Мне нравится видеть, что EclipseLink по-прежнему является центром инноваций в постоянстве Java, и они изо всех сил стараются своевременно принять последние новости. Работа в более консервативной отрасли в целом, главная новая функция, которую я ищу, — это многопрофильная аренда. Из слайдов вы можете догадаться, что что-то в этой области уже должно работать с последней версией EclipseLink 2.3.0.
Как будет выглядеть Multitenancy?
Давайте начнем смотреть на то, что Линда ДеМичель (Oracle) Линда ДеМичель анонсировала в последние годы на JavaOne (сравните блог-пост ), а также давайте посмотрим, что может предложить ранний черновик (PDF) спецификации JPA 2.1. Более легкая часть — ранний проект. Ни в одной строке не упоминается «Multitenan [t | cy]» в любом контексте. Таким образом, это, очевидно, еще предстоит сделать для дальнейших итераций. Чуть больше можно найти в Ключевой Стратегии JavaOne (Слайды 41, 42) и Технической Ключевой JavaOne (PDF) (Слайд 25). Общий подход Java EE 7 заключается в поддержке отдельных изолированных экземпляров одного и того же приложения для разных арендаторов. Отображение должно выполняться контейнером и каким-то образом быть доступным для приложений. Это все очень расплывчато до сегодняшнего дня, и единственные конкретные примеры кода, доступные на слайдах, ссылаются на некоторые очевидные связанные с JPA примеры с использованием двух аннотаций @Multitenant и @TenantDiscriminatorColumn. Хм. Вам это не знакомо?
Что сегодня возможно?
Оно делает! EclipseLink (по состоянию на 2.3.0 — Indigo) поддерживает совместно используемые таблицы мультитенантов, используя столбцы (столбцы) дискриминатора, что позволяет повторно использовать приложение для нескольких арендаторов и размещать все данные в одном месте. Все арендаторы используют одну и ту же схему, не зная друг о друге, и могут использовать типы объектов, не относящиеся к нескольким арендаторам, как обычно. Но следует учитывать тот факт, что это только один из возможных подходов к работе с несколькими арендаторами. Обычно это называют «выделенной базой данных», потому что все данные арендатора помещаются в одну базу данных! Основные принципы следующие:
— экземпляры приложения обрабатывают несколько арендаторов
— кэширование должно быть изолированным для каждого арендатора JPA
Вы можете посмотреть все детали на специальной вики-странице EclipseLink. Хотите провести тест-драйв? Давайте начнем. Предварительные условия как обычно (NetBeans, GlassFish, MySQL, сравните старые сообщения, если вам нужна дополнительная помощь.). Убедитесь, что у вас есть правильные зависимости EclipseLink (как минимум 2.3.0)! С помощью мастера создайте новый объект, настройте источник данных и файл persistence.xml и назовите его, например, «Клиент».
|
1
2
3
4
|
@Entitypublic class Customer implements Serializable {//...} |
Если вы запустите свое приложение, вы увидите, что EclipseLink создает нечто подобное в вашей базе данных.

Давайте сделаем это многопользовательский объект. Добавьте следующие аннотации:
|
1
2
3
4
5
6
|
@Entity@Multitenant@TenantDiscriminatorColumn(name = "companyId", contextProperty = "company-tenant.code")public class Customer implements Serializable {//...} |
Существует несколько вариантов использования того, как единица персистентности EclipseLink JPA может использоваться в приложении с типами сущностей @Multitenant. Поскольку разные клиенты будут иметь доступ только к своим строкам, уровень персистентности должен быть настроен так, чтобы объекты из разных арендаторов не попадали в один и тот же кеш. Если вы сравните подробные подходы (выделенный ПК, ПК на одного арендатора, PU на арендатора) более детально, вы увидите, что на сегодняшний день у вас есть два возможных варианта с управляемой контейнером инъекцией либо ПК, либо PU. Давайте сначала попробуем самое простое.
Выделенный блок персистентности
При таком использовании для каждого клиента определяется единица постоянства, и приложение / контейнер должны запрашивать правильный PersistenceContext или PersistenceUnit для своего клиента. Существует одна единица персистентности, и ничего не передается. Перейдите к приведенному выше примеру и добавьте следующее свойство в файл persistence.xml:
|
1
|
<property name="company-tenant.code" value="TENANT1" /> |
Попробуйте и сравните таблицы.

Как видите, теперь у вас есть столбец companyId. Если вы вставите некоторые данные, они всегда будут заполнены значением свойства, которое вы указали в файле persistence.xml. Используйте @PersistenceContext или @PersistenceUnit для доступа к вашим сущностям. Используя этот подход, вы получаете общий кеш, как обычно для вашего приложения.
 |
| @PersistenceContext с общим кэшем (Источник: S.Smith) |
Постоянный контекст на арендатора
Если вы не хотите иметь одного клиента для каждого приложения, вы можете решить, что в вашем приложении есть одно определение модуля персистентности в файле persistence.xml и общий блок персистентности (EntityManagerFactory и кэш). В этом случае контекст клиента должен быть указан для EntityManager во время выполнения. В этом случае у вас есть общий кеш, доступный для обычных типов сущностей, но типы @Multitenant должны быть защищены в кеше. Вы делаете это, указывая некоторые свойства:
|
1
2
3
4
5
6
|
@PersistenceUnitEntityManagerFactory emf;Map props = new HashMap();props.put("company-tenant.code", "TENANT2");props.put(PersistenceUnitProperties.MULTITENANT_SHARED_EMF, true);EntityManager em = emf.createEntityManager(props); |
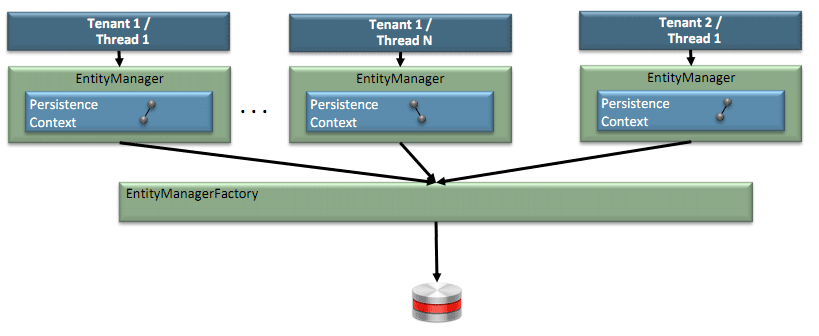 |
| Общий @PersistenceUnit на каждого палатника (Источник: S.Smith) |
Дискриминаторные подходы
Приведенные выше примеры работают с одним столбцом клиента дискриминатора. Вы можете добавить столбец дискриминатора в PK, указав атрибут primaryKey, например, так:
|
1
|
@TenantDiscriminatorColumn(name = "companyId", contextProperty = "company-tenant.code", primaryKey = true) |
Также возможно иметь несколько столбцов дискриминатора клиента, используя несколько таблиц, если вы делаете что-то вроде этого:
|
1
2
3
4
5
6
7
|
@Entity@SecondaryTable(name = "TENANTS")@Multitenant@TenantDiscriminatorColumns({ @TenantDiscriminatorColumn(name = "TENANT_ID", contextProperty = "company-tenant.id", length = 20, primaryKey = true), @TenantDiscriminatorColumn(name = "TENANT_CODE", contextProperty = "company-tenant.code", discriminatorType = DiscriminatorType.STRING, table = "TENANTS")}) |
Это приводит к вторичной таблице арендаторов.

Дополнительные вкусности
Как всегда, вы можете выполнить полную настройку только в своем файле persistence.xml. Для справки, пожалуйста, посмотрите на уже упомянутую вики-страницу. Последняя вещь представляет интерес. Вы также можете сопоставить столбец дискриминатора клиента с вашей сущностью. Вам просто нужно убедиться, что он не обновлен и не вставлен.
|
1
2
3
4
5
6
7
|
@Basic @Column(name = "TENANT_ID", insertable = false, updatable = false) private int tenantId; public int getTenantId() { return tenantId; } |
Посмотрев выходные данные отладки, вы можете увидеть, что происходит за кулисами:
ИНФОРМАЦИЯ: Получение EntityManager
ИНФОРМАЦИЯ: Вставка тестового клиента
FEIN: ВСТАВИТЬ В ЗАКАЗЧИКА (ID, TENANT_ID) ЗНАЧЕНИЯ (?,?)
bind => [1, 2]
FEIN: ВСТАВИТЬ В TENANTS (ID, TENANT_CODE) ЗНАЧЕНИЯ (?,?)
bind => [1, TENANT2]
FEIN: ВЫБЕРИТЕ t0.ID, t1.TENANT_CODE, t0.TENANT_ID, t1.ID ОТ КЛИЕНТА t0, Арендаторов t1 ГДЕ ((((t1.ID = t0.ID) И (t1.TENANT_CODE =?)) И (t0.TENANT_ID знак равно
bind => [TENANT2, 2]
Хотите узнать больше о вкусностях Java EE 7 и JPA 2.1? Следите за обновлениями на вики-странице статуса разработки для проекта EclipseLink JPA 2.1.
Ссылка: Sneak Peak на Java EE 7 — Мультитенантные примеры с EclipseLink от нашего партнера JCG