Моя недавняя публикация под названием «NoSQL Advice, которую я хотел бы, чтобы кто-то дал мне», вызвала хорошую дискуссию в Интернете на DZone. Один конкретный вопрос, касающийся моего мнения о GemFire как базе данных NoSQL, заставил меня написать длинный ответ. Прочитав ответ, я понял, что это будет лучше, чем пост, и вот мы здесь.
Теперь, чтобы быть ясным, я не использовал сам GemFire, но этот вопрос заставил меня задуматься о решениях для сетки данных, что я хорошо знаю, основываясь на многолетнем опыте работы с Infinispan . В этой статье я постараюсь обобщить информацию о кешах и сетках данных с точки зрения NoSQL и дать, как я надеюсь, полезный совет для архитекторов, рассматривающих возможность перехода к одному из них.
Что такое кеш?
Давайте начнем с основ. Кеш, в терминах современного корпоративного программного обеспечения, можно рассматривать как карту. Вы можете поместить значения в него, указав ключ, а затем снова получить значения из него, указав ключ. Не может быть проще.
То, что делает кеш кешем, а не просто картой, — это в первую очередь то, как он используется. Общая идея заключается в том, что вы используете кэш для уменьшения нагрузки на некоторое внутреннее хранилище данных, обычно на реляционную базу данных, сохраняя в нем данные, на которые часто ссылаются, и не беспокоя сервер базы данных каждый раз, когда вам нужен такой фрагмент данных. Обычно псевдокод выглядит примерно так:
Object readSomething(Object key) {
Object value = cache.get(key)
if (value == null) {
Object value = database.readUsingKey(key)
cache.put(key, value)
}
return value
}
Или, возможно, вы используете ORM, такой как JPA , который сам использует кэш для ускорения операций. Но это действительно просто скрывает ту же самую общую логику внутри ORM. Очевидная цель — читать базу данных только тогда, когда вы еще не знаете значение. Для этой цели такая логика прекрасно работает.
Проблема, конечно, в том, что происходит при изменении данных? Затем вы получите что-то вроде этого, которое обновляет кэш с изменениями данных:
void writeSomething(Object key, Object value) {
database.writeUsingKey(key, value)
cache.remove(key, value)
}
Или в качестве альтернативы:
void writeSomething(Object key, Object value) {
database.writeUsingKey(key, value)
cache.put(key, value)
}
Но есть еще проблема. Что делать, если у вас есть несколько серверов приложений? У каждого из них есть свой кеш в памяти. Если часть данных написана на одном, как другие узнают об этом? Как правило, один из этих методов используется:
- Кэширование на основе времени — каждый узел запоминает данную запись только в течение фиксированного периода времени. После истечения срока действия записи база данных снова проверяется на наличие последних данных.
- Кластеризация в памяти — сделайте кэш кластеризованным по всей сети, чтобы изменения на одном узле передавались другим узлам.
- Сетевое кеширование — удалите кеш из памяти сервера приложений, вместо этого разместив его на кластере общих сетевых серверов.
- Гибрид — некоторая комбинация вышеперечисленного.
Кэширование на основе времени является самым простым, поскольку кешу не нужно знать или заботиться о каких-либо других узлах. И это может быть чрезвычайно эффективным для данных, которые редко изменяются, или для данных, которые не обязательно должны быть очень согласованными по вашим узлам. Но что вы делаете, когда данные постоянно меняются, и узлы действительно должны оставаться как можно более актуальными?
В итоге вы получаете модели кэширования в памяти или сети, которые представляют собой просто набор кэшей, размещенных на множестве узлов в кластере:
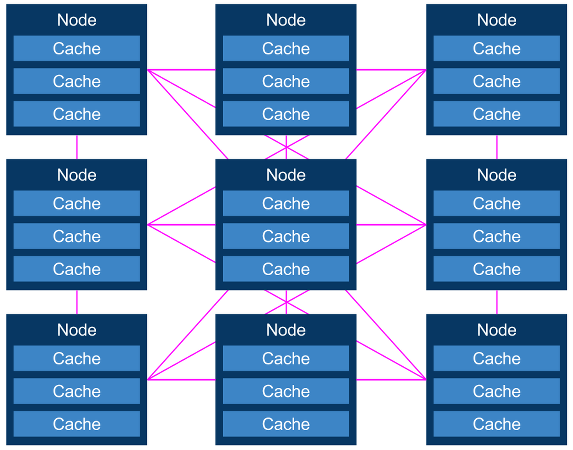
Теперь мы больше не говорим о простых кешах, а о распределенных кешах. Это могут быть кэши в памяти, внешние кэши или их комбинация. Ключевой вопрос сейчас заключается в том, как изменения обновляются во всех кэшах, что в действительности определяет следующую сетку cData типов данных grids.ache:
- Кэши аннулирования — данная запись может существовать на нескольких узлах, если она не меняется. Когда один узел изменяет запись в кэше, все узлы уведомляются о том, что их копии недействительны (и поэтому они должны выбросить свою копию этой записи).
- Кэши репликации — все узлы имеют все записи. Когда один узел изменяет запись, изменение реплицируется на все остальные узлы, чтобы они могли обновить свою копию свежими данными.
- Кэши распределения — записи распределяются по подмножеству узлов с использованием некоторой согласованной схемы хеширования. Когда один узел изменяет запись, изменение реплицируется только на другие узлы, которые заботятся об этой записи.
- Гибридные кэши — некоторая комбинация предыдущих трех.
Кэши аннулирования, как правило, наиболее эффективны для снижения нагрузки на сервер базы данных, поскольку по сети необходимо отправлять только сообщения о недействительности, и они обычно намного меньше, чем полные записи в кеше. Но последние два, кеш репликации и распределения, интересны в сочетании с понятием сохранения кеша. Что делать, если кеш способен сохранять свое содержимое в той или иной форме, чтобы при его отскоке он не начинался холодным и пустым? Это хороший способ выполнить то, что называется потеплением в кеше , что решает проблему загроможденного стада, которая часто возникает при первом запуске системы, использующей кеш.
Когда у вас есть распределенный кеш, способный запоминать его содержимое, возникает очевидный вопрос: зачем вам вообще нужна база данных за кешем? Что приводит нас к …
Сетки данных
Сетка данных — это просто распределенная система кэширования, которая также действует как сама база данных. Вы получаете и помещаете данные в кеш по ключам, а сетка данных заботится о ее распространении или репликации. Каждый кэш хранит копию своих записей на локальном диске, чтобы он мог перечитать содержимое при запуске. Вы получите что-то похожее на это:
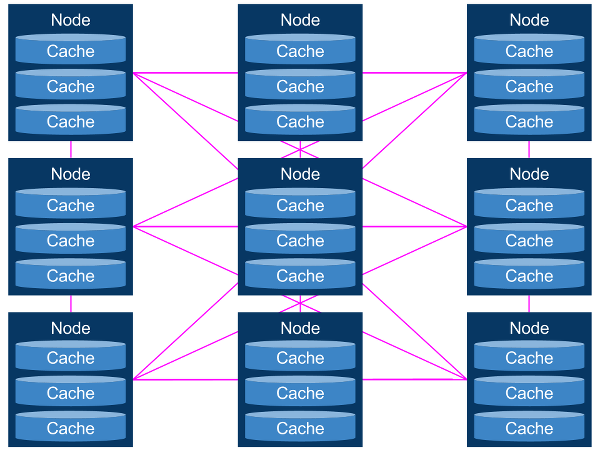
Это простая концепция, и она может быть чрезвычайно эффективной при управлении большими объемами данных в масштабе. Но некоторые проблемы с масштабируемостью остаются.
Во-первых, сетки данных требуют прогрева всех кешей при запуске, поскольку кеш нельзя отличить от базы данных. Но потепление кэша обманчиво сложно реализовать хорошо, так как кэш должен связываться с другими узлами при запуске, чтобы гарантировать, что его содержимое все еще свежо, что часто включает в себя большую передачу данных между узлами. Вы не хотите, чтобы кэш подключался к сети до тех пор, пока он не завершится, что приводит к длительной задержке запуска. Существует также неизбежное состояние гонки, поскольку запускаемый узел пытается подогреть кеш, который сам постоянно изменяется на других узлах кластера. Подумайте об этой проблеме на минуту, и вы поймете, почему ее действительно трудно решить.
Кэши репликации обеспечивают лучшую производительность чтения, поскольку каждый узел в кластере имеет каждую запись. Данные буквально ждут вас в памяти, чтобы вы могли их использовать; что может быть быстрее? Однако производительность записи страдает, поскольку каждое изменение должно быть передано каждому узлу. Кэши репликации также имеют проблему масштабируемости n в квадрате: количество сетевых подключений между узлами является квадратом числа узлов. Это сильно ограничивает размер вашего кластера.
Кэши распределения частично смягчают проблему n-квадрата, поскольку только согласованное подмножество кластера содержит какую-либо конкретную запись. Вам по-прежнему необходимо n-квадратное число сетевых соединений между узлами, но по крайней мере данное изменение необходимо передать только постоянному количеству узлов. Но как реагирует сетка данных, когда узлы добавляются или удаляются из кластера? Нужно ли перебалансировать весь кластер? Это может вызвать серьезные проблемы с производительностью, поскольку огромные объемы данных должны передаваться с узла на узел.
Кроме того, проблема двухточечного соединения n-квадратов по-прежнему ограничивает количество узлов в кластере, поэтому современные сетки данных обычно предлагают некоторые способы использования многоадресной связи . Multicast действительно бомба! Это удивительно экономно с пропускной способностью сети, и может быстро передавать огромные объемы данных. Но это только локальные сетевые технологии. Маршрутизаторы не любят многоадресную рассылку, поскольку они не знают, кто хочет получать пакеты, поэтому большинство маршрутизаторов не пропускают многоадресный трафик. Другими словами: забудьте многоадресную рассылку, если вы хотите масштабировать за пределы одного центра обработки данных, или если вы хотите разместить кластер в облаке, или даже если вы хотите иметь более одной сети в своем частном центре обработки данных. Примечательно, что Amazon AWSне поддерживает многоадресную рассылку в их облаке; Я был бы удивлен, если бы другие поставщики облачных услуг не имели такого же ограничения.
Кэши распределения также не работают так же хорошо при чтениях. Чтение из кэша наиболее эффективно, когда запись, которую вы пытаетесь прочитать, уже находится в памяти. Вот почему кэширование репликации так быстро при чтении. Но кеши распределения не гарантируют вам этого. Фактически, чем больше ваш кластер, тем меньше вероятность того, что нужная вам запись уже доступна в локальной памяти, и поэтому для поиска любого фрагмента данных должен произойти скачок в сети. Это приводит к тому, что люди стремятся поставить кеш перед их кешем, что начинает становиться смешным.
По моему опыту, наиболее реалистичной моделью для сеток данных является подход к распределенному кешу, использующий многоадресную сетевую связь, со сложной последовательной схемой хеширования, которая минимизирует перебалансировку кластера при изменении топологии, и со сложной схемой потепления кэша, которая минимизирует сетевую связь при запуске и обрабатывает неизбежную гонку между потеплением кэша и изменениями кэша, которые происходят во всем кластере.
Но поскольку используется многоадресная передача, это ограничивает вашу сетку данных только одним центром обработки данных. Для многих случаев использования этого достаточно. Но если вам нужно масштабироваться за пределы единого центра обработки данных, вам придется подумать о продвинутой топологии сетки данных, своего рода многоуровневой «сетке данных сеток данных». Чтобы это работало, программное обеспечение вашей сетки данных должно поддерживать асинхронную связь между отдельными сетками данных, что-то вроде следующего:
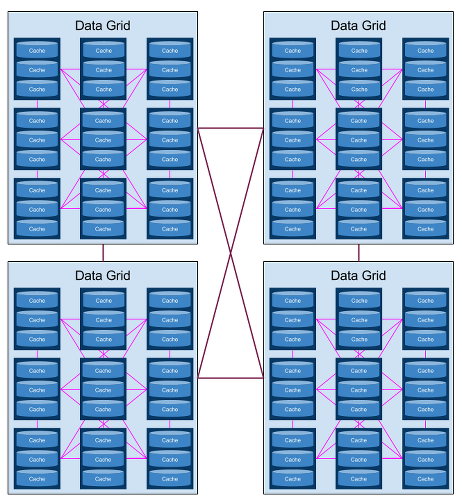
Обратите внимание на сложность. Каждый кеш должен иметь возможность реплицироваться или распределяться по всем уровням сетки данных-сетки данных. И чтобы это имело практическую ценность, эти репликации в сетках данных должны иметь возможность происходить в глобальных сетях, поэтому они должны быть асинхронными. Наш старый друг, теорема CAP, поднимает свою уродливую голову, заставляя нас сделать выбор между последовательностью и доступностью, что действительно заставляет нас немедленно отказаться от последовательности в пользу доступности (AP). Хотя эта модель обладает преимуществом гибкости — все аспекты многоуровневой сетки данных видны и настраиваются архитектором — это также приводит к гораздо большей головной боли при обслуживании.
Индексирование и поиск
Теперь давайте рассмотрим взгляд разработчика на данные. Любая постоянная система, достойная своей соли, допускает возможность вторичных показателей. В конце концов, нам часто нужно искать данные не по первичному ключу. Модель кеша мира — просто прославленная карта — не очень хорошо подходит для вторичных ключей в записях кеша, если в верхней части интерфейса кеша не добавлен дополнительный слой, чтобы дать разработчику более высокий уровень представления данных.
Но это приводит к другому уровню сложности, когда каждый кеш на самом деле представляет собой виртуальную конструкцию, состоящую из нескольких физических кешей — одного первичного и нулевого или более вторичного:
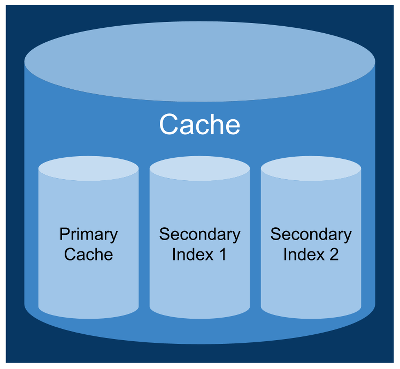
Соедините это с моделью многоуровневой сетки данных, и у вас получится настоящая чаша спагетти. Это иерархическое, так что это не невозможно визуализировать, но и не тривиально. Кроме того, чем больше становится модель данных, тем больше разработчиков хотят помочь языку запросов. Добавьте еще один слой поверх API кеша, чтобы переводить запросы в вызовы кеша и наоборот.
На данный момент, учитывая, что мы начинаем приближаться к функциональности полной базы данных NoSQL, я рекомендую вам начать смотреть на пакеты программного обеспечения, которые будут автоматически обрабатывать все эти проблемы. Например, такие продукты, как Cassandra или Couchbase Инкапсулируйте всю эту сложность за хорошим знакомым языком запросов к базе данных и драйвером. Вы получаете примерно один и тот же уровень возможностей, просто другую модель для работы архитектора, разработчика и администратора с системой. Сетка данных демонстрирует больше своих внутренностей, что может обеспечить большую гибкость, но это также означает, что на более низком уровне часто приходится думать о том, как все сетки данных соединяются вместе. Я полагаю, что это вопрос предпочтений, но я предпочитаю постоянную систему, которая выглядит и пахнет как база данных, а не как кеш. Другие могут не согласиться. Каждому свое.
Вывод
Весь этот пост начался с вопроса о том, что я думаю о GemFire, популярном решении для сетки данных. Опять же, я не использовал GemFire специально, поэтому я не могу комментировать, насколько хорошо он работает в качестве сетки данных. Но я думаю, что эта статья предоставляет довольно простую универсальную структуру для рассмотрения сеток данных, и не должно быть слишком сложно применять эту среду при рассмотрении GemFire или любого другого решения для кэширования, которое выступает в качестве сетки данных.
Я надеюсь, что вы найдете это полезным, если вы собираетесь идти по маршруту сетки данных.