Эта серия статей об операторе искры Kubernetes от Radanalytics.io на
Происхождение OpenShift . Это оператор с открытым исходным кодом для управления
Apache Spark кластеры и приложения.
Чтобы развернуть оператор в OpenShift Origin, в первый раз вам необходимо клонировать для него GitHub-репозиторий:
|
1
|
git clone https://github.com/radanalyticsio/spark-operator.git |
Затем войдите в кластер с помощью командной строки OpenShift
ок :
|
1
|
oc login -u <username>:<password> |
Предполагая, что, как и в средах OpenShift Origin, с которыми я и мои команды работали, у разработчиков нет прав на создание CRD, вам нужно использовать Config Maps, поэтому вам нужно создать оператора с помощью
Файл operator-com.yaml, предоставленный в клонированном репо:
|
1
|
oc apply -f manifest/operator-cm.yaml |
Вывод команды выше должен быть следующим:
|
1
|
serviceaccount/spark-operator created<br>role.rbac.authorization.k8s.io/edit-resources created<br>rolebinding.rbac.authorization.k8s.io/spark-operator-edit-resources created<br>deployment.apps/spark-operator created |
После того, как оператор был успешно создан, вы можете попытаться создать свой первый кластер. Выберите конкретный проект, который вы хотите использовать:
|
1
|
oc project <project_name> |
а затем создайте небольшой кластер Spark (1 мастер и 2 рабочих), используя файл примера для ConfigMaps, доступный в клонированном репо:
|
1
|
oc apply -f examples/cluster-cm.yaml |
Вот содержимое этого файла:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
apiVersion: v1kind: ConfigMapmetadata: name: my-spark-cluster labels: radanalytics.io/kind: SparkClusterdata: config: |- worker: instances: "2" master: instances: "1" |
Вывод вышеуказанной команды:
|
1
|
configmap/my-spark-cluster created |
После успешного создания кластера, глядя на веб-интерфейс OpenShift, ситуация должна выглядеть следующим образом:
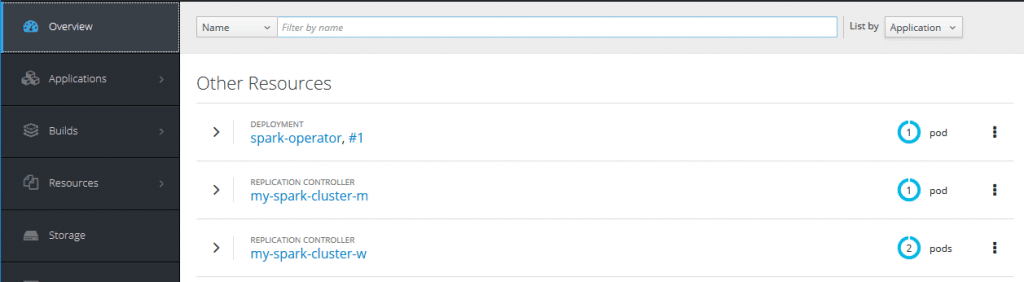
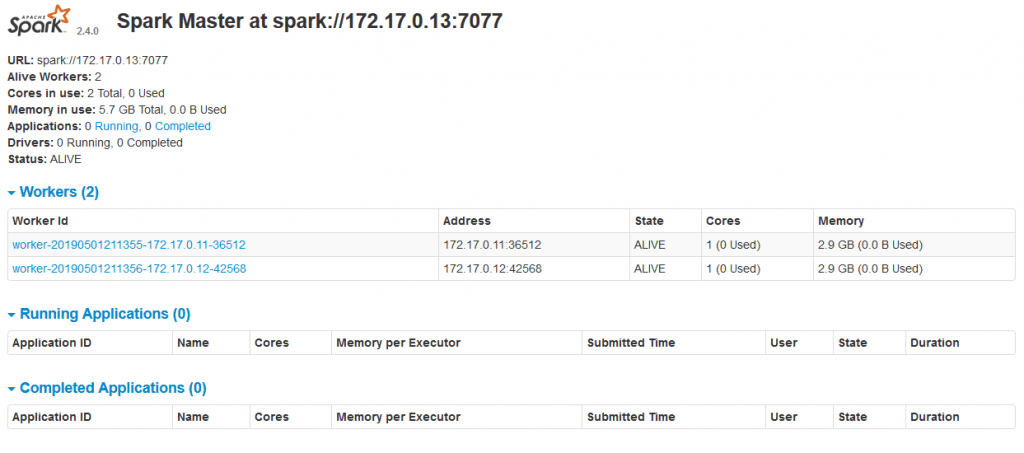
Чтобы получить доступ к веб-интерфейсу Spark, вам необходимо создать для него маршрут. Это можно сделать с помощью пользовательского интерфейса OpenShift Origin, выбрав службу Spark и нажав
ссылка на маршрут . Как только маршрут будет создан, веб-интерфейс Spark для мастера (см. Рисунок ниже) и рабочих будет доступен из-за пределов OpenShift.
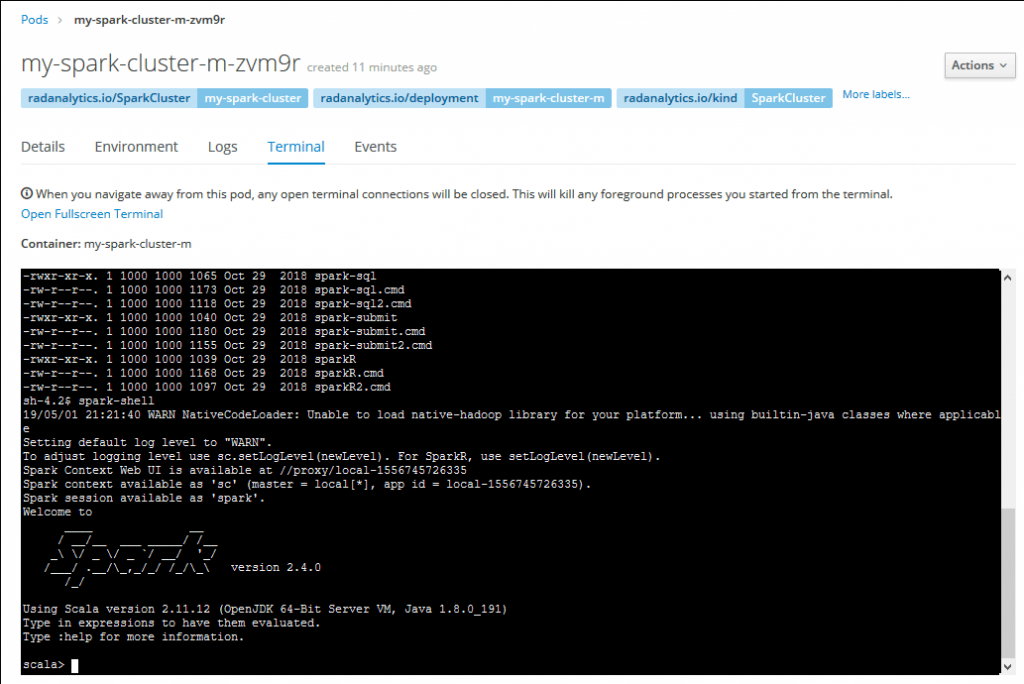
Теперь вы можете использовать кластер Spark. Вы можете начать тестирование, войдя в консоль главного модуля, запустив там оболочку Scala Spark и выполнив некоторый код:
Во второй части этой серии мы собираемся изучить детали реализации и конфигурации оператора Spark, прежде чем переходить к управлению приложениями Spark.
|
Смотрите оригинальную статью здесь: Оператор искры Kubernetes в OpenShift Origin (часть 1) Мнения, высказанные участниками Java Code Geeks, являются их собственными. |