Сегодня я представляю вам вторую часть моего предыдущего поста о пакетной обработке Java EE 7 и World of Warcraft — часть 1 . В этом посте мы увидим, как агрегировать и извлекать метрики из данных, которые мы получили в первой части .

резюмировать
Цель пакета — загрузить данные аукционного дома World of Warcraft , обработать аукционы и извлечь метрики. Эти метрики будут строить историю эволюции цен Аукционных предметов во времени. В первой части мы уже загрузили и вставили данные в базу данных.
Приложение
Процесс работы
После добавления необработанных данных в базу данных, мы собираемся добавить еще один шаг с обработкой стиля Chunk. В блоке мы собираемся прочитать агрегированные данные, а затем вставить их в другую таблицу в базе данных для быстрого доступа. Это делается в process-job.xml :
Процесс-job.xml
|
1
2
3
4
5
6
7
|
<step id="importStatistics"> <chunk item-count="100"> <reader ref="processedAuctionsReader"/> <processor ref="processedAuctionsProcessor"/> <writer ref="processedAuctionsWriter"/> </chunk></step> |
Блок читает данные по одному элементу за раз и создает фрагменты, которые будут записаны в транзакции. Один элемент считывается из ItemReader , передается ItemProcessor и агрегируется. Как только количество прочитанных элементов становится равным интервалу фиксации, весь блок записывается с помощью ItemWriter , а затем транзакция ItemWriter .
ProcessedAuctionsReader
В читателе мы собираемся выбирать и объединять метрики, используя функции базы данных.
ProcessedAuctionsReader.java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
@Namedpublic class ProcessedAuctionsReader extends AbstractAuctionFileProcess implements ItemReader { @Resource(name = "java:comp/DefaultDataSource") protected DataSource dataSource; private PreparedStatement preparedStatement; private ResultSet resultSet; @Override public void open(Serializable checkpoint) throws Exception { Connection connection = dataSource.getConnection(); preparedStatement = connection.prepareStatement( "SELECT" + " itemid as itemId," + " sum(quantity)," + " sum(bid)," + " sum(buyout)," + " min(bid / quantity)," + " min(buyout / quantity)," + " max(bid / quantity)," + " max(buyout / quantity)" + " FROM auction" + " WHERE auctionfile_id = " + getContext().getFileToProcess().getId() + " GROUP BY itemid" + " ORDER BY 1", ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY, ResultSet.HOLD_CURSORS_OVER_COMMIT ); // Weird bug here. Check https://java.net/bugzilla/show_bug.cgi?id=5315 //preparedStatement.setLong(1, getContext().getFileToProcess().getId()); resultSet = preparedStatement.executeQuery(); } @Override public void close() throws Exception { DbUtils.closeQuietly(resultSet); DbUtils.closeQuietly(preparedStatement); } @Override public Object readItem() throws Exception { return resultSet.next() ? resultSet : null; } @Override public Serializable checkpointInfo() throws Exception { return null; } |
В этом примере мы получаем лучшие результаты производительности, используя простой JDBC с простым прокручиваемым набором результатов. Таким образом, выполняется только один запрос и результаты извлекаются по мере необходимости в readItem . Возможно, вы захотите изучить другие альтернативы.
Обычный JPA не имеет прокручиваемого результата в стандартах, поэтому вам нужно разбить результаты на страницы. Это приведет к нескольким запросам, которые замедляют чтение. Другой вариант — использовать новый API Java 8 Streams для выполнения операций агрегирования. Операции выполняются быстро, но вам нужно выбрать весь набор данных из базы данных в потоки. В конечном итоге это убьет вашу производительность.
Я попробовал оба подхода и получил лучшие результаты, используя возможности агрегации баз данных. Я не говорю, что это всегда лучший вариант, но в данном конкретном случае это был лучший вариант.
Во время реализации я также обнаружил ошибку в пакетном режиме. Вы можете проверить это здесь . Исключение выдается при установке параметров в PreparedStatement. Обходной путь должен был ввести параметры непосредственно в запрос SQL. Гадкий, я знаю …
ProcessedAuctionsProcessor
В процессоре давайте сохраним все агрегированные значения в объекте-держателе для хранения в базе данных.
ProcessedAuctionsProcessor.java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
@Namedpublic class ProcessedAuctionsProcessor extends AbstractAuctionFileProcess implements ItemProcessor { @Override @SuppressWarnings("unchecked") public Object processItem(Object item) throws Exception { ResultSet resultSet = (ResultSet) item; AuctionItemStatistics auctionItemStatistics = new AuctionItemStatistics(); auctionItemStatistics.setItemId(resultSet.getInt(1)); auctionItemStatistics.setQuantity(resultSet.getLong(2)); auctionItemStatistics.setBid(resultSet.getLong(3)); auctionItemStatistics.setBuyout(resultSet.getLong(4)); auctionItemStatistics.setMinBid(resultSet.getLong(5)); auctionItemStatistics.setMinBuyout(resultSet.getLong(6)); auctionItemStatistics.setMaxBid(resultSet.getLong(7)); auctionItemStatistics.setMaxBuyout(resultSet.getLong(8)); auctionItemStatistics.setTimestamp(getContext().getFileToProcess().getLastModified()); auctionItemStatistics.setAvgBid( (double) (auctionItemStatistics.getBid() / auctionItemStatistics.getQuantity())); auctionItemStatistics.setAvgBuyout( (double) (auctionItemStatistics.getBuyout() / auctionItemStatistics.getQuantity())); auctionItemStatistics.setRealm(getContext().getRealm()); return auctionItemStatistics; }} |
Поскольку метрики записывают точный моментальный снимок данных во времени, вычисление необходимо выполнить только один раз. Вот почему мы сохраняем агрегированные показатели. Они никогда не изменятся, и мы можем легко проверить историю.
Если вы знаете, что ваши исходные данные являются неизменными, и вам нужно выполнять над ними операции, я рекомендую вам сохранить результат где-нибудь. Это сэкономит ваше время. Конечно, вам нужно балансировать, если в будущем к этим данным будет обращаться много раз. Если нет, возможно, вам не нужно проходить через проблему сохранения данных.
ProcessedAuctionsWriter
Наконец, нам просто нужно записать данные в базу данных:
ProcessedAuctionsWriter.java
|
01
02
03
04
05
06
07
08
09
10
11
12
|
@Namedpublic class ProcessedAuctionsWriter extends AbstractItemWriter { @PersistenceContext protected EntityManager em; @Override @SuppressWarnings("unchecked") public void writeItems(List items) throws Exception { List<AuctionItemStatistics> statistis = (List<AuctionItemStatistics>) items; statistis.forEach(em::persist); }} |
метрика
Теперь, чтобы сделать что-то полезное с данными, мы собираемся предоставить конечную точку REST для выполнения запросов по вычисленным метрикам. Вот как:
WowBusinessBean.java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
@Override @GET @Path("items") public List<AuctionItemStatistics> findAuctionItemStatisticsByRealmAndItem(@QueryParam("realmId") Long realmId, @QueryParam("itemId") Integer itemId) { Realm realm = (Realm) em.createNamedQuery("Realm.findRealmsWithConnectionsById") .setParameter("id", realmId) .getSingleResult(); // Workaround for https://bugs.eclipse.org/bugs/show_bug.cgi?id=433075 if using EclipseLink List<Realm> connectedRealms = new ArrayList<>(); connectedRealms.addAll(realm.getConnectedRealms()); List<Long> ids = connectedRealms.stream().map(Realm::getId).collect(Collectors.toList()); ids.add(realmId); return em.createNamedQuery("AuctionItemStatistics.findByRealmsAndItem") .setParameter("realmIds", ids) .setParameter("itemId", itemId) .getResultList(); } |
Если вы помните некоторые детали поста части 1 , серверы World of Warcraft называются Realms . Эти области могут быть связаны друг с другом и совместно использовать один и тот же Аукционный Дом . Для этого у нас также есть информация о том, как сферы связаны друг с другом. Это важно, потому что мы можем искать предмет аукциона во всех связанных сферах. Остальная часть логики — это простые запросы для вывода данных.
Во время разработки я также обнаружил ошибку в Eclipse Link (если вы работаете в Glassfish) и Java 8. По-видимому, базовая коллекция, возвращаемая Eclipse Link, имеет число элементов, равное 0. Это не очень хорошо работает с Streams, если вы попытаться встроить запрос запроса плюс операцию потока. Поток будет думать, что он пуст и результаты не возвращаются. Вы можете прочитать немного больше об этом здесь .
Интерфейс
Я также разработал небольшой интерфейс, используя Angular и Google Charts для отображения метрик. Посмотри:
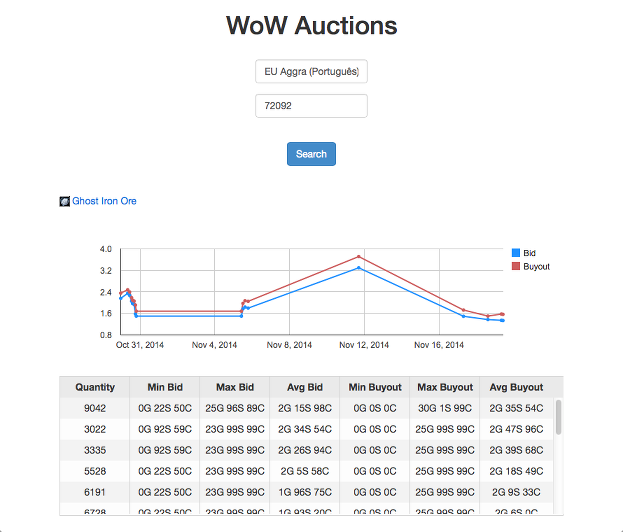
Здесь я ищу в Царстве под названием «Aggra (Português)» и идентификатор предмета аукциона 72092, который соответствует Призрачной железной руде . Как вы можете видеть, мы можем проверить количество для продажи, цену покупки и выкупа и колебания цены во времени. Аккуратные? Я могу написать еще один пост о создании веб-интерфейса в будущем.
Ресурсы
Вы можете клонировать полную рабочую копию из моего репозитория github и развернуть ее в Wildfly или Glassfish . Вы можете найти там инструкции по его развертыванию: Аукционы World of Warcraft
Проверьте также примеры проектов Java EE с большим количеством пакетных примеров, полностью документированных.
| Ссылка: | Java EE 7 Batch Processing и World of Warcraft — часть 2 от нашего партнера по JCG Роберто Кортеса в блоге |