Лучшим подходом, чем версия с необработанным потоком, является основанная на пуле потоков версия, в которой соответствующий размер пула потоков определяется на основе системы, в которой выполняется задача — Количество процессоров / (1-коэффициент блокировки задачи). Книга Venkat Subramaniams содержит более подробную информацию:

Сначала я определил пользовательскую задачу для генерации части отчета, учитывая запрос части отчета, это реализовано как Callable :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
public class ReportPartRequestCallable implements Callable<ReportPart> { private final ReportRequestPart reportRequestPart; private final ReportPartGenerator reportPartGenerator; public ReportPartRequestCallable(ReportRequestPart reportRequestPart, ReportPartGenerator reportPartGenerator) { this.reportRequestPart = reportRequestPart; this.reportPartGenerator = reportPartGenerator; } @Override public ReportPart call() { return this.reportPartGenerator.generateReportPart(reportRequestPart); } } |
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
public class ExecutorsBasedReportGenerator implements ReportGenerator { private static final Logger logger = LoggerFactory.getLogger(ExecutorsBasedReportGenerator.class); private ReportPartGenerator reportPartGenerator; private ExecutorService executors = Executors.newFixedThreadPool(10); @Override public Report generateReport(ReportRequest reportRequest) { List<Callable<ReportPart>> tasks = new ArrayList<Callable<ReportPart>>(); List<ReportRequestPart> reportRequestParts = reportRequest.getRequestParts(); for (ReportRequestPart reportRequestPart : reportRequestParts) { tasks.add(new ReportPartRequestCallable(reportRequestPart, reportPartGenerator)); } List<Future<ReportPart>> responseForReportPartList; List<ReportPart> reportParts = new ArrayList<ReportPart>(); try { responseForReportPartList = executors.invokeAll(tasks); for (Future<ReportPart> reportPartFuture : responseForReportPartList) { reportParts.add(reportPartFuture.get()); } } catch (Exception e) { logger.error(e.getMessage(), e); throw new RuntimeException(e); } return new Report(reportParts); } ......} |
Здесь пул потоков создается с помощью вызова Executors.newFixedThreadPool (10) с размером пула 10, для каждой части запроса отчета генерируется вызываемая задача, которая передается в пул потоков с использованием абстракции ExecutorService.
|
1
|
responseForReportPartList = executors.invokeAll(tasks); |
этот вызов возвращает список фьючерсов, которые поддерживают метод get (), который является блокирующим вызовом для ответа, который будет доступен.
Это, безусловно, намного лучшая реализация по сравнению с исходной версией потока, количество потоков ограничено управляемым числом под нагрузкой.
Внедрение Spring на основе интеграции
Подход, который мне лично нравится больше всего, заключается в использовании Spring Integration , причина в том, что в Spring Integration я сосредотачиваюсь на компонентах, выполняющих различные задачи, и оставляю его на усмотрение Spring Integration, чтобы связать поток вместе, используя конфигурацию на основе xml или аннотаций. Здесь я буду использовать конфигурацию на основе XML:
Компоненты в моем случае:
1. Компонент для генерации части отчета, учитывая запрос части отчета, который я показал ранее .
2. Компонент для разделения запроса отчета на части запроса отчета:
|
1
2
3
4
5
6
|
public class DefaultReportRequestSplitter implements ReportRequestSplitter{ @Override public List<ReportRequestPart> split(ReportRequest reportRequest) { return reportRequest.getRequestParts(); }} |
3. Компонент для сборки / объединения частей отчета в единый отчет:
|
1
2
3
4
5
6
7
8
|
public class DefaultReportAggregator implements ReportAggregator{ @Override public Report aggregate(List<ReportPart> reportParts) { return new Report(reportParts); }} |
И это весь код Java, который требуется для Spring Integration, остальная часть является проводной — здесь я использовал файл конфигурации Spring:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
<?xml version='1.0' encoding='UTF-8'?><beans .... <int:channel id='report.partsChannel'/> <int:channel id='report.reportChannel'/> <int:channel id='report.partReportChannel'> <int:queue capacity='50'/> </int:channel> <int:channel id='report.joinPartsChannel'/> <int:splitter id='splitter' ref='reportsPartSplitter' method='split' input-channel='report.partsChannel' output-channel='report.partReportChannel'/> <task:executor id='reportPartGeneratorExecutor' pool-size='10' queue-capacity='50' /> <int:service-activator id='reportsPartServiceActivator' ref='reportPartReportGenerator' method='generateReportPart' input-channel='report.partReportChannel' output-channel='report.joinPartsChannel'> <int:poller task-executor='reportPartGeneratorExecutor' fixed-delay='500'> </int:poller> </int:service-activator> <int:aggregator ref='reportAggregator' method='aggregate' input-channel='report.joinPartsChannel' output-channel='report.reportChannel' ></int:aggregator> <int:gateway id='reportGeneratorGateway' service-interface='org.bk.sisample.springintegration.ReportGeneratorGateway' default-request-channel='report.partsChannel' default-reply-channel='report.reportChannel'/> <bean name='reportsPartSplitter' class='org.bk.sisample.springintegration.processors.DefaultReportRequestSplitter'></bean> <bean name='reportPartReportGenerator' class='org.bk.sisample.processors.DummyReportPartGenerator'/> <bean name='reportAggregator' class='org.bk.sisample.springintegration.processors.DefaultReportAggregator'/> <bean name='reportGenerator' class='org.bk.sisample.springintegration.SpringIntegrationBasedReportGenerator'/></beans> |
Spring Source Tool Suite предоставляет отличный способ визуализации этого файла:

это полностью соответствует моему первоначальному представлению о потоке пользователя:
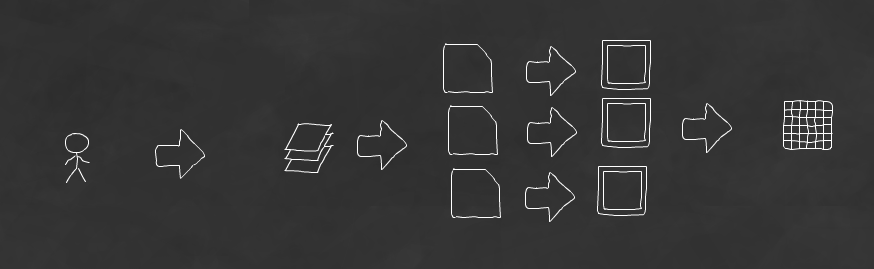
В версии кода Spring Integration я определил различные компоненты для обработки различных частей потока:
1. Разделитель для преобразования запроса отчета в части запроса отчета:
|
1
2
|
<int:splitter id='splitter' ref='reportsPartSplitter' method='split' input-channel='report.partsChannel' output-channel='report.partReportChannel'/> |
2. Компонент активатора службы для создания части отчета из запроса части отчета:
|
1
2
3
4
5
|
<int:service-activator id='reportsPartServiceActivator' ref='reportPartReportGenerator' method='generateReportPart' input-channel='report.partReportChannel' output-channel='report.joinPartsChannel'> <int:poller task-executor='reportPartGeneratorExecutor' fixed-delay='500'> </int:poller> </int:service-activator> |
3. Агрегатор для объединения частей отчета обратно в отчет, и он достаточно умен, чтобы соответствующим образом соотнести исходные запросы отчета без какого-либо явного кодирования:
|
1
2
|
<int:aggregator ref='reportAggregator' method='aggregate' input-channel='report.joinPartsChannel' output-channel='report.reportChannel' ></int:aggregator> |
Что интересно в этом коде, так это то, что, как и в примере на основе исполнителей, количество потоков, обслуживающих каждый из этих компонентов, полностью настраивается с помощью файла XML, с помощью соответствующих каналов для соединения различных компонентов и с помощью исполнителей задач с размер пула потоков, установленный в качестве атрибута исполнителя.
В этом коде я определил канал очереди, куда входят части запроса отчета:
|
1
2
3
|
<int:channel id='report.partReportChannel'> <int:queue capacity='50'/> </int:channel> |
и обслуживается компонентом-активатором службы с использованием исполнителя задач с пулом потоков размером 10 и емкостью 50:
|
1
2
3
4
5
6
7
|
<task:executor id='reportPartGeneratorExecutor' pool-size='10' queue-capacity='50' /> <int:service-activator id='reportsPartServiceActivator' ref='reportPartReportGenerator' method='generateReportPart' input-channel='report.partReportChannel' output-channel='report.joinPartsChannel'> <int:poller task-executor='reportPartGeneratorExecutor' fixed-delay='500'> </int:poller> </int:service-activator> |
Все это через конфигурацию!
Вся база кода для этого образца доступна по адресу github: https://github.com/bijukunjummen/si-sample
Ссылка: Параллелизм — Исполнители и Spring Integration от нашего партнера JCG Биджу Кунджуммен в блоге all and sundry.