Прежде всего, позвольте мне сказать это вслух: Spring больше не перегружен XML . На самом деле вы можете писать приложения Spring в настоящее время с минимальным количеством XML или вообще без него, используя множество аннотаций, конфигурацию Java и Spring Boot . Серьезно прекратите разглагольствовать о Spring и XML, это дело прошлого.
При этом вы, возможно, по-прежнему используете XML по нескольким причинам: вы застряли с устаревшей базой кода, вы выбрали XML по другим причинам или используете Spring в качестве основы для какой-либо платформы / платформы. Последний случай на самом деле довольно распространен, например, Mule ESB и ActiveMQ используют Spring для привязки своих зависимостей. Более того, Spring XML — это их способ настройки фреймворка. Однако настройка посредника сообщений или служебной шины предприятия с использованием простых Spring <bean/> s будет громоздкой и многословной. К счастью, Spring поддерживает написание пользовательских пространств имен, которые могут быть встроены в стандартные файлы конфигурации Spring. Эти пользовательские фрагменты XML предварительно обрабатываются во время выполнения и могут регистрировать сразу несколько определений bean-компонентов в кратком и приятном на вид (насколько позволяет XML) формате. В некотором смысле пользовательские пространства имен похожи на макросы, которые расширяются во время выполнения в несколько определений bean-компонентов.
Чтобы дать вам представление о том, к чему мы стремимся, представьте стандартное «корпоративное» приложение, в котором есть несколько бизнес-объектов. Для каждой сущности мы определяем три, почти идентичных компонента: репозиторий, сервис и контроллер. Они всегда подключены одинаково и отличаются только мелкими деталями. Начнем с того, что наш Spring XML выглядит так (я вставляю скриншот с миниатюрой, чтобы сэкономить ваши глаза, он огромный и раздутый): 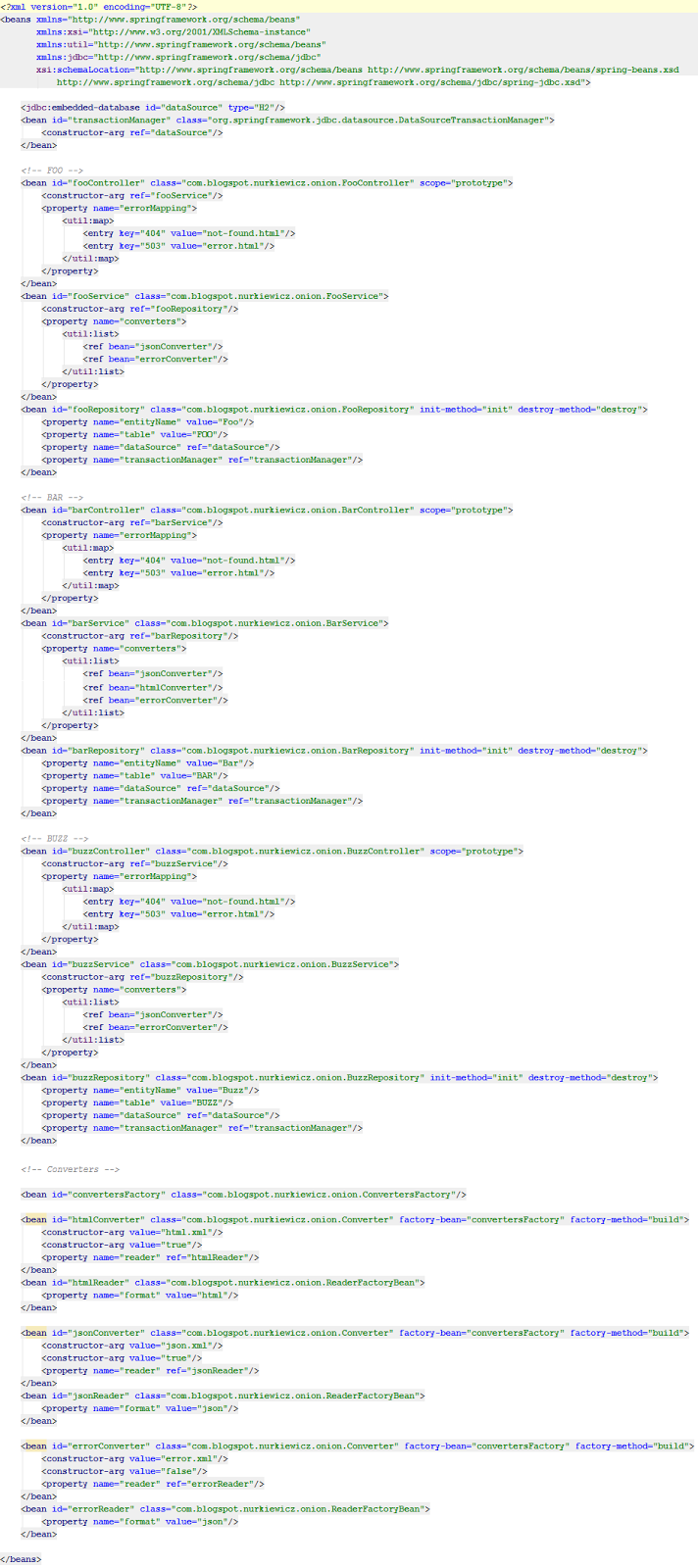
Это «многоуровневая» архитектура, поэтому мы будем называть наше собственное пространство имен « onion — потому что у луков есть слои — а также потому, что системы, спроектированные таким образом, заставляют меня плакать. К концу этой статьи вы узнаете, как свернуть эту кучу XML в:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
<?xml version="1.0" encoding="UTF-8"?> xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://nurkiewicz.blogspot.com/spring/onion/spring-onion.xsd http://nurkiewicz.blogspot.com/spring/onion/spring-onion.xsd"> <b:bean id="convertersFactory" class="com.blogspot.nurkiewicz.onion.ConvertersFactory"/> <converter format="html"/> <converter format="json"/> <converter format="error" lenient="false"/> <entity class="Foo" converters="json, error"> <page response="404" dest="not-found"/> <page response="503" dest="error"/> </entity> <entity class="Bar" converters="json, html, error"> <page response="400" dest="bad-request"/> <page response="500" dest="internal"/> </entity> <entity class="Buzz" converters="json, html"> <page response="502" dest="bad-gateway"/> </entity> </b:beans> |
Посмотрите внимательно, это все еще Spring XML-файл, который совершенно понятен этой платформе — и вы узнаете, как этого добиться. Вы можете запустить произвольный код для каждого пользовательского тега XML верхнего уровня, например, единственное вхождение <entity/> registers репозиторий, определения сервисов и компонентов контроллера одновременно. Первое, что нужно реализовать, — это написать собственную XML-схему для нашего пространства имен. Это не так сложно и позволит IntelliJ IDEA показывать завершение кода в XML:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
<?xml version="1.0" encoding="UTF-8"?><schema elementFormDefault="qualified" attributeFormDefault="unqualified"> <element name="entity"> <complexType> <sequence> <element name="page" type="tns:Page" minOccurs="0" maxOccurs="unbounded"/> </sequence> <attribute name="class" type="string" use="required"/> <attribute name="converters" type="string"/> </complexType> </element> <complexType name="Page"> <attribute name="response" type="int" use="required"/> <attribute name="dest" type="string" use="required"/> </complexType> <element name="converter"> <complexType> <attribute name="format" type="string" use="required"/> <attribute name="lenient" type="boolean" default="true"/> </complexType> </element> </schema> |
Как только схема завершена, мы должны зарегистрировать ее в Spring, используя два файла:
/META-INF/spring.schemas :
|
1
|
http\://nurkiewicz.blogspot.com/spring/onion/spring-onion.xsd=/com/blogspot/nurkiewicz/onion/ns/spring-onion.xsd |
/META-INF/spring.handlers :
|
1
|
http\://nurkiewicz.blogspot.com/spring/onion/spring-onion.xsd=com.blogspot.nurkiewicz.onion.ns.OnionNamespaceHandler |
Один отображает URL схемы локально в расположение схемы, другой указывает на так называемый обработчик пространства имен. Этот класс довольно прост — он сообщает, что делать с каждым пользовательским тегом XML верхнего уровня, поступающим из этого пространства имен, встречающегося в файле конфигурации Spring:
|
1
2
3
4
5
6
7
8
|
import org.springframework.beans.factory.xml.NamespaceHandlerSupport; public class OnionNamespaceHandler extends NamespaceHandlerSupport { public void init() { registerBeanDefinitionParser("entity", new EntityBeanDefinitionParser()); registerBeanDefinitionParser("converter", new ConverterBeanDefinitionParser()); }} |
Итак, когда Spring находит <converter format="html"/> кусок XML, он знает, что необходимо использовать наш ConverterBeanDefinitionParser . Помните, что если у нашего пользовательского тега есть дочерние элементы (как в случае <entity/> ), анализатор определения компонента вызывается только для тега верхнего уровня. Это зависит от нас, как мы разбираем и обрабатываем детей. Итак, один <converter/> должен создать следующие два компонента:
|
1
2
3
4
5
6
7
8
|
<bean id="htmlConverter" class="com.blogspot.nurkiewicz.onion.Converter" factory-bean="convertersFactory" factory-method="build"> <constructor-arg value="html.xml"/> <constructor-arg value="true"/> <property name="reader" ref="htmlReader"/></bean><bean id="htmlReader" class="com.blogspot.nurkiewicz.onion.ReaderFactoryBean"> <property name="format" value="html"/></bean> |
Ответственность синтаксического анализатора определений бина состоит в том, чтобы программно зарегистрировать определения бина, иначе определенные в XML. Я не буду вдаваться в подробности API, но сравните его с приведенным выше фрагментом XML, они близко соответствуют друг другу:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
import org.w3c.dom.Element; public class ConverterBeanDefinitionParser extends AbstractBeanDefinitionParser { @Override protected AbstractBeanDefinition parseInternal(Element converterElement, ParserContext parserContext) { final String format = converterElement.getAttribute("format"); final String lenientStr = converterElement.getAttribute("lenient"); final boolean lenient = lenientStr != null? Boolean.valueOf(lenientStr) : true; final BeanDefinitionRegistry registry = parserContext.getRegistry(); final AbstractBeanDefinition converterBeanDef = converterBeanDef(format, lenient); registry.registerBeanDefinition(format + "Converter", converterBeanDef); final AbstractBeanDefinition readerBeanDef = readerBeanDef(format); registry.registerBeanDefinition(format + "Reader", readerBeanDef); return null; } private AbstractBeanDefinition readerBeanDef(String format) { return BeanDefinitionBuilder. rootBeanDefinition(ReaderFactoryBean.class). addPropertyValue("format", format). getBeanDefinition(); } private AbstractBeanDefinition converterBeanDef(String format, boolean lenient) { AbstractBeanDefinition converterBeanDef = BeanDefinitionBuilder. rootBeanDefinition(Converter.class.getName()). addConstructorArgValue(format + ".xml"). addConstructorArgValue(lenient). addPropertyReference("reader", format + "Reader"). getBeanDefinition(); converterBeanDef.setFactoryBeanName("convertersFactory"); converterBeanDef.setFactoryMethodName("build"); return converterBeanDef; }} |
Вы видите, как parseInternal() получает Element XML, представляющий <converter/> , извлекает атрибуты и регистрирует определения бинов? Вам решать, сколько bean-компонентов вы определяете в реализации AbstractBeanDefinitionParser . Просто помните, что мы только строим конфигурацию здесь, инстанцирование еще не было. Как только XML-файл будет полностью проанализирован и все анализаторы bean-компонентов сработают, Spring начнет загрузку нашего приложения. Нужно иметь в виду, что в конце возвращается null . API-интерфейс ожидает, что вы вернете определение одного компонента. Однако не нужно ограничивать себя, все в порядке.
Второй поддерживаемый нами пользовательский тег — это <entity/> который регистрирует три бина одновременно. Это похоже и, следовательно, не так интересно, см. Полный источник EntityBeanDefinitionParser . Здесь можно найти одну важную деталь реализации — использование ManagedList . В документации смутно упоминается об этом, но это весьма ценно. Если вы хотите определить список bean-компонентов, которые будут вводиться, зная их идентификаторы, простого List<String> недостаточно, вы должны явно указать Spring, что вы имеете в виду список ссылок на bean-компоненты:
|
1
2
3
4
5
6
7
8
|
List<BeanMetadataElement> converterRefs = new ManagedList<>();for (String converterName : converters) { converterRefs.add(new RuntimeBeanReference(converterName));}return BeanDefinitionBuilder. rootBeanDefinition("com.blogspot.nurkiewicz.FooService"). addPropertyValue("converters", converterRefs). getBeanDefinition(); |
Использование JAXB для упрощения анализаторов определения бина
Итак, теперь вы должны быть знакомы с пользовательскими пространствами имен Spring и с тем, как они могут вам помочь. Однако они довольно низкого уровня, требуя, чтобы вы анализировали пользовательские теги с помощью API-интерфейса XML DOM. Однако мой товарищ по команде обнаружил, что, поскольку у нас уже есть файл схемы XSD, почему бы не использовать JAXB для обработки анализа XML? Сначала мы просим maven генерировать Java-бины, представляющие типы и элементы XML во время сборки:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
<build> <plugins> <plugin> <groupId>org.jvnet.jaxb2.maven2</groupId> <artifactId>maven-jaxb22-plugin</artifactId> <version>0.8.3</version> <executions> <execution> <id>xjc</id> <goals> <goal>generate</goal> </goals> </execution> </executions> <configuration> <schemaDirectory>src/main/resources/com/blogspot/nurkiewicz/onion/ns</schemaDirectory> <generatePackage>com.blogspot.nurkiewicz.onion.ns.xml</generatePackage> </configuration> </plugin> </plugins></build> |
В /target/generated-sources/xjc вы обнаружите пару файлов Java. Мне нравится, что сгенерированные модели JAXB имеют префикс некоторых общих, таких как Xml , что может быть легко достигнуто с помощью пользовательского файла bindings.xjb расположенного рядом с spring-onion.xsd :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
<bindings version="1.0" extensionBindingPrefixes="xjc"> <bindings schemaLocation="spring-onion.xsd" node="/xs:schema"> <schemaBindings> <nameXmlTransform> <typeName prefix="Xml"/> <anonymousTypeName prefix="Xml"/> <elementName prefix="Xml"/> </nameXmlTransform> </schemaBindings> </bindings> </bindings> |
Как это меняет наш пользовательский анализатор определения бина? Ранее у нас было это:
|
1
2
3
4
|
final String clazz = entityElement.getAttribute("class");//...final NodeList pageNodes = entityElement.getElementsByTagNameNS(NS, "page");for (int i = 0; i < pageNodes.getLength(); ++i) { //... |
Теперь мы просто переходим Java-бины:
|
1
2
3
4
|
final XmlEntity entity = JaxbHelper.unmarshal(entityElement);final String clazz = entity.getClazz();//...for (XmlPage page : entity.getPage()) { //... |
JaxbHelper — это простой инструмент, который скрывает проверенные исключения и механику JAXB извне:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public class JaxbHelper { private static final Unmarshaller unmarshaller = create(); private static Unmarshaller create() { try { return JAXBContext.newInstance("com.blogspot.nurkiewicz.onion.ns.xml").createUnmarshaller(); } catch (JAXBException e) { throw Throwables.propagate(e); } } public static <T> T unmarshal(Element elem) { try { return (T) unmarshaller.unmarshal(elem); } catch (JAXBException e) { throw Throwables.propagate(e); } } } |
Пару слов в качестве резюме. Прежде всего, я не рекомендую вам автоматически генерировать определения bean-компонентов репозитория / службы / контроллера для каждой сущности. На самом деле это плохая практика, но домен знаком всем нам, поэтому я подумал, что это будет хорошим примером. Во-вторых, что более важно, пользовательские пространства имен XML — это мощный инструмент, который следует использовать в качестве крайней меры при сбое всего остального, а именно абстрактных компонентов , фабричных компонентов и конфигурации Java. Как правило, вам понадобится такая функция в средах или инструментах, встроенных в Spring. В этом случае проверьте полный исходный код на GitHub .