Вступление
В моей предыдущей статье мы использовали только одну таблицу, что касается нашего примера. Теперь в этой статье мы увидим, как разные таблицы соединяются друг с другом и создают единый набор данных с помощью JOIN. Когда в T-SQL введена команда JOIN, она будет разрешена с помощью оператора Join. Надеюсь, это будет интересно.
SELECTe.JobTitle, a.City, p.LastName + ', ' + p.FirstName AS EmployeeName FROM HumanResources.Employee AS e INNER JOIN Person.BusinessEntityAddress AS bea ON e.BusinessEntityID = bea.BusinessEntityID INNER JOIN Person.Address a ON bea.AddressID = a.AddressID INNER JOIN Person.Person AS p ON e.BusinessEntityID = p.BusinessEntityID;
Если мы посмотрим на вышеупомянутый запрос, то имя и фамилия объединяются вместе как осмысленные манеры. Теперь мы смотрим на план выполнения.

Чтобы прочитать этот план выполнения, мы переходим справа налево. Здесь мы должны определить наиболее дорогостоящую операцию в плане выполнения.
1. Сканирование индекса по таблице Person.Address (31%).
2. Операция хэш-совпадения между таблицей Person.Person и выходными данными
первого хэш- сопоставления (21%).
3. Другой оператор соединения Hash Match между таблицей Person.Address и выходными данными
оператора Nested Loop (20%).
В этом запросе есть несколько проблемных операторов, так как в целом нам лучше выполнять операции поиска, а не операции сканирования.
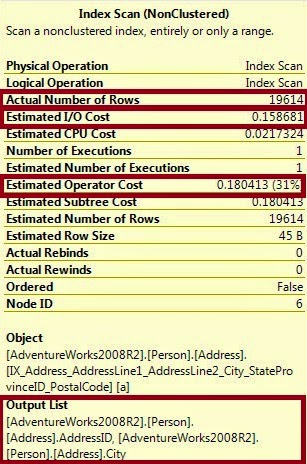
Оптимизатор запросов должен был попасть в столбцы AddressId и City, как показано в списке вывода в нижней части всплывающей подсказки. Пожалуйста, посмотрите на список вывода всплывающей подсказки на рисунке выше.
Оптимизатор запросов рассчитывает стоимость на основе индекса и статистики объектов таблицы. Здесь требуется
фактическое количество строк 19614. Это означает, что данные должны были сканировать строку индекса по строкам, а строки 19641 — это расчетная стоимость 31%, а общая расчетная стоимость
операции — 0,158681 (31%).
Здесь « Оценочная стоимость операции» означает стоимость Оптимизатора запросов для выполнения конкретной операции. Чем ниже оценочная стоимость операции, тем эффективнее операция. Это не означает, что, рассматривая ориентировочную стоимость операции, мы решаем, что это самая дорогая операция. Мы должны рассчитать и другие факторы.
Что такое Match Match Join
В этом плане выполнения мы также находим операторы соединения с хэш-соответствием . Сначала мы должны понять, что он делает.
Hash Match просто помещает два набора данных во временную таблицу с именем Hash Table и использует эту структуру для сравнения данных, поступающих в соответствующий набор.
Здесь в нашем плане выполнения мы находим два оператора соединения Hash Match. Сначала мы находим непосредственно перед операторами SELECT (необходимо читать справа налево). Он просто присоединяется к выводу INDEX SCAN с выводом остальных операторов в запросе. Это вторая самая дорогая операция в наших планах исполнения. Теперь мы видим свойство всплывающей подсказки этого Hash Match Join.
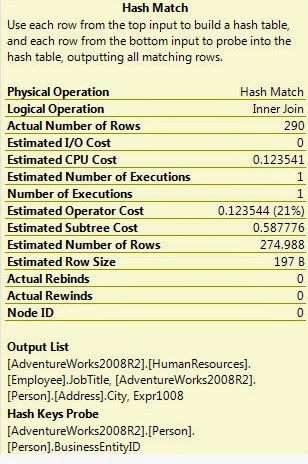
Таким образом, мы должны понимать Hash Match, но перед этим мы должны бросить бросок с двумя понятиями, называемыми Hash и Hash Table.
Хэш
Это программный метод, при котором данные преобразуются в символические формы для более эффективного поиска данных. SQL Server программно преобразует строку данных в таблице в уникальное значение, представляющее содержимое строки. Мы можем сказать это как шифрование, хеш-значение, преобразованное в исходные данные.
Хеш-таблица
Это структура данных и обеспечивает быстрый доступ к элементу. Сервер SQL берет строку из таблицы, хеширует ее в хеш-значение и сохраняет хеш-значение в хеш-таблице в temp db.
Примечание: для получения дополнительной информации, пожалуйста, поиск в Google.
Теперь перенесите его в наш основной поток, операторы Hash Match Join, когда SQL-сервер должен объединить два больших набора данных. Он решает сделать это путем хеширования строки из меньшего из двух наборов данных и вставки их в хеш-таблицу. Затем он обрабатывает больший набор данных, по одной строке за раз, в хеш-таблице в поисках совпадений, указывая строки, которые должны быть объединены.
Если хеш-таблица относительно мала, процесс может быть быстрым. Если обе таблицы очень велики, соединение по хэшу Match может быть очень неэффективным по сравнению с другим типом объединения. Поскольку все данные хранятся в Temp DB, чрезмерное использование Hash Join в нашем запросе увеличивает нагрузку на Temp DB.
В нашем примере данные из
HumanResources.Employee сопоставляются с
таблицей Person.Person . Соединение с хэш-соответствием происходит хорошо в таблице, которая не отсортирована по столбцам JOIN, что означает отсутствие пригодного для использования индекса. Вот в этом случае MERGE JOIN работает лучше.
Отправка соединения Hash Match в план выполнения иногда указывает
1.
Отсутствует или не используется индекс
2. Пропущен пункт «Где»
3. Предложение «Где» с расчетом или преобразованием
Hare for Hash Match Join мы должны исследовать наш запрос. Это означает, что мы должны настроить наш запрос, добавив Index, чтобы сделать операцию Join более эффективной.
http://www.sqlknowledgebank.blogspot.in/2014/10/understanding-of-execution-plan-iii-c.html
http://sqlknowledgebank.blogspot.in/2014/10/understanding-of-execution-plan-iii-b.html
http://www.sqlknowledgebank.blogspot.in/2014/06/understanding-of-execution-plan-what.html
http://www.sqlknowledgebank.blogspot.in/2014/10/understanding-of-execution-plan-ii.html
http://www.sqlknowledgebank.blogspot.in/2014/10/understanding-of-execution-plan-iii-the.html