В этой статье я расскажу о наиболее фундаментальной технике параллельного программирования, известной как барьеры памяти или ограждения, которые делают состояние памяти внутри процессора видимым для других процессоров.
Процессоры используют много методов, чтобы попытаться учесть тот факт, что производительность исполнительного модуля процессора значительно опережает производительность основной памяти. В моей статье « Комбинирование записи » я затронул только один из этих методов. Наиболее распространенный метод, используемый ЦП для сокрытия задержки памяти, состоит в том, чтобы направлять команды, а затем тратить значительные усилия и ресурсы на попытки переупорядочить эти конвейеры, чтобы минимизировать задержки, связанные с потерями в кеше.
Когда программа выполняется, не имеет значения, если ее инструкции переупорядочены при условии достижения того же конечного результата. Например, в цикле не имеет значения, когда счетчик цикла обновляется, если никакая операция в цикле не использует его. Компилятор и ЦП могут свободно переупорядочивать инструкции, чтобы наилучшим образом использовать ЦП, при условии, что он обновляется к моменту начала следующей итерации. Также во время выполнения цикла эта переменная может храниться в регистре и никогда не помещаться в кэш или основную память, поэтому она никогда не будет видна другому ЦП.
Ядра процессора содержат несколько исполнительных блоков. Например, современный процессор Intel содержит 6 исполнительных блоков, которые могут выполнять комбинацию арифметической, условной логики и манипулирования памятью. Каждый исполнительный блок может выполнять некоторую комбинацию этих задач. Эти исполнительные блоки работают параллельно, что позволяет выполнять инструкции параллельно. Это вводит другой уровень недетерминированности в программный порядок, если он наблюдался от другого ЦП.
Наконец, когда происходит потеря кэша, современный ЦП может сделать предположение о результатах загрузки памяти и продолжить выполнение на основе этого предположения, пока загрузка не вернет фактические данные.
При условии, что «программный порядок» сохранен, процессор и компилятор могут делать все, что сочтут целесообразным, для повышения производительности.
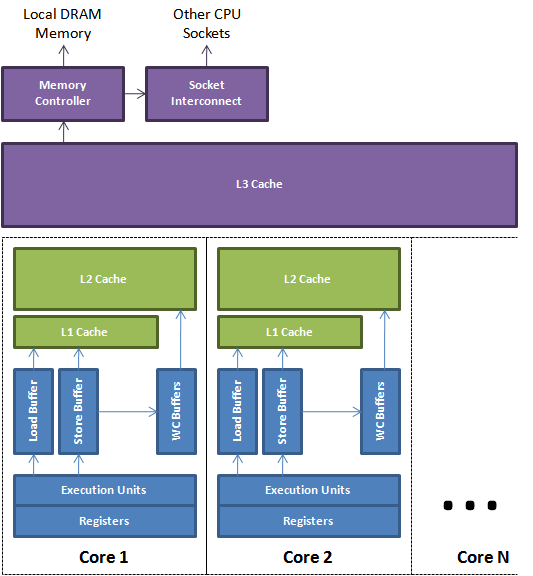 |
| Фигура 1. |
Загрузки и хранилища в кэш-памяти и основной памяти буферизуются и переупорядочиваются с использованием буферов загрузки, хранения и записи. Эти буферы являются ассоциативными очередями, которые обеспечивают быстрый поиск. Этот поиск необходим, когда при более поздней загрузке необходимо прочитать значение предыдущего хранилища, которое еще не достигло кэша. На рисунке 1 выше показан упрощенный вид современного многоядерного процессора. Он показывает, как исполнительные блоки могут использовать локальные регистры и буферы для управления памятью во время ее передачи назад и вперед из подсистемы кэша.
В многопоточной среде необходимо использовать методы для своевременного отображения результатов программы. Я не буду рассматривать когерентность кэша в этой статье. Просто предположим, что после того, как память была помещена в кэш, будет создан протокол сообщений, чтобы гарантировать, что все кэши согласованы для любых общих данных. Методы, позволяющие сделать память видимой из ядра процессора, известны как барьеры или ограждения памяти.
Барьеры памяти обеспечивают два свойства. Во-первых, они сохраняют видимый извне порядок программ, гарантируя, что все команды с обеих сторон барьера отображаются в правильном порядке программ при наблюдении от другого ЦП, и, во-вторых, они делают память видимой, обеспечивая передачу данных в подсистему кэша.
Барьеры памяти — сложный предмет. Они реализованы очень по-разному в архитектуре процессора. На одном конце спектра находится относительно сильная модель памяти на процессорах Intel, которая проще, чем, скажем, слабая и сложная модель памяти на DEC Alpha с ее разделенными кэшами в дополнение к слоям кэша. Поскольку процессоры x86 являются наиболее распространенными для многопоточного программирования, я постараюсь упростить до этого уровня.
Магазин Барьер
Магазин Барьер, ООО”Инструкция на x86, заставляет все инструкции хранилища до того, как барьер произойдет до барьера, и сбрасывает буферы хранилища в кэш для процессора, на котором они выпущены. Это сделает состояние программы видимым для других процессоров, чтобы они могли действовать в случае необходимости. Хорошим примером этого в действии является следующий упрощенный код из BatchEventProcessor в Disruptor. Когда последовательность обновляется, другие потребители и производители знают, как далеко продвинулся этот потребитель, и таким образом могут предпринять соответствующие действия. Все предыдущие обновления памяти, которые произошли до барьера, теперь видны.
private volatile long sequence = RingBuffer.INITIAL_CURSOR_VALUE;
// from inside the run() method
T event = null;
long nextSequence = sequence + 1L;
while (running)
{
try
{
final long availableSequence =
dependencyBarrier.waitFor(nextSequence);
while (nextSequence <= availableSequence)
{
event = dependencyBarrier.getEvent(nextSequence);
eventHandler.onEvent(event, nextSequence == availableSequence);
nextSequence++;
}
sequence = event.getSequence();
// store barrier inserted here !!!
}
catch (final Exception ex)
{
exceptionHandler.handle(ex, event);
sequence = event.getSequence();
// store barrier inserted here !!!
nextSequence = event.getSequence() + 1L;
}
}
Барьер загрузки. Барьер
загрузки, инструкция « lfence » на x86, заставляет все инструкции загрузки после барьера следовать за барьером, а затем ждать загрузки буфера загрузки для этого ЦП. Это делает состояние программы доступным для других процессоров, видимых этому процессору, прежде чем делать дальнейший прогресс. Хороший пример этого — когда упомянутая выше последовательность BatchEventProcessor читается производителями или потребителями в соответствующих барьерах Разрушителя.
Полный барьер
Полный барьер, инструкция mfence на x86, представляет собой совокупность барьеров нагрузки и хранилища , возникающих на процессоре.
Модель памяти Java
В модели памяти Java летучегополе имеет барьер магазина, вставленный после записи в него, и барьер загрузки, вставленный перед чтением этого. Квалифицированные конечные поля класса имеют барьер хранилища, вставленный после их инициализации, чтобы гарантировать, что эти поля будут видимы, как только конструктор завершит работу, когда будет доступна ссылка на объект.
Атомарные инструкции и программные блокировки
Атомарные инструкции, такие как инструкции « блокировать …» в x86, фактически являются полным барьером, поскольку они блокируют подсистему памяти для выполнения операции и имеют гарантированный общий порядок даже между процессорами. Программные блокировки обычно используют барьеры памяти или атомарные инструкции для достижения видимости и сохранения порядка программы.
Влияние производительности на барьеры памяти
Барьеры памяти не позволяют ЦП выполнять множество методов, чтобы скрыть задержку памяти, поэтому они требуют значительных затрат производительности, что необходимо учитывать. Для достижения максимальной производительности лучше всего смоделировать проблему, чтобы процессор мог выполнять единицы работы, а затем на границах этих рабочих единиц возникли все необходимые барьеры памяти. Такой подход позволяет процессору оптимизировать единицы работы без ограничений. Преимущество состоит в группировании необходимых барьеров памяти, так как буферы, очищенные после первого, будут менее дорогостоящими, потому что не будет никакой работы по их заполнению.
От http://mechanical-sympathy.blogspot.com/2011/07/memory-barriersfences.html