Вступление

В моей предыдущей статье мы сосредоточимся только на операторах Cluster Index Scan и Clustered Index Seek. Продолжая серию статей под названием «Понимание плана выполнения» — часть III, мы переходим к другим операторам. Пожалуйста, обратите внимание на нашу статью, которую вы можете хорошо изучить в плане выполнения.
Некластерный поиск индекса

Операция является операцией поиска по некластерному индексу. Операция практически не отличается от поиска в кластеризованном индексе, но доступны только те данные, которые хранятся в самом индексе.
Как и при поиске кластеризованного индекса, при поиске некластеризованного индекса используется индекс для поиска необходимых строк. В отличие от поиска кластеризованного индекса, поиск некластеризованного индекса должен использовать некластеризованный индекс для выполнения операции. В зависимости от запроса и индекса оптимизатор запросов может найти все данные в некластеризованном индексе. Однако некластеризованный индекс хранит только ключевые значения; он не хранит данные. Оптимизатору, возможно, придется искать данные в кластеризованном индексе, что несколько снижает производительность из-за дополнительных операций ввода-вывода, необходимых для дополнительного поиска .
Когда нужен индекс покрытия
Если оператор SELECT содержит несколько столбцов Clustered Index или Any, которые не являются частью некластеризованного индекса, в этой ситуации поиск по некластерному индексу не может быть выполнен, и мы всегда получаем сканирование Clustered Index. Чтобы получить некластеризованный индекс Seek, мы должны использовать индекс COVERING .
CREATE INDEX IX_NONCLUST_EMPNAME ON tbl_EMPLOYEERECORD(EMPNAME) INCLUDE (EMPID, EMPGRADE, SALARY)
Здесь важны Predicates для поиска недвижимости, и мы получили от нее всю информацию.
Поиск ключей
Оператор Key Lookup необходим для получения данных из кучи или кластерного индекса, соответственно, когда используется некластеризованный индекс, но не является индексом покрытия.
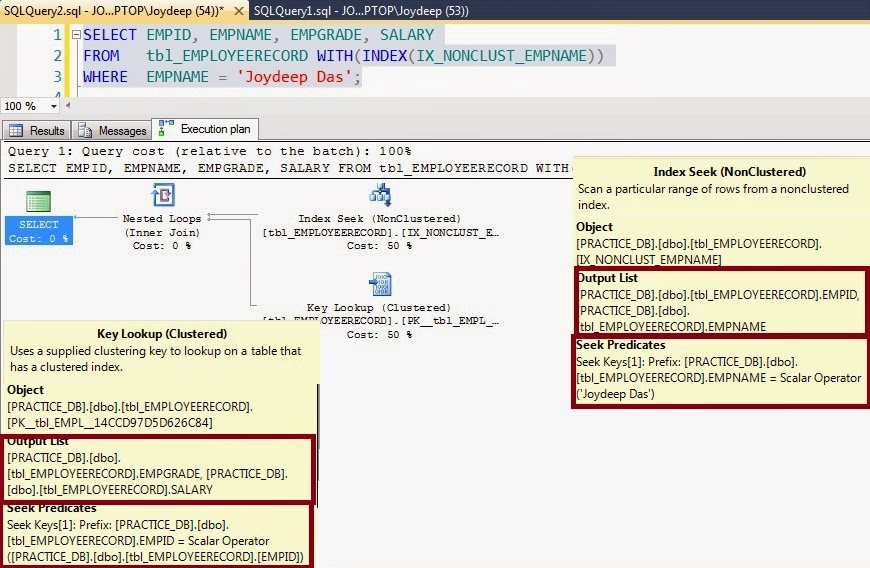
Первая операция, которую мы можем увидеть здесь Поиск индекса по некластерному индексу с именем IX_NONCLUST_EMPNAME
Это неуникальный некластеризованный индекс, и в случае этого запроса он не покрывает. Покрывающий индекс — это некластеризованный индекс, который содержит все столбцы, на которые должен ссылаться запрос, включая столбцы в списке SELECT, критерии JOIN и предложение WHERE .
Поскольку этот индекс не является покрывающим индексом, оптимизатор запросов вынужден не только читать некластеризованный индекс, но также читать кластеризованный индекс, чтобы собрать все данные, необходимые для обработки запроса. Это поиск ключей и, по сути, это означает, что оптимизатор не может извлечь строки за одну операцию и должен использовать кластеризованный ключ для возврата соответствующих строк из кластеризованного индекса.
Во всплывающих подсказках указателя ищите « Выходной список» и « Важность поиска» . Если мы внимательно посмотрим на поисковый приоритет, то обнаружим, что
Ключи поиска [1]: Префикс: [PRACTICE_DB]. [Dbo]. [Tbl_EMPLOYEERECORD] .EMPNAME = Скалярный оператор (‘Joydeep Das’)
Как мы используем в предложении WHERE EMPNAME = ‘Joydeep Das’
Если мы напишем, как «Джойдип дас»
Если мы напишем LIKE ‘Joydeep%’
Ключи поиска [1]: Начало: [PRACTICE_DB]. [Dbo]. [Tbl_EMPLOYEERECORD] .EMPNAME> = Скалярный оператор (‘JoydeeØþ’), Конец: [PRACTICE_DB]. [Dbo]. [Tbl_EMPLOYEERECORD] .EMPNAME <Scale ‘JoydeeQ’)
Как это изменить код.
Здесь из списка вывода мы находим
[PRACTICE_DB]. [Dbo]. [Tbl_EMPLOYEERECORD] .EMPID, [PRACTICE_DB]. [Dbo]. [Tbl_EMPLOYEERECORD] .EMPNAME
Теперь мы рассмотрим подсказки инструмента поиска ключей в кластерном индексе с именем PK__tbl_EMPL__14CCD97D5D626C84.
Здесь в списке вывода мы находим
[PRACTICE_DB]. [Dbo]. [Tbl_EMPLOYEERECORD] .EMPGRADE, [PRACTICE_DB]. [Dbo]. [Tbl_EMPLOYEERECORD] .SALARY
В поисках приоритетов мы находим
Ключи поиска [1]: Префикс: [PRACTICE_DB]. [Dbo]. [Tbl_EMPLOYEERECORD] .EMPID = Скалярный оператор ([PRACTICE_DB]. [Dbo]. [Tbl_EMPLOYEERECORD]. [EMPID])
Если бы эта таблица была кучей, таблицей без кластеризованного индекса, оператор был бы оператором поиска RID. RID обозначает идентификатор строки, средство, с помощью которого строки в таблице кучи однозначно помечаются и хранятся в таблице. Основы работы поиска RID такие же, как поиск ключа.
Ссылки по теме
Понимание плана выполнения [что произошло при выполнении инструкции SQL]
http://www.sqlknowledgebank.blogspot.in/2014/06/understanding-of-execution-plan-what.html
Понимание плана выполнения — II [Повторное использование плана выполнения]
http://www.sqlknowledgebank.blogspot.in/2014/10/understanding-of-execution-plan-ii.html
Понимание плана выполнения — III — A [ОПЕРАТОРЫ]
http://www.sqlknowledgebank.blogspot.in/2014/10/understanding-of-execution-plan-iii-the.html
Резюме
На нашем следующем уровне мы будем обсуждать больше операторов по одному. Надеюсь, вам понравится и вам нужны ваши ценные комментарии, связанные с ним.