Несколько месяцев назад кто-то в офисе указал нам на интересное предложение о работе от CartoDB, которое выглядело следующим образом:
Далее следует технический тест для этого предложения о работе в CARTO: https://boards.greenhouse.io/cartodb/jobs/705852#.WSvORxOGPUI
Создайте следующее и сделайте так быстро, как вы можете, используя Python 3 (vanilla). Чем быстрее он работает, тем больше вы будете удивлять нас!
Ваш код должен:
- Загрузите этот файл объемом 2,2 ГБ: https://s3.amazonaws.com/carto-1000x/data/yellow_tripdata_2016-01.csv
- Подсчитать строки в файле
- Рассчитать среднее значение поля tip_amount.
Все это наиболее эффективным способом, который вы можете придумать.
Вот и все. Заставь его летать!
Не забудьте подать заявку здесь !: https://boards.greenhouse.io/cartodb/jobs/705852#.WSvORxOGPUI
Прочитав это, я помню, что подумал: «Человек, это хороший повод, чтобы покопаться в core.async Clojure»…… и чем раньше сказал, чем сделал , это то, что я делал несколько дней назад. Вот мои заметки об этом опыте.
Когда начать?
Я уже был знаком с теорией, лежащей в основе core.async (я говорю о передаче последовательных процессов или просто о CSP), но когда пришло время настроить мой проект и начать выкладывать свое решение, я обнаружил, что документация была между дефицитной и обескураживающей , При этом неожиданный спад не остановил меня:
- Я посмотрел все видео Тимоти Болдриджа на эту тему. Обязательно смотреть.
- Богатый внутренний разговор Хикки тоже великолепен .
- Научиться комбинировать преобразователи с каналом I — это то, о чем вы не пожалеете.
- Это немного низкий уровень, но он помогает понять определенные угловые случаи или даже сообщения об ошибках, которые вы можете получить.
- Игра с некоторыми реальными примерами, доступными в пустыне Интернета, также помогает, всегда полагаясь на официальную ссылку API
Все это плюс несколько часов разочарования помогли наконец увидеть свет в конце туннеля. Теперь пришло время для моего собственного кодирования.
неблокирующее чтение файла
Итак, первое, с чего я хотел начать, было чтение всех строк из файла неблокирующим способом , и именно эта цель привела меня к следующей реализации:
|
1
2
3
4
5
6
7
8
|
(defn stream-lines-from [path] (let (go (with-open [rdr (io/reader path)] (doseq [line (line-seq rdr)] (>! c line))) (close! c)) c)) |
Позвольте мне разобрать это для вас:
- Я начну с определения канала c с размером буфера 1024 . Размер не обязателен, но я подумал, что было бы неплохо буферизовать строки, чтобы избежать максимально возможной блокировки потока-потребителя.
- Тогда у нас есть блок-блок — краеугольный камень библиотеки. Это главным образом позволяет асинхронно выполнять тело, возвращаясь немедленно к вызывающему потоку. В этом конкретном блоке мы будем делать следующее:
- Начинает читать строки из исходного файла
- Каждая строка передается на канал с помощью >! оператор.
- Когда достигнут конец файла, канал закрывается при закрытии! оператор.
- Наконец, с нашим определенным блоком go мы возвращаем канал для дальнейшего потребления.
Подсчет линий
Я не уверен, как вам всем нравится решать проблему, но лично я всегда начинаю с решения самых крошечных из них и начинаю искать решение оттуда — по одной проблеме за раз. В этом конкретном случае я разработал простую функциональность, где, учитывая канал линий , я могу считать их все, пока он не закроется. И вот что я сделал:
|
1
2
3
4
5
|
(defn w-counter [channel] (go-loop [total 0] (if-some [_ (<! channel)] (recur (inc total)) total))) |
Как обычно, здесь есть пара новых конструкций:
- Блок go-loop позволяет нам выполнить цикл внутри блока go. Это то же самое, что и делать (иди (цикл …). Кроме того, в качестве напоминания go-block возвращает вызывающему каналу канал, который получит результат тела (в данном конкретном сценарии общее количество строк).
- <! Оператор — это способ, которым мы должны прочитать значение из канала, если он доступен, иначе он будет парковать поток. Стоит отметить, что когда канал закрыт , он возвращает ноль , что приводит к возобновлению подсчета.
Как вы можете видеть, выполняя некоторую рекурсию, я продолжаю потреблять и считать линии из канала до тех пор, пока он не закроется ( если кто-то делает работу плавно ) , возвращая окончательный счет вызывающей стороне. Теперь, когда все было готово, я хотел добиться следующей операции подсчета, но одновременно с каким-то образом контролировать количество счетчиков, выполняющих эту работу. Итак, после некоторой разработки, основанной на REPL, вот что я получил:
|
1
2
3
4
|
(defn count-lines [channel npar] (let [counters (for [_ (range npar)] (w-counter channel))] (async/reduce + 0 (async/merge counters)))) |
И это был момент, когда вещи начали щелкать в моей голове. Просто выполняя простое понимание с использованием моей предыдущей функции w-counter вместе с асинхронной комбинацией слияния и уменьшения, она наконец добилась цели всего за 3 чертовых строки кода . Итак, что это за два комбинатора?
- async / merge позволил мне взять все значения из всех каналов и вернуть один канал, содержащий все из них. Это было удобно, чтобы собрать все частичные результаты от всех моих работников.
- Асинхронизация / уменьшение была самой лучшей чертой, поскольку она позволяла мне объединять все частичные подсчеты в конечные результаты, в данном конкретном случае — общий подсчет.
Вы можете представить поток как что-то вроде этого:
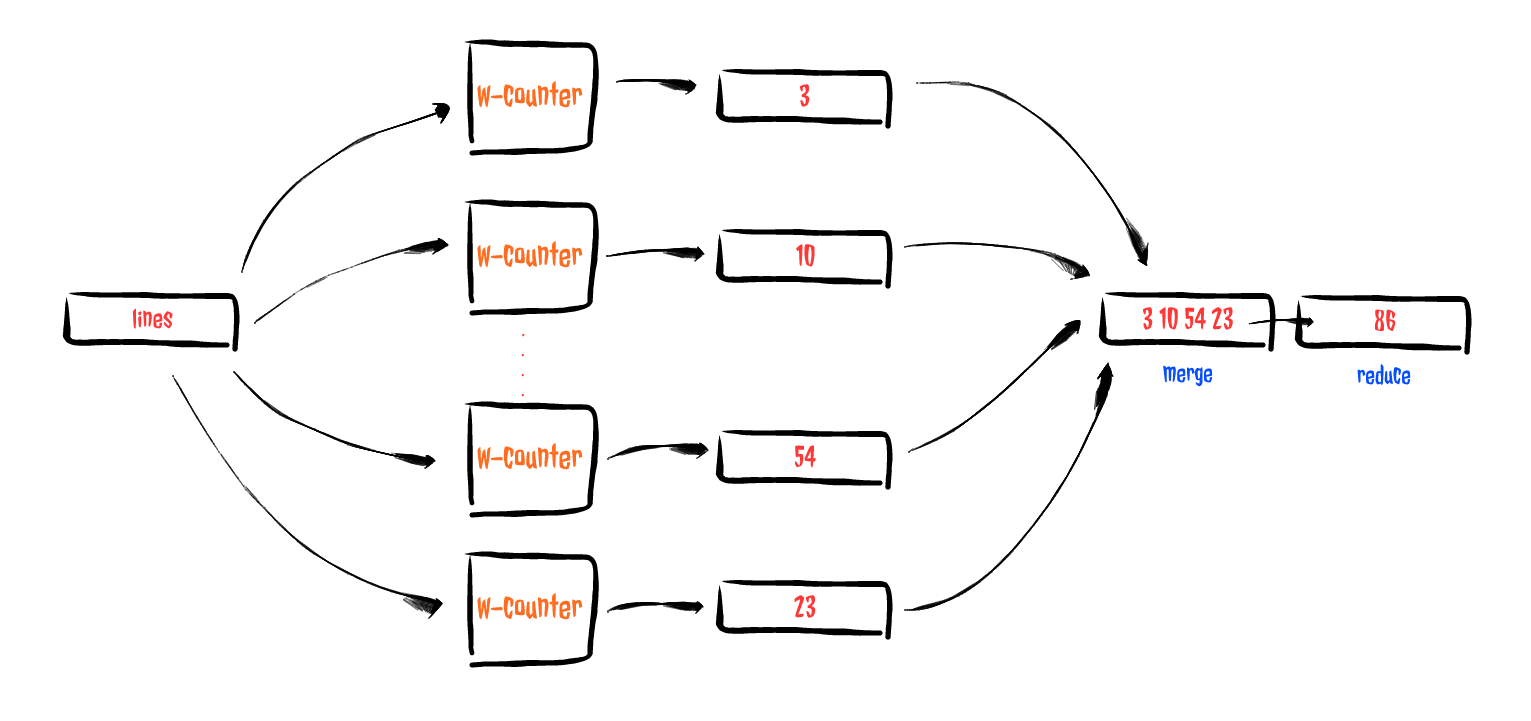
Острота!
Хитрая хитрая агрегация
С подсчетом строк в моем кармане пришло время заняться агрегацией, но, чтобы понять, почему я сделал то, что сделал, давайте начнем с проверки структуры исходного файла.
|
1
2
3
4
5
|
VendorID,tpep_pickup_datetime,tpep_dropoff_datetime,passenger_count,trip_distance,pickup_longitude,pickup_latitude,RatecodeID,store_and_fwd_flag,dropoff_longitude,dropoff_latitude,payment_type,fare_amount,extra,mta_tax,tip_amount,tolls_amount,improvement_surcharge,total_amount2,2016-01-01 00:00:00,2016-01-01 00:00:00,2,1.10,-73.990371704101563,40.734695434570313,1,N,-73.981842041015625,40.732406616210937,2,7.5,0.5,0.5,0,0,0.3,8.82,2016-01-01 00:00:00,2016-01-01 00:00:00,5,4.90,-73.980781555175781,40.729911804199219,1,N,-73.944473266601563,40.716678619384766,1,18,0.5,0.5,0,0,0.3,19.32,2016-01-01 00:00:00,2016-01-01 00:00:00,1,10.54,-73.984550476074219,40.6795654296875,1,N,-73.950271606445313,40.788925170898438,1,33,0.5,0.5,0,0,0.3,34.32,2016-01-01 00:00:00,2016-01-01 00:00:00,1,4.75,-73.99346923828125,40.718990325927734,1,N,-73.962242126464844,40.657333374023437,2,16.5,0,0.5,0,0,0.3,17.3 |
Легко видеть, что первая строка всегда будет включать заголовки, а остальная часть файла будет состоять из значений в формате CSV . Теперь, если вы помните упражнение, он попросил нас агрегировать поле tip_amount, но в соответствии с этим мы должны сначала выяснить, какой индекс должен использоваться для определения местоположения агрегируемого значения .
По правде говоря, я начал с простого решения крошечной проблемы, поэтому мне пришла в голову идея, прочитав первое значение канала (которое совпадает с заголовками), я могу определить функцию, способную извлекать значение, которое я ищу каждый раз, когда вводить строку, и вот что я получил:
|
1
2
3
4
5
6
7
8
|
(defn extract-field-fn [fname channel] (let [headers (<!! channel) field-idx (->> (split headers #",") (map-indexed vector) (filter (fn [[_ v]] (= v fname))) first first)] #(java.lang.Double/parseDouble (nth (split % #",") field-idx)))) |
Он начинается с ожидания первого значения из канала (помните, что мы обязательно выводим индекс перед выполнением агрегации), и именно поэтому я использовал <!! заблокировать, пока значение не станет доступным. Затем, с удобной первой строкой, я разделил ее, чтобы позже найти позицию, в которой находилось поле с именем fname , и, наконец, вернуть частичную функцию, которая может извлекать и анализировать запрошенное поле по требованию.
После этого следующей проблемой, которая должна быть решена, было вычисление среднего значения последовательности значений, поступающих из канала. К этому времени я усвоил несколько очень важных уроков, которые проложили мне путь к следующей реализации:
|
1
2
3
4
5
|
(defn w-aggregate [channel] (go-loop (if-some [n (<! channel)] (recur (inc c) (+ n s)) [s c]))) |
Я надеюсь, вы видите, что я следовал аналогичной реализации, как и для подсчета строк, но на этот раз мне пришлось суммировать и подсчитывать каждое значение, пока канал не закроется. Легкий покой.
Наконец, с этими двумя небольшими функциями я смог построить свое асинхронное решение средней задачи по полю, которое выглядит следующим образом:
|
01
02
03
04
05
06
07
08
09
10
11
|
(defn aggregate-field [fname channel npar] (let [as-value-fn (extract-field-fn fname channel) fvalue-chan (pipe channel (chan 1024 (map as-value-fn))) fvalue-aggregator (for [_ (range npar)] (w-aggregate fvalue-chan))] (go (let [[sum count] (<! (async/reduce #(apply map + [%1 %2]) [0.0 0] (async/merge fvalue-aggregator)))] (/ sum count))))) |
Это более или менее то, что происходит:
- Мы начнем с создания частичной функции, которая по имени поля и каналу определяет функцию, которая считывает значение поля из строки.
- Следующее, что мы делаем, это направляем входящий канал-канал в канал -значение-поле … почему я так поступил? … потому что каналы поддерживают преобразователи !!! Здесь я определяю преобразователь, способный отображать строку в значение, которое необходимо агрегировать (map as-value-fn), и использую его для определения нового канала, который испускает все значения, которые необходимо агрегировать. Это было очень хорошо.
- Используя преобразованный канал fvalue-chan вместе с функцией для понимания, используя функцию w-aggregate , все, что мне нужно было сделать, это подсчитать и суммировать входящие значения одновременно.
- Наконец, комбинируя запросы на уменьшение и объединение для одной и той же цели, я собираю частичные подсчеты и суммы, чтобы окончательно вычислить среднее значение запрошенного значения, просто разделив их.
Вы можете изобразить поток следующим образом:
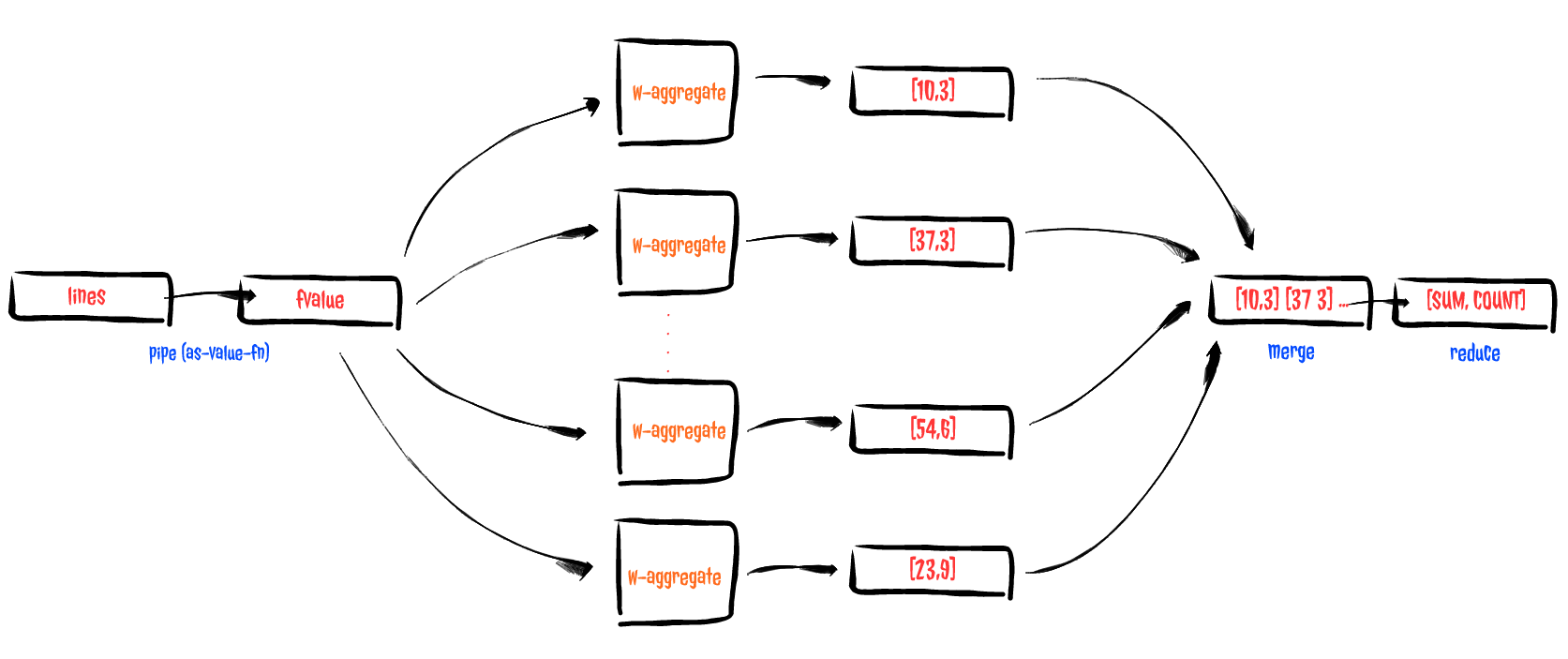
Делать это все одновременно
Как решить проблему с количеством строк и средним значением поля, как их объединить? И именно тогда ссылка на API сыграла важную роль в этой истории, так как мне удалось найти оператор mult . Согласно документации ..
Создает и возвращает мульт (iple) предоставленного канала. Каналы, содержащие копии канала, могут быть созданы с помощью «tap» и отключены с помощью «untap».
и это щелкнуло … снова … поэтому я попробовал это
|
1
2
3
4
5
6
7
8
9
|
(defn process! [path fname npar] (let [lines (mult (stream-lines-from path)) aggregate-tap (tap lines (chan 1024)) count-tap (tap lines (chan 1024))] (<!! (async/reduce (fn [_ v] (println v)) "" (async/merge [(aggregate-field fname aggregate-tap npar) (count-lines count-tap npar)]))))) |
И это сработало !! Давайте посмотрим, что у нас здесь:
- Помните функцию stream-lines-from ? Это место, где вы его используете, мы указываем путь к исходному файлу и возвращаем канал, где будут опубликованы все строки, но, поскольку нам нужно использовать эти строки дважды (для подсчета и усреднения), мы объявляем этот канал как mult.
- Затем дважды коснемся канала линий : один раз для подсчета потока, а другой — для среднего потока. Используя tap , мы можем скопировать многоканальный канал на предоставленный канал, и, таким образом, мы можем без труда отправить каждую строку в подсчет и усреднение потоков, используя параллелизм!
- Наконец, мы передаем в каждом из каналов отводов функции агрегатного поля и счетчика и ожидаем, пока все они завершатся блокирующим (оператор <!! ) слиянием / уменьшением .
Последние мысли
Это летало? Не совсем: подсчет был «быстрым» (на моем ноутбуке это заняло около минуты), но агрегирование значений было медленнее, чем ожидалось (около 5 минут). Честно говоря, здесь также нужно учитывать множество факторов: мой ноутбук довольно старый, я не потратил достаточно времени, чтобы покопаться в подробностях о внутренних устройствах, просто назову несколько, но это также было чрезвычайно Трудно найти информацию о рекомендациях по производительности от сообщества, и это, на мой взгляд, является важным препятствием, о котором следует помнить, когда вы рассматриваете вопрос о принятии нового стека. Сообщество является ключевым.
В целом, я осмелюсь сказать, что это была забавная поездка, я был рад видеть, что JVM все еще является прекрасным программным обеспечением с множеством возможностей, и что Clojure все еще может сохранить эту красоту в Concurrent Land, но я все еще склоняюсь к другие решения, а не использование core.async для высокопроизводительной системы, у меня не было того внутреннего ощущения, которое я испытывал при использовании Akka или Rx, по крайней мере, на данный момент.
Вы можете сделать это быстрее? Маякни мне! Не упустите этот шанс, вы можете стать шутником с Clojure СЕЙЧАС!

| Опубликовано на Java Code Geeks с разрешения Гильермо Селиги, партнера нашей программы JCG . Посмотрите оригинальную статью здесь: ПОЛУЧИТЕ ШВИФТИ С ЯДРОМ CLOJURE. ASYNC
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |