Как работает инфраструктура Fork / Join в разных конфигурациях?
Так же, как и в предстоящем эпизоде «Звездных войн», было много волнений, смешанных с критикой вокруг параллелизма Java 8. Синтаксический сахар параллельных потоков принес некоторую шумиху, почти как новый световой меч, который мы видели в трейлере. Теперь, когда у нас есть много способов сделать параллелизм в Java, мы хотели понять преимущества производительности и опасности параллельной обработки. После более чем 260 тестовых запусков на основе данных появилось несколько новых идей, и мы хотели поделиться ими с вами в этом посте.
{kind=link}

Вилка / Регистрация: Пробуждение Вилки
ExecutorService против Fork / Join Framework против параллельных потоков
Давным-давно, в галактике далеко-далеко … Я имею в виду, что около 10 лет назад параллелизм был доступен в Java только через сторонние библиотеки. Затем появилась Java 5 и была представлена библиотека java.util.concurrent как часть языка, на которую сильно повлиял Дуг Ли . Служба ExecutorService стала доступной и предоставила нам простой способ обработки пулов потоков. Конечно, java.util.concurrent продолжает развиваться, и в Java 7 была представлена инфраструктура Fork / Join, основанная на пулах потоков ExecutorService. С потоками Java 8 нам был предоставлен простой способ использования Fork / Join, который остается загадочным для многих разработчиков. Давайте узнаем, как они сравниваются друг с другом.
Мы взяли 2 задачи, одна с интенсивным использованием ЦП и другая с интенсивным вводом-выводом, и протестировали 4 различных сценария с одинаковыми основными функциями. Другим важным фактором является количество потоков, которые мы используем для каждой реализации, поэтому мы также проверили это. На машине, которую мы использовали, было доступно 8 ядер, поэтому у нас были варианты 4, 8, 16 и 32 потоков, чтобы понять общее направление, в котором движутся результаты. Для каждой из задач мы также опробовали однопоточное решение, которое вы не увидите на графиках, так как его выполнение заняло гораздо больше времени. Чтобы узнать больше о том, как именно проходили тесты, вы можете ознакомиться с разделом основы ниже. Теперь перейдем к этому.
Индексирование файла объемом 6 ГБ с 5,8 млн строк текста
В этом тесте мы сгенерировали огромный текстовый файл и создали аналогичные реализации для процедуры индексации. Вот как выглядели результаты:
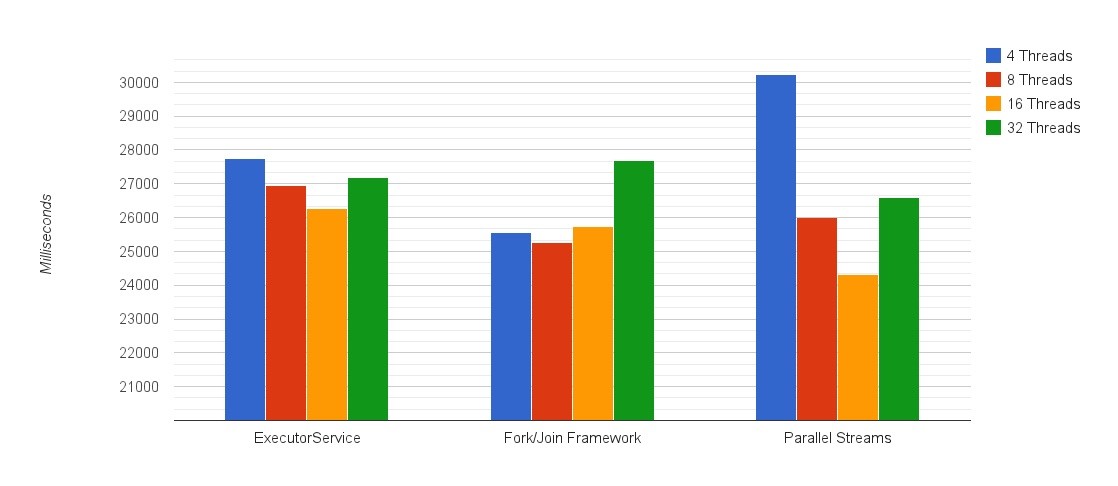
Результаты тестирования индексации файлов
** Однопоточное выполнение: 176,267 мсек или почти 3 минуты.
** Обратите внимание, что график начинается с 20000 миллисекунд.
1. Меньшее количество потоков оставит процессоры неиспользуемыми, слишком много добавит накладных расходов.
Первое, что вы заметите на графике, это форма, которую начинают принимать результаты — вы можете получить представление о том, как ведет себя каждая реализация, только из этих 4 точек данных. Здесь переломный момент составляет от 8 до 16 потоков, поскольку некоторые потоки блокируют ввод-вывод файла и добавление большего количества потоков, чем ядер, помогло их лучше использовать. Когда запущено 32 потока, производительность ухудшается из-за дополнительных издержек.
2. Параллельные потоки — лучшие! Почти на 1 секунду лучше чем занявший второе место: используя Fork / Join напрямую
Помимо синтаксического сахара (лямбды! Мы не упоминали лямбды), мы видели, как параллельные потоки работают лучше, чем реализации Fork / Join и ExecutorService. 6 ГБ текста проиндексировано за 24,33 секунды. Вы можете доверять Java здесь для достижения наилучшего результата.
3. Но … Параллельные потоки также показали худшие результаты: единственное изменение продолжительностью более 30 секунд.
Это еще одно напоминание о том, как параллельные потоки могут замедлить вас. Допустим, это происходит на машинах, на которых уже запущены многопоточные приложения. При меньшем количестве доступных потоков использование Fork / Join напрямую может быть лучше, чем проходить через параллельные потоки — разница в 5 секунд, что дает примерно 18% штраф при сравнении этих двух вместе.
4. Не используйте размер пула по умолчанию с IO на картинке
При использовании размера пула по умолчанию для параллельных потоков одинаковое количество ядер на машине (здесь 8) работало почти на 2 секунды хуже, чем версия с 16 потоками. Это штраф в 7% за использование пула по умолчанию. Причина, по которой это происходит, связана с блокировкой потоков ввода-вывода. Продолжается ожидание, поэтому добавление большего количества потоков позволяет нам получить больше от задействованных ядер ЦП, в то время как другие потоки ожидают, чтобы быть запланированными, а не простаивать.
Как изменить размер пула Fork / Join по умолчанию для параллельных потоков? Вы можете изменить общий размер пула Fork / Join с помощью аргумента JVM:
|
1
|
-Djava.util.concurrent.ForkJoinPool.common.parallelism=16 |
(Все задачи Fork / Join по умолчанию используют общий статический пул, размер которого равен числу ваших ядер. Преимущество здесь заключается в сокращении использования ресурсов за счет восстановления потоков для других задач в периоды, когда они не используются.)
Или … Вы можете использовать этот трюк и запускать параллельные потоки в пользовательском пуле Fork / Join. Это отменяет использование по умолчанию общего пула Fork / Join и позволяет вам использовать пул, который вы создали самостоятельно. Довольно подлый. В тестах мы использовали общий пул.
5. Однопоточная производительность была в 7,25 раза хуже, чем лучший результат
Параллелизм обеспечил 7,25-кратное улучшение, и, учитывая, что у машины было 8 ядер, он приблизился к теоретическому 8-кратному предсказанию! Мы можем отнести остальное к накладным расходам. При этом даже самая медленная реализация параллелизма, которую мы тестировали, на этот раз это были параллельные потоки с 4 потоками (30,24 с), работала в 5,8 раза лучше, чем однопоточное решение (176,27 с).
Что происходит, когда вы берете IO из уравнения? Проверка, является ли число простым
Для следующего цикла тестов мы полностью исключили IO и проверили, сколько времени потребуется, чтобы определить, является ли какое-то действительно большое число простым или нет. Насколько велик? 19 цифр . 1,530,692,068,127,007,263, или другими словами: один квинтиллион семьдесят девять квадриллионов триста шестьдесят четыре триллиона тридцать восемь миллиардов сорок восемь миллионов триста пять тысяч тридцать три. Ага, дай мне подышать воздухом. Во всяком случае, мы не использовали никакой оптимизации, кроме бега к квадратному корню, поэтому мы проверили все четные числа, даже если наше большое число не делится на 2, просто чтобы сделать его более длинным. Оповещение о спойлере: это простое число, поэтому каждая реализация выполняла одинаковое количество вычислений.
{kind=link}
Вот как это оказалось:
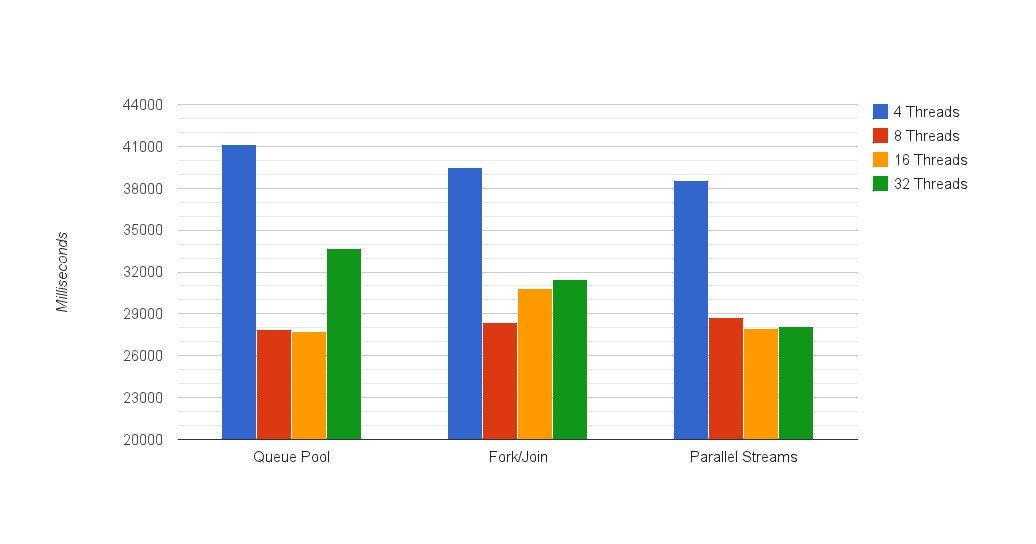
Результаты теста простых чисел
** Однопоточное выполнение: 118 127 мсек или почти 2 минуты.
** Обратите внимание, что график начинается с 20000 миллисекунд
1. Меньшие различия между 8 и 16 нитями
В отличие от теста IO, здесь нет вызовов IO, поэтому производительность 8 и 16 потоков была в основном одинаковой, за исключением решения Fork / Join. На самом деле мы провели еще несколько тестов, чтобы убедиться, что мы получаем хорошие результаты из-за этой «аномалии», но время от времени получалось очень схожим. Мы будем рады услышать ваши мысли по этому поводу в разделе комментариев ниже.
2. Лучшие результаты одинаковы для всех методов
Мы видим, что все реализации имеют одинаковый лучший результат — около 28 секунд. Независимо от того, каким образом мы пытались приблизиться, результаты были одинаковыми. Это не значит, что нам безразлично, какой метод использовать. Проверьте следующее понимание.
3. Параллельные потоки обрабатывают перегрузку потока лучше, чем другие реализации
Это более интересная часть. В этом тесте мы снова видим, что лучшие результаты для запуска 16 потоков получены при использовании параллельных потоков. Более того, в этой версии использование параллельных потоков было хорошим вызовом для всех вариаций номеров потоков.
4. Однопоточная производительность была в 4,2 раза хуже, чем лучший результат
Кроме того, преимущество использования параллелизма при выполнении вычислительно-интенсивных задач почти в 2 раза хуже, чем тест ввода-вывода с файловым вводом-выводом. Это имеет смысл, поскольку это тест с интенсивной загрузкой процессора, в отличие от предыдущего, в котором мы могли бы получить дополнительную выгоду от сокращения времени ожидания наших ядер в потоках, застрявших в IO.
Вывод
Я бы порекомендовал обратиться к источнику, чтобы узнать больше о том, когда использовать параллельные потоки, и применять осторожные суждения каждый раз, когда вы выполняете параллелизм в Java. Наилучшим путем будет запуск подобных тестов в промежуточной среде, в которой вы сможете лучше понять, с чем вы столкнулись. Факторы, о которых вы должны помнить, это, конечно, оборудование, на котором вы работаете (и оборудование, на котором вы тестируете), и общее количество потоков в вашем приложении. Это включает в себя общий пул Fork / Join и код, над которым работают другие разработчики в вашей команде. Поэтому постарайтесь держать их под контролем и получить полное представление о вашем приложении, прежде чем добавлять собственный параллелизм.
основа
Для запуска этого теста мы использовали экземпляр EC2 c3.2xlarge с 8 vCPU и 15 ГБ оперативной памяти. VCPU означает, что существует гиперпоточность, поэтому на самом деле у нас здесь 4 физических ядра, каждое из которых действует так, как если бы это было 2. Что касается планировщика ОС, у нас здесь 8 ядер. Чтобы попытаться сделать это как можно более честным, каждая реализация выполнялась 10 раз, и мы взяли среднее время выполнения от 2 до 9. Это 260 тестовых прогонов, фу! Еще одна важная вещь — это время обработки. Мы выбрали задачи, для обработки которых потребуется более 20 секунд, чтобы различия были легче обнаружить и меньше влиять на внешние факторы.
Что дальше?
Необработанные результаты доступны прямо здесь , а код находится на GitHub . Пожалуйста, не стесняйтесь возиться с этим и дайте нам знать, какие результаты вы получаете. Если у вас есть более интересные идеи или объяснения результатов, которые мы пропустили, мы будем рады их прочитать и добавить в пост.
| Ссылка: | Платформа Fork / Join против Parallel Streams и ExecutorService: Ultimate Fork / Join Benchmark от нашего партнера JCG Алекса Житницкого в блоге Takipi . |