Самое замечательное в инструментах с открытым исходным кодом, таких как Eclipse и GNU (gcc, gdb), заключается в том, что существует множество превосходных инструментов: одну вещь, которую я задумал на некоторое время изучить, — это как создать покрытие кода моего встроенного приложения. Да, GNU и Eclipse поставляются с инструментами профилирования кода и покрытия кода, все бесплатно! Единственным недостатком является то, что эти инструменты редко используются для встроенных целей. Может быть, это знание не широко доступно? Итак, вот моя попытка изменить это :-).
Или: насколько круто видеть в Eclipse, сколько раз выполнялась строка в моих источниках?

Покрытие линии в Eclipse

И самое главное, это не останавливается на достигнутом…

Покрытие с Eclipse

Чтобы увидеть, сколько процентов моих файлов и функций покрыты?

GCOV в Eclipse
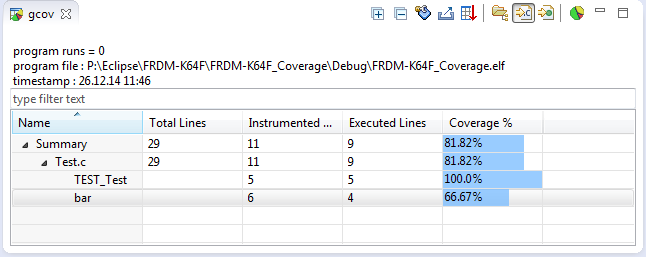
Или даже показать данные с помощью диаграмм?

Гистограмма покрытия

Контур
В этом уроке я использую плату Freescale FRDM-K64F : на ней установлена ARM Cortex-M4F, с 1 МБ FLASH и 256 КБ RAM. Подход, использованный в этом учебном пособии, можно использовать с любой встроенной целью, если имеется достаточно ОЗУ для хранения данных покрытия на цели. Я использую Eclipse Kepler с инструментами ARM Launchpad GNU (выпуск 3 квартала 2014 года), но с небольшими изменениями можно использовать любую версию Eclipse или набор инструментов GNU. Для генерации информации о покрытии кода я использую gcov .

Доска Freescale FRDM-K64F

Создание информации о покрытии кода с помощью gcov
gcov — это программа с открытым исходным кодом, которая может генерировать информацию о покрытии кода. Он говорит мне, как часто выполняется каждая строка программы. Это важно для тестирования, так как таким образом я могу знать, какие части моего приложения были фактически выполнены процедурами тестирования. Gcov можно использовать и для профилирования, но в этом посте я буду использовать его только для получения информации о покрытии.
Общий поток для генерации покрытия кода:
- Код инструмента : скомпилируйте файлы приложения с помощью специальной опции. Это добавит (скрытый) код и хуки, которые записывают, сколько раз выполняется фрагмент кода.
- Генерировать информацию о приборах : в рамках предыдущих шагов компилятор генерирует базовую информацию о блоках и строках. Эта информация хранится на хосте как *. gcno (Gnu Coverage Notes Object?) файлы.
- Запустите приложение : пока приложение выполняется на цели, инструментальный код будет записывать, сколько строк или блоков в приложении было выполнено. Эта информация хранится на цели (в оперативной памяти).
- Сброс записанной информации : при выходе из приложения (или в любое время) записанная информация должна быть сохранена и отправлена на хост. По умолчанию gcov хранит информацию в файлах. Поскольку файловая система может быть недоступна, для отправки и сохранения информации могут использоваться другие методы (последовательное соединение, USB, ftp,…). В этом уроке я покажу, как для этого можно использовать отладчик. Информация хранится в виде * .gcda (Gnu Coverage Data Analysis?) Файлов.
- Создайте отчеты и визуализируйте их с помощью gcov .
General gcov Flow
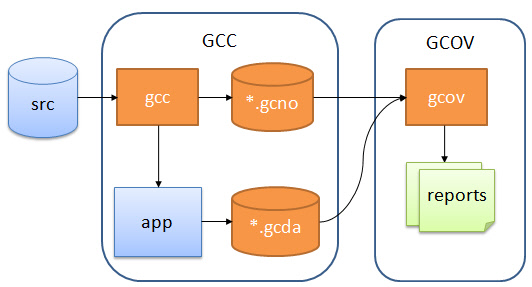
gcc выполняет инструментарий и предоставляет библиотеку для покрытия кода, а gcov — утилита для анализа сгенерированных данных.
Охват: параметры компилятора и компоновщика
Для создания файлов * .gcno необходимо добавить следующую опцию для каждого файла, который должен генерировать информацию о покрытии:
-fprofile-arcs -ftest-coverage
: idea: Существует также опция ‘-coverage’ (которая является ярлыком), которую можно использовать как для компилятора, так и для компоновщика. Но я предпочитаю «полные» варианты, чтобы знать, что стоит за этими вариантами.
Опция компилятора -fprofile-arcs
Опция -fprofile-arcs добавляет код в поток программы для подсчета выполнения строк исходного кода. Это происходит с инструментами дуги потока программы. С https://gcc.gnu.org/onlinedocs/gcc/Debugging-Options.html :
-fprofile-arcs Aдд код, так что инструментальные дуги потока инструментированы. Во время выполнения программа записывает, сколько раз выполнялась каждая ветвь и вызов и сколько раз он принимается или возвращается. Когда скомпилированная программа завершает работу, она сохраняет эти данные в файл с именем auxname.gcda для каждого исходного файла. Данные могут использоваться для оптимизации, ориентированной на профили (-fbranch-вероятности), или для анализа покрытия тестами (-ftest-покрытие). Auxname каждого объектного файла генерируется из имени выходного файла, если оно явно указано и не является конечным исполняемым файлом, в противном случае это базовое имя исходного файла. В обоих случаях удаляется любой суффикс (например, foo.gcda для входного файла dir / foo.c или dir / foo.gcda для выходного файла, указанного как -o dir / foo.o). См. Кросс-профилирование .
Если вы не знакомы с технологией компилятора или теорией графов: « Дуга » (альтернативно «ребро» или «ветвь») является направленной связью между парой « Базовые блоки ». Basic — это последовательность кода, в которой нет разветвлений (она выполняется в одной последовательности). Например, если у вас есть следующий код:
k = 0;
if (i==10) {
i += j;
j++;
} else {
foo();
}
bar();
Тогда это состоит из следующих четырех основных блоков:
Основные блоки

«Дуги» — это направленные ребра (стрелки) потока управления. Важно понимать, что инструментализируются не каждая строка источника, а только дуги: это означает, что накладные расходы на инструмент (размер кода и данные) зависят от того, насколько «сложен» поток программы, а не от того, сколько строк в исходном файле. есть.
Тем не менее, есть важный аспект, который необходимо знать о gcov: он обеспечивает « покрытие условий », если полное выражение оценивается как ИСТИНА или ЛОЖЬ. Рассмотрим следующий случай:
if (i==0 || j>=20) {
Другими словами: я получаю покрытие, сколько раз было выполнено «если», но * не * сколько раз «i == 0» или «j> = 20» (что будет « покрытием принятия решения », а это не предоставлено здесь). Смотрите http://www.bullseye.com/coverage.html для всех деталей.
Опция компилятора
Второй вариант для компилятора — -ftest-покрытие (из https://gcc.gnu.org/onlinedocs/gcc-3.4.5/gcc/Debugging-Options.html ):
-ftest-coverage PСоздайте файл заметок, который может использовать утилита покрытия кода gcov (см. gcov — Программа покрытия тестов ), чтобы показать охват программы. Каждый файл заметок исходного файла называется auxname.gcno. Обратитесь к опции -fprofile-arcs выше для описания auxname и инструкций о том, как генерировать тестовые данные покрытия. Данные покрытия будут более точно соответствовать исходным файлам, если вы не оптимизируете их.
Таким образом, эта опция генерирует файл * .gcno для каждого исходного файла, который я решил использовать:
сгенерированный файл gcno

Этот файл понадобится позже для визуализации данных с помощью gcov. Подробнее об этом позже.
Добавление параметров компилятора
Так что с этим знанием мне нужно добавить
-fprofile-arcs -ftest-coverage
как вариант компилятора для каждого файла, который я хочу профилировать. Не обязательно профилировать полное приложение: чтобы сохранить ПЗУ, ОЗУ и ресурсы, я могу добавить эту опцию только в нужные файлы. На самом деле, для начала я рекомендую использовать один исходный файл только в начале. Для этого я выбираю свойства (контекстное меню) моего файла Test.c и добавляю опции в «другие флаги компилятора»:

Покрытие добавлено в файл компиляции

Опция компоновщика -fprofile-arcs
Для профилирования нужна не только опция компилятора: мне нужно сообщить компоновщику, что ему нужно связать его с библиотекой профилировщика. Для этого я добавляю
-fprofile-arcs
к параметрам компоновщика:

Опция компоновщика -fprofile-arcs

Покрытие заглушки
В зависимости от настроек вашей библиотеки, теперь вы можете получить много неразрешенных ошибок компоновщика символов. Это связано с тем, что по умолчанию библиотека профилирования предполагает запись информации о профилировании в файловую систему. Однако большинство файловых систем * не * имеют файловую систему. Чтобы преодолеть это, я добавляю заглушки для всех необходимых функций. Я добавил их в свой проект (см. Последнюю версию этого файла на GitHub ):
/*
* coverage_stubs.c
*
* These stubs are needed to generate coverage from an embedded target.
*/
#include <stdio.h>
#include <stddef.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <errno.h>
#include "UTIL1.h"
#include "coverage_stubs.h"
/* prototype */
void gcov_exit(void);
/* call the coverage initializers if not done by startup code */
void static_init(void) {
void (**p)(void);
extern uint32_t __init_array_start, __init_array_end; /* linker defined symbols, array of function pointers */
uint32_t beg = (uint32_t)&__init_array_start;
uint32_t end = (uint32_t)&__init_array_end;
while(beg<end) {
p = (void(**)(void))beg; /* get function pointer */
(*p)(); /* call constructor */
beg += sizeof(p); /* next pointer */
}
}
void _exit(int status) {
(void) status;
gcov_exit();
for(;;){} /* does not return */
}
static const unsigned char *fileName; /* file name used for _open() */
int _write(int file, char *ptr, int len) {
static unsigned char gdb_cmd[128]; /* command line which can be used for gdb */
(void)file;
/* construct gdb command string */
UTIL1_strcpy(gdb_cmd, sizeof(gdb_cmd), (unsigned char*)"dump binary memory ");
UTIL1_strcat(gdb_cmd, sizeof(gdb_cmd), fileName);
UTIL1_strcat(gdb_cmd, sizeof(gdb_cmd), (unsigned char*)" 0x");
UTIL1_strcatNum32Hex(gdb_cmd, sizeof(gdb_cmd), (uint32_t)ptr);
UTIL1_strcat(gdb_cmd, sizeof(gdb_cmd), (unsigned char*)" 0x");
UTIL1_strcatNum32Hex(gdb_cmd, sizeof(gdb_cmd), (uint32_t)(ptr+len));
return len; /* on success, return number of bytes written */
}
int _open (const char *ptr, int mode) {
(void)mode;
fileName = (const unsigned char*)ptr; /* store file name for _write() */
return 0; /* success */
}
int _close(int file) {
(void) file;
return 0; /* success closing file */
}
int _fstat(int file, struct stat *st) {
(void)file;
(void)st;
st->st_mode = S_IFCHR;
return 0;
}
int _getpid(void) {
return 1;
}
int _isatty(int file) {
switch (file) {
case STDOUT_FILENO:
case STDERR_FILENO:
case STDIN_FILENO:
return 1;
default:
errno = EBADF;
return 0;
}
}
int _kill(int pid, int sig) {
(void)pid;
(void)sig;
errno = EINVAL;
return (-1);
}
int _lseek(int file, int ptr, int dir) {
(void)file;
(void)ptr;
(void)dir;
return 0; /* return offset in file */
}
#pragma GCC diagnostic push
#pragma GCC diagnostic ignored "-Wreturn-type"
__attribute__((naked)) static unsigned int get_stackpointer(void) {
__asm volatile (
"mrs r0, msp \r\n"
"bx lr \r\n"
);
}
#pragma GCC diagnostic pop
void *_sbrk(int incr) {
extern char __HeapLimit; /* Defined by the linker */
static char *heap_end = 0;
char *prev_heap_end;
char *stack;
if (heap_end==0) {
heap_end = &__HeapLimit;
}
prev_heap_end = heap_end;
stack = (char*)get_stackpointer();
if (heap_end+incr > stack) {
_write (STDERR_FILENO, "Heap and stack collision\n", 25);
errno = ENOMEM;
return (void *)-1;
}
heap_end += incr;
return (void *)prev_heap_end;
}
int _read(int file, char *ptr, int len) {
(void)file;
(void)ptr;
(void)len;
return 0; /* zero means end of file */
}
: idea: В этом коде я использую компонент UTIL1 (Utility) Processor Expert, доступный на SourceForge . Если вы не хотите / не нуждаетесь в этом, вы можете удалить строки с помощью UTIL1.
—
Файл заглушки покрытия в проекте

Конструкторы покрытия
Следует упомянуть одну важную вещь: структуры данных покрытия должны быть инициализированы, подобно конструкторам для C ++. В зависимости от вашего кода запуска, это может * не * быть сделано автоматически. Проверьте файл компоновщика .map на наличие символов _GLOBAL__ :
.text._GLOBAL__sub_I_65535_0_TEST_Test 0x0000395c 0x10 ./Sources/Test.o
Такой символ должен существовать для каждого исходного файла, который был снабжен информацией о покрытии. Это функции, которые необходимо вызывать как часть кода запуска. Установите точку останова в своем коде по указанному адресу, чтобы проверить, вызывается ли он. Если нет, вам нужно позвонить самому.
❗ Обычно я использую опцию компоновщика ‘-nostartfiles’), и у меня есть мой код запуска. В этом случае эти конструкторы не вызываются по умолчанию, поэтому я должен сделать это сам. См. Http://stackoverflow.com/questions/6343348/global-constructor-call-not-in-init-array-section
В моем файле компоновщика у меня есть это:
.init_array :
{
PROVIDE_HIDDEN (__init_array_start = .);
KEEP (*(SORT(.init_array.*)))
KEEP (*(.init_array*))
PROVIDE_HIDDEN (__init_array_end = .);
} > m_text
Это означает, что существует список указателей функций конструктора, соединенных между __init_array_start и __init_array_end. Так что все, что мне нужно, это перебрать этот массив и вызвать указатели на функции:
/* call the coverage initializers if not done by startup code */
void static_init(void) {
void (**p)(void);
extern uint32_t __init_array_start, __init_array_end; /* linker defined symbols, array of function pointers */
uint32_t beg = (uint32_t)&__init_array_start;
uint32_t end = (uint32_t)&__init_array_end;
while(beg<end) {
p = (void(**)(void))beg; /* get function pointer */
(*p)(); /* call constructor */
beg += sizeof(p); /* next pointer */
}
}
Поэтому мне нужно вызвать эту функцию как одну из первых вещей внутри main ().
Управление кучей
Другим аспектом библиотеки покрытия является использование кучи. Во время сброса данных он использует malloc () для выделения памяти кучи. Поскольку обычно мои приложения не используют malloc (), мне все равно нужно предоставить кучу для профилировщика. Поэтому я предоставляю пользовательскую реализацию sbrk () в моем cover_stubs.c :
void *_sbrk(int incr) {
extern char __HeapLimit; /* Defined by the linker */
static char *heap_end = 0;
char *prev_heap_end;
char *stack;
if (heap_end==0) {
heap_end = &__HeapLimit;
}
prev_heap_end = heap_end;
stack = (char*)get_stackpointer();
if (heap_end+incr > stack) {
_write (STDERR_FILENO, "Heap and stack collision\n", 25);
errno = ENOMEM;
return (void *)-1;
}
heap_end += incr;
return (void *)prev_heap_end;
}
❗ Возможно, потребуется несколько килобайт кучи. Поэтому, если вы работаете в системе с ограничением памяти, убедитесь, что у вас достаточно оперативной памяти.
Приведенная выше реализация предполагает, что у меня есть пространство между концом кучи и областью стека.
❗ Если ваш файл отображения / компоновки памяти отличается, конечно, вам нужно будет изменить реализацию _sbrk ().
Компиляция и сборка
Теперь приложение должно скомпилировать и связать без ошибок. Проверьте, что .gcno файлы генерируются:
: idea: Вам может понадобиться обновить папку в Eclipse.
—
сгенерированные файлы .gcno

На следующих шагах я покажу, как получить данные покрытия в виде * .gcda-файлов на хост, используя gdb.
Использование отладчика для получения данных покрытия
Данные покрытия сбрасываются при вызове приложения _exit () . В качестве альтернативы я мог бы вызвать gcov_exit () или __gcov_flush () в любое время. Что он тогда делает
- Откройте файл * .gcda с помощью _open () для каждого инструментированного исходного файла.
- Запишите данные в файл с помощью _write ().
Таким образом, я могу установить точку останова в отладчике как _open () и _write () и иметь все данные, которые мне нужны ?
С помощью _open () я получаю имя файла и сохраняю его в глобальном указателе, чтобы я мог ссылаться на него в _write ():
static const unsigned char *fileName; /* file name used for _open() */
int _open (const char *ptr, int mode) {
(void)mode;
fileName = (const unsigned char*)ptr; /* store file name for _write() */
return 0;
}
В _write () я получаю указатель на данные и длину данных. Здесь я могу вывести данные в файл с помощью команды gdb:
dump binary memory <file> <hexStartAddr> <hexEndAddr>
Я мог бы использовать калькулятор для вычисления диапазона дампа памяти, но это намного проще, если я позволю программе сгенерировать командную строку для gdb :-):
int _write(int file, char *ptr, int len) {
static unsigned char gdb_cmd[128]; /* command line which can be used for gdb */
(void)file;
/* construct gdb command string */
UTIL1_strcpy(gdb_cmd, sizeof(gdb_cmd), (unsigned char*)"dump binary memory ");
UTIL1_strcat(gdb_cmd, sizeof(gdb_cmd), fileName);
UTIL1_strcat(gdb_cmd, sizeof(gdb_cmd), (unsigned char*)" 0x");
UTIL1_strcatNum32Hex(gdb_cmd, sizeof(gdb_cmd), (uint32_t)ptr);
UTIL1_strcat(gdb_cmd, sizeof(gdb_cmd), (unsigned char*)" 0x");
UTIL1_strcatNum32Hex(gdb_cmd, sizeof(gdb_cmd), (uint32_t)(ptr+len));
return 0;
}
Таким образом, я могу скопировать строку в отладчике GDB:

Сгенерированная команда дампа памяти GDB

Эта команда вставляется и выполняется в консоли GDB:

командная строка GDB

После выполнения программы создается файл * .gcda (для его отображения может потребоваться обновление):
gcda файл создан
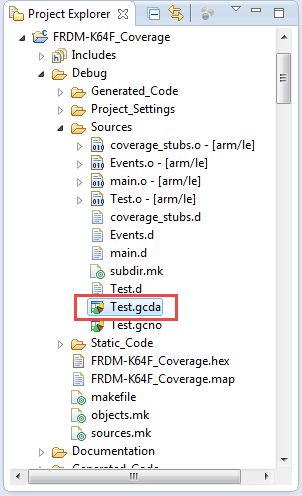
Повторите это для всех инструментированных файлов по мере необходимости.
Отображение информации о покрытии
Чтобы показать информацию о покрытии, мне нужны * .gcda, * .gcno плюс файл .elf.
: idea: Используйте Обновить, если не все файлы отображаются в представлении Project Explorer
Файлы, готовые для отображения информации о покрытии

Затем дважды щелкните файл gcda, чтобы отобразить результаты покрытия:

Двойной щелчок по файлу gcda
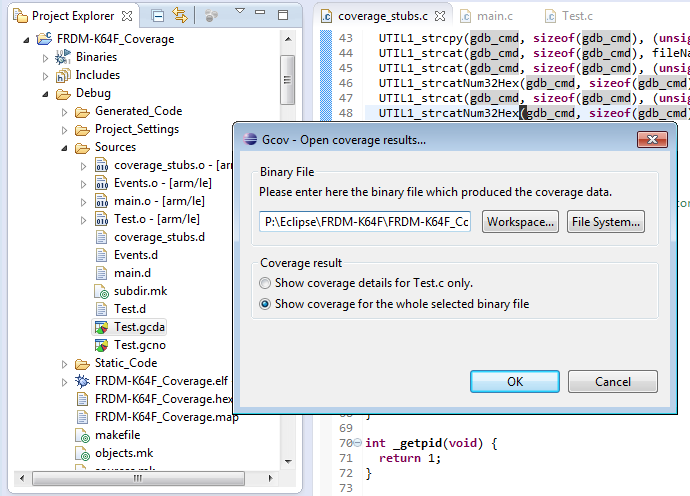
Нажмите OK, и он откроет представление gcov. Дважды щелкните файл в этом представлении, чтобы показать детали:

gcov Views

Используйте значок диаграммы, чтобы создать вид диаграммы:
Просмотр диаграммы


Гистограмма Вид

Видео шагов по созданию и использованию покрытия
Следующее видео суммирует необходимые шаги:
Данные и код накладных расходов
Использование кода для генерации информации о покрытии означает, что это навязчивый метод: он влияет на скорость выполнения приложения и требует дополнительной оперативной памяти и ПЗУ. Насколько сильно зависит от сложности потока управления и от числа дуг. Более высокая оптимизация компилятора уменьшила бы размер кода, однако оптимизация не рекомендуется для сеансов покрытия, так как это может значительно усложнить работу покрытия.
Я сделал быстрое сравнение, используя мое тестовое приложение. Я использовал команду GNU «size» (см. «Печать информации о размере кода в Eclipse» ).
Без включенного покрытия область приложения составляет:
arm-none-eabi-size --format=berkeley "FRDM-K64F_Coverage.elf" text data bss dec hex filename 6360 1112 5248 12720 31b0 FRDM-K64F_Coverage.elf
С включенным покрытием только для Test.c дал:
arm-none-eabi-size --format=berkeley "FRDM-K64F_Coverage.elf" text data bss dec hex filename 39564 2376 9640 51580 c97c FRDM-K64F_Coverage.elf
Добавление main.c для генерации покрытия дает:
arm-none-eabi-size --format=berkeley "FRDM-K64F_Coverage.elf" text data bss dec hex filename 39772 2468 9700 51940 cae4 FRDM-K64F_Coverage.elf
Так что, действительно, существует некоторая начальная надстройка из-за библиотеки покрытия, но после этого добавление большего количества исходных файлов не составляет большого количества.
Резюме
Мне потребовалось некоторое время и я прочитал много статей и статей, чтобы реализовать покрытие кода для встроенной цели. Ясно, что охват кода проще, если у меня есть файловая система и много доступных ресурсов. Но теперь я могу получать информацию о покрытии из довольно небольшой встроенной системы, используя отладчик для выгрузки данных на хост. Это не практично для больших наборов файлов, но, по крайней мере, для начала :-).
Я зафиксировал свой проект Eclipse Kepler / Launchpad, который использовал в этом руководстве на GitHub .
Идеи, которые я имею в виду:
- Вместо этого используйте отладчик / GDB, используйте FatFS и SD-карту для хранения данных
- Изучаем, как использовать профилирование
- Объединение нескольких прогонов покрытия
Счастливого Покрытия ?
Ссылки:
- Статья в блоге, которая помогла мне изучить gcov для встроенных целей: http://simply-embedded.blogspot.ch/2013/08/code-coverage-introduction.html
- Документ об использовании gcov для встраиваемых систем: http://sysrun.haifa.il.ibm.com/hrl/greps2007/papers/gcov-on-an-embedded-system.pdf
- Статья о вариантах покрытия для компилятора и компоновщика GNU: http://bobah.net/d4d/tools/code-coverage-with-gcov
- Как вызывать статические методы конструктора вручную: http://stackoverflow.com/questions/6343348/global-constructor-call-not-in-init-array-section
- Статья об использовании gcov с lcov: https://qiaomuf.wordpress.com/2011/05/26/use-gcov-and-lcov-to-know-your-test-coverage/
- Объяснение различных методов покрытия и терминологии: http://www.bullseye.com/coverage.html