Обе. Я начал работать над этим небольшим проектом пару месяцев назад, используя Hudson v1.395, и вернулся к нему после того, как произошел большой разрыв. Я использовал это как возможность посмотреть, будут ли существенные проблемы, если я решу в будущем переехать в Дженкинс навсегда. Было несколько икот, особенно в том, что новая банка CLI не работала сразу после установки, но в целом версия 1.401 Jenkins работала, как и ожидалось, после переключения. Хорошей новостью является то, что старая версия CLI jar все еще работает, так что в этом примере фактически используется сочетание кода для достижения цели. Во всяком случае, программное обеспечение великолепно, и его более чем достаточно.
API
Jenkins / Hudson имеет удобный удаленный API, содержащий информацию о ваших сборках, и поддерживает богатый набор функций для управления ими и сервером в целом удаленно. Можно запускать сборки, копировать задания, останавливать сервер и даже устанавливать плагины удаленно. У вас есть выбор XML, JSON или Python при взаимодействии с API сервера. И, как сказано в документации по сборке, вы можете найти нужные вам функции по относительному пути из URL сервера сборки по адресу:
«/… / Api / где часть«… »- это объект, к которому вы хотите получить доступ».
Это покажет краткую страницу документации, если вы перейдете к ней в браузере, и вернет результат, если вы добавите нужный формат в качестве последней части пути. Например, чтобы загрузить информацию о компьютере, на котором работает локальный сервер Jenkins, запрос get по этому URL-адресу вернет результат в формате JSON: http: // localhost: 8080 / computer / api / json.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
{ 'busyExecutors': 0, 'displayName': 'nodes', 'computer': [ { 'idle': true, 'executors': [ { }, { } ], 'actions': [ ], 'temporarilyOffline': false, 'loadStatistics': { }, 'displayName': 'master', 'oneOffExecutors': [ ], 'manualLaunchAllowed': true, 'offline': false, 'launchSupported': true, 'icon': 'computer.png', 'monitorData': { 'hudson.node_monitors.ResponseTimeMonitor': { 'average': 111 }, 'hudson.node_monitors.ClockMonitor': { 'diff': 0 }, 'hudson.node_monitors.TemporarySpaceMonitor': { 'size': 58392846336 }, 'hudson.node_monitors.SwapSpaceMonitor': null, 'hudson.node_monitors.DiskSpaceMonitor': { 'size': 58392846336 }, 'hudson.node_monitors.ArchitectureMonitor': 'Mac OS X (x86_64)' }, 'offlineCause': null, 'numExecutors': 2, 'jnlpAgent': false } ], 'totalExecutors': 2} |
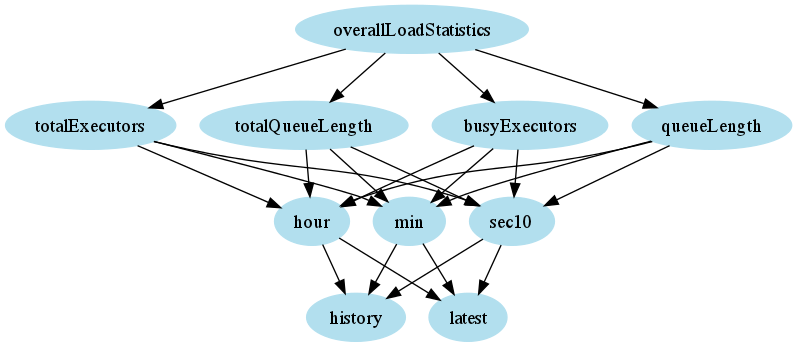
Вот то же дерево, отображаемое с использованием GraphViz.

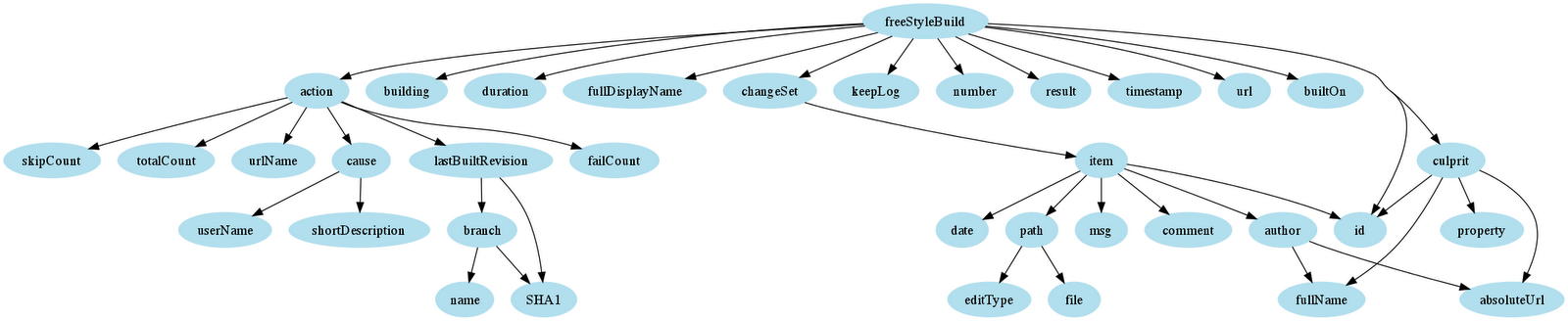
Эта функциональность распространяется на дерево от корня сервера, и вы можете указать, сколько дерева вы загружаете из какой-либо конкретной ветви, указав параметр «глубина» в своих URL-адресах. Будьте осторожны, насколько высоко вы указываете эту переменную. Тестирование с глубиной загрузки четыре на многолюдном, долго работающем сервере сборки (десятки сборок с тысячами выполнений заданий) мне удавалось регулярно прерывать. Чтобы дать вам представление, вот очень грубая визуализация домена на глубине три от корня API.

Вывод данных с сервера очень прост, но возможность удаленного запуска активности на сервере более интересна. Чтобы запустить сборку задания с именем «test», POST на http: // localhost: 8080 / job / test / build выполняет эту работу. Используя доступные средства, довольно легко сделать такие вещи, как:
- загрузите файл конфигурации задания, измените его и создайте новое задание, поместив новый файл config.xml
- перенести работу с одной машины на другую
- создать обзор запланированных сборок
CLI Jar
Есть другой способ удаленного управления серверами сборки в CLI-банке, распространяемом вместе с сервером. Этот jar предоставляет простые средства для удаленного выполнения определенных команд на сервере сборки. Следует отметить, что это позволяет устанавливать плагины удаленно и выполнять удаленную оболочку Groovy. Я включил эту функциональность с очень тонкой оберткой вокруг основного класса, предоставляемого банкой CLI, как показано в следующем примере кода.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
/** * Drive the CLI with multiple arguments to execute. * Optionally accepts streams for input, output and err, all of which * are set by default to System unless otherwise specified. * @param rootUrl * @param args * @param input * @param output * @param err * @return */def runCliCommand(String rootUrl, List<String> args, InputStream input = System.in, OutputStream output = System.out, OutputStream err = System.err){ def CLI cli = new CLI(rootUrl.toURI().toURL()) cli.execute(args, input, output, err) cli.close()} |
А вот простой тест, показывающий, как можно выполнить скрипт Groovy для загрузки информации о заданиях, аналогично тому, что вы можете сделать из встроенной консоли сценариев Groovy на сервере, которую можно найти для локально установленного развертывания по адресу http: / / локальный: 8080 / сценарий.
|
01
02
03
04
05
06
07
08
09
10
11
|
def 'should be able to query hudson object through a groovy script'(){ final ByteArrayOutputStream output = new ByteArrayOutputStream() when: api.runCliCommand(rootUrl, ['groovysh', 'for(item in hudson.model.Hudson.instance.items) { println('job $item.name')}'], System.in, output, System.err) then: println output.toString() output.toString().split('\n')[0].startsWith('job')} |
Вот несколько ссылок на статьи о CLI, если вы хотите узнать больше:
- Hudson CLI Wikidoc
- Дженкинс CLI Викидок
- Шаблон для заданий PHP на Jenkins
- Статья от Кохсуке Кавагути
- Хороший учебник
HTTPBuilder
HTTPBuilder — мой инструмент выбора при программировании с использованием HTTP API. Использование очень простое, и мне удалось обойтись только с двумя методами поддержки всего API: один для GET и один для POST. Вот метод GET, достаточный для выполнения запроса, анализа ответа JSON и завершения (хотя и наивного) обработки ошибок.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
/** * Load info from a particular rootUrl+path, optionally specifying a 'depth' query * parameter(default depth = 0) * * @param rootUrl the base url to access * @param path the api path to append to the rootUrl * @param depth the depth query parameter to send to the api, defaults to 0 * @return parsed json(as a map) or xml(as GPathResult) */def get(String rootUrl, String path, int depth = 0){ def status HTTPBuilder http = new HTTPBuilder(rootUrl) http.handler.failure = { resp -> println 'Unexpected failure on $rootUrl$path: ${resp.statusLine} ${resp.status}' status = resp.status } def info http.get(path: path, query: [depth: depth]) { resp, json -> info = json status = resp.status } info ?: status} |
Вызов этого для извлечения данных является однострочным, поскольку единственное реальное отличие — это переменная path, используемая при вызове API.
|
01
02
03
04
05
06
07
08
09
10
11
|
private final GetRequestSupport requestSupport = new GetRequestSupport() .../** * Display the job api for a particular Hudson job. * @param rootUrl the url for a particular build * @return job info in json format */def inspectJob(String rootUrl, int depth = 0){ requestSupport.get(rootUrl, API_JSON, depth)} |
Технически, здесь нет ничего, что ограничивало бы это только JSON. Одна из замечательных особенностей HTTPBuilder заключается в том, что он с радостью попытается сделать правильный ответ с ответом. Если возвращенные данные в формате JSON, как в этих примерах, они анализируются в JSONObject. С другой стороны, если данные представляют собой XML, они анализируются в Groovy GPathResult. Оба из них очень легко ориентироваться, хотя синтаксис навигации по их графам объектов различен.
Что ты можешь сделать с этим?
Моей основной мотивацией для изучения API Hudson / Jenkins было посмотреть, как я могу упростить управление несколькими серверами. В настоящее время я ежедневно работаю с четырьмя сборочными серверами и еще несколькими подчиненными машинами и поддерживаю различные ветви версий. Это включает в себя наборы модульных и функциональных тестовых наборов, а также задание непрерывного развертывания, которое регулярно вносит изменения в тестовые машины, соответствующие матрице поддерживаемой платформы, поэтому, к сожалению, не все так просто, как копирование одного задания при ветвлении. Создание инфраструктуры сборки для новых ветвей функций в автоматическом или, по крайней мере, полуавтоматическом режиме, действительно привлекательно, особенно в связи с тем, что планируется расширить автоматизацию сборки. Для недавнего 555-дневного проекта я использовал уровень API для создания приложения Grails, функционирующего как кросс-серверный радиатор сборки и центральное средство для управления сервером. Это доказательство концепции способно подключаться к нескольким серверам сборки и визуализировать данные о заданиях, а также конкретную конфигурацию системы, запускать сборки и прямую связь с каждым из подключенных серверов, что позволяет продолжить детализацию. Вот пара макетов, которые в значительной степени показывают картину.

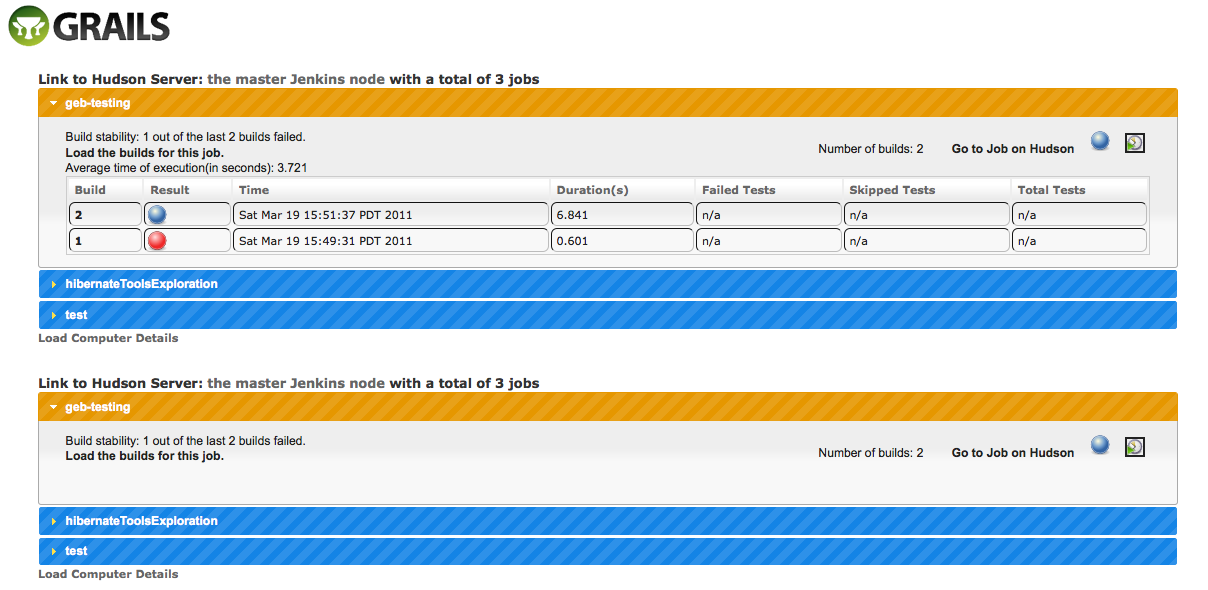
Просто классное приложение для установки Jenkins
Это только косвенно связано, но я наткнулся на это очень хорошее и простое приложение Griffon, которое называется Jenkins-Assembler, которое упрощает подготовку вашего сервера сборки. Он представляет вам список плагинов, позволяя выбирать, а затем загружает и объединяет их в одну развертываемую войну.

Хватит говорить — где код ???
Исходный код, связанный с этой статьей, доступен на github . Тесты представляют собой скорее исследование живого API, чем реальный тест кода в этом проекте. Они работают на локальном сервере, запущенном с помощью плагина Gradle Jetty. Наконец, вот несколько красивых картинок для вас.
[Показать как слайд-шоу]
[Просмотр с PicLens]

.png)
.png)
.png)
.png)
.png)
Продолжите к части 2 .
Ссылка: Внедрение API Jenkins (Hudson) от нашего партнера по JCG Келли Робинсон в блоге The Kaptain на… материале .