SQL.
Повторяемые операции чтения на уровне сеанса предотвращают потерю обновлений в сценариях одновременной записи, поэтому есть веская причина, по которой сущности не обновляются автоматически. Возможно, мы выбрали ручную очистку грязных свойств, и автоматическое обновление объекта может перезаписать синхронизированные ожидающие изменения.
Разработка шаблонов доступа к данным не является тривиальной задачей, и стоит инвестировать в надежный фундамент тестирования интеграции . Чтобы избежать любых неизвестных действий, я настоятельно рекомендую вам проверить все автоматически сгенерированные операторы SQL, чтобы доказать их эффективность и результативность .
- Код доступен на GitHub .
| Ссылка: | Повторяемые чтения на уровне приложения Hibernate от нашего партнера JCG Влада Михалча в блоге Влада Михалча . |